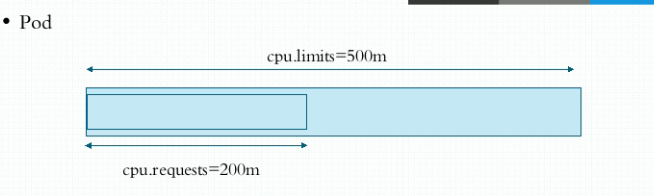
容器的资源需求和资源限制
- requests:资源需求,最低保障, 保证被调度的节点上至少有的资源配额
- limits:资源限额,硬限制, 容器可以分配到的最大资源配额
- limits一般大于等于requests
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
labels:
app: myapp
tier: fronted
spec:
containers:
- name: myapp
image: ikubernetes/stress-ng #压测的镜像
command: ["/usr/bin/stress-ng", "-m 1", "-c 1", "--metrics-brief"]
resources: #定义资源限额等
requests:
cpu: "200m"
memory: "128Mi"
limits:
cpu: "500m" #1颗cpu=1000m
memory: "200Mi"
kubectl exec pod-demo -- top
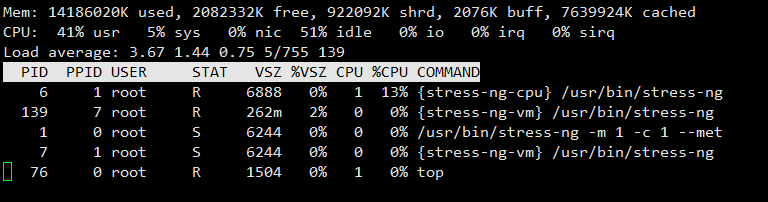
这是一个CPU为4核的节点, 分配给容器500m的CPU, 也就是0.125个CPU, 所以看到的进程CPU占用率约为13%
QoS Classes分类
Guaranteed
确保类型,此类pod具有最高优先级
如果Pod中所有Container的所有Resource的limit和request都相等且不为0,则这个Pod的QoS Class就是Guaranteed。
注意,如果一个容器只指明了limit,而未指明request,则表明request的值等于limit的值。
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
labels:
app: myapp
tier: fronted
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
resources: #定义资源限额等
requests:
cpu: "200m"
memory: "200Mi"
limits:
cpu: "200m" #1颗cpu=1000m
memory: "200Mi"
[root@master scheduler]# kubectl describe pods pod-demo
Name: pod-demo
Namespace: default
Priority: 0
。。。。。。
。。。。。。
QoS Class: Guaranteed #此时已经是Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11s default-scheduler Successfully assigned default/pod-demo to node3
Normal Pulled 9s kubelet, node3 Container image "ikubernetes/myapp:v1" already present on machine
Normal Created 8s kubelet, node3 Created container myapp
Normal Started 8s kubelet, node3 Started container myapp
Burstable
至少有一个容器设置CPU或内存资源的requests属性,此类pod具有中等优先级
Best-Effort
如果Pod中所有容器的所有Resource的request和limit都没有赋值,则这个Pod的QoS Class就是Best-Effort,优先级最低
containers:
name: foo
resources:
name: bar
resources:
kubernetes之node资源紧缺时pod驱逐机制
Qos Class优先级排名
Guaranteed > Burstable > Best-Effort
当节点资源紧缺时,优先级低的pod会最先被节点驱逐,Burstable类型下,已占用量与需求量比值大的先被驱逐(已占用500M的request512M的pod1和已占用512M的request1024M的pod2,先驱逐pod1)
可压缩资源与不可压缩资源
Pod 使用的资源最重要的是 CPU、内存和磁盘 IO,这些资源可以被分为可压缩资源(CPU)和不可压缩资源(内存,磁盘 IO)。
-
可压缩资源
(CPU)不会导致pod被驱逐因为当 Pod 的 CPU 使用量很多时,系统可以通过重新分配权重来限制 Pod 的 CPU 使用
-
不可压缩资源
(内存)则会导致pod被驱逐于不可压缩资源来说,如果资源不足,也就无法继续申请资源(内存用完就是用完了),此时 Kubernetes 会从该节点上驱逐一定数量的 Pod,以保证该节点上有充足的资源。
存储资源不足
下面是 kubelet 默认的关于节点存储的驱逐触发条件:
- nodefs.available<10%(容器 volume 使用的文件系统的可用空间,包括文件系统剩余大小和 inode 数量)
- imagefs.available<15%(容器镜像使用的文件系统的可用空间,包括文件系统剩余大小和 inode 数量)
当 imagefs 使用量达到阈值时,kubelet 会尝试删除不使用的镜像来清理磁盘空间。
当 nodefs 使用量达到阈值时,kubelet 就会拒绝在该节点上运行新 Pod,并向 API Server 注册一个 DiskPressure condition。然后 kubelet 会尝试删除死亡的 Pod 和容器来回收磁盘空间,如果此时 nodefs 使用量仍然没有低于阈值,kubelet 就会开始驱逐 Pod。kubelet 驱逐 Pod 的过程中不会参考 Pod 的 QoS,只是根据 Pod 的 nodefs 使用量来进行排名,并选取使用量最多的 Pod 进行驱逐。所以即使 QoS 等级为 Guaranteed 的 Pod 在这个阶段也有可能被驱逐(例如 nodefs 使用量最大)。如果驱逐的是 Daemonset,kubelet 会阻止该 Pod 重启,直到 nodefs 可用量超过阈值。
如果一个 Pod 中有多个容器,kubelet 会根据 Pod 中所有容器的 nodefs 使用量之和来进行排名。即所有容器的
container_fs_usage_bytes指标值之和。
举例
| Pod Name | Pod QoS | nodefs usage |
|---|---|---|
| A | Best Effort | 800M |
| B | Guaranteed | 1.3G |
| C | Burstable | 1.2G |
| D | Burstable | 700M |
| E | Best Effort | 500M |
| F | Guaranteed | 1G |
当 nodefs 的使用量超过阈值时,kubelet 会根据 Pod 的 nodefs 使用量来对 Pod 进行排名,首先驱逐使用量最多的 Pod。排名如下图所示:
| Pod Name | Pod QoS | nodefs usage |
|---|---|---|
| B | Guaranteed | 1.3G |
| C | Burstable | 1.2G |
| F | Guaranteed | 1G |
| A | Best Effort | 800M |
| D | Burstable | 700M |
| E | Best Effort | 500M |
内存资源不足
下面是 kubelet 默认的关于节点内存资源的驱逐触发条件:
- memory.available<100Mi
当内存使用量超过阈值时,kubelet 就会向 API Server 注册一个 MemoryPressure condition,此时 kubelet 不会接受新的 QoS 等级为 Best Effort 的 Pod 在该节点上运行,并按照以下顺序来驱逐 Pod:
- Pod 的内存使用量是否超过了
request指定的值 - 根据 priority 排序,优先级低的 Pod 最先被驱逐
- 比较它们的内存使用量与
request指定的值之差。
按照这个顺序,可以确保 QoS 等级为 Guaranteed 的 Pod 不会在 QoS 等级为 Best Effort 的 Pod 之前被驱逐,但不能保证它不会在 QoS 等级为 Burstable 的 Pod 之前被驱逐。
如果一个 Pod 中有多个容器,kubelet 会根据 Pod 中所有容器相对于 request 的内存使用量与之和来进行排名。即所有容器的 (
container_memory_usage_bytes指标值与container_resource_requests_memory_bytes指标值的差)之和。
举例
| Pod Name | Pod QoS | Memory requested | Memory limits | Memory usage |
|---|---|---|---|---|
| A | Best Effort | 0 | 0 | 700M |
| B | Guaranteed | 2Gi | 2Gi | 1.9G |
| C | Burstable | 1Gi | 2Gi | 1.8G |
| D | Burstable | 1Gi | 2Gi | 800M |
| E | Best Effort | 0 | 0 | 300M |
| F | Guaranteed | 2Gi | 2Gi | 1G |
当节点的内存使用量超过阈值时,kubelet 会根据 Pod 相对于 request 的内存使用量来对 Pod 进行排名。排名如下所示:
| Pod Name | Pod QoS | Memory requested | Memory limits | Memory usage | 内存相对使用量 |
|---|---|---|---|---|---|
| C | Burstable | 1Gi | 2Gi | 1.8G | 800M |
| A | Best Effort | 0 | 0 | 700M | 700M |
| E | Best Effort | 0 | 0 | 300M | 300M |
| B | Guaranteed | 2Gi | 2Gi | 1.9G | -100M |
| D | Burstable | 1Gi | 2Gi | 800M | -200M |
| F | Guaranteed | 2Gi | 2Gi | 1G | -1G |
当内存资源不足时,kubelet 在驱逐 Pod 时只会考虑 requests 和 Pod 的内存使用量,不会考虑 limits。
Node OOM (Out Of Memory)
因为 kubelet 默认每 10 秒抓取一次 cAdvisor 的监控数据,所以有可能在 kubelet 驱逐 Pod 回收内存之前发生内存使用量激增的情况,这时就有可能触发内核 OOM killer。这时删除容器的权利就由kubelet 转交到内核 OOM killer 手里,但 kubelet 仍然会起到一定的决定作用,它会根据 Pod 的 QoS 来设置其 oom_score_adj 值:
| QoS | oom_score_adj |
|---|---|
| Guaranteed | -998 |
| Burstable | min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
| pod-infra-container | -998 |
| kubelet, docker daemon, systemd service | -999 |
如果该节点在 kubelet 通过驱逐 Pod 回收内存之前触发了 OOM 事件,OOM killer 就会采取行动来降低系统的压力,它会根据下面的公式来计算 oom_score 的值:
容器使用的内存占系统内存的百分比 + oom_score_adj = oom_score>
OOM killer 会杀掉 oom_score_adj 值最高的容器,如果有多个容器的 oom_score_adj 值相同,就会杀掉内存使用量最多的容器(其实是因为内存使用量最多的容器的 oom_score 值最高)。关于 OOM 的更多内容请参考:Kubernetes 内存资源限制实战。
假设某节点运行着 4 个 Pod,且每个 Pod 中只有一个容器。每个 QoS 类型为 Burstable 的 Pod 配置的内存 requests 是 4Gi,节点的内存大小为 30Gi。每个 Pod 的 oom_score_adj 值如下所示:
| Pod Name | Pod QoS | oom_score_adj |
|---|---|---|
| A | Best Effort | 1000 |
| B | Guaranteed | -998 |
| C | Burstable | 867(根据上面的公式计算) |
| D | Best Effort | 1000 |
当调用 OOM killer 时,它首先选择 oom_score_adj 值最高的容器(1000),这里有两个容器的 oom_score_adj 值都是 1000,OOM killer 最终会选择内存使用量最多的容器。
总结
- 因为 kubelet 默认
每 10 秒抓取一次cAdvisor 的监控数据,所以可能在资源使用量低于阈值时,kubelet 仍然在驱逐 Pod。 - kubelet 将 Pod 从节点上驱逐之后,Kubernetes 会将该 Pod 重新调度到另一个资源充足的节点上。但有时候 Scheduler 会将该 Pod 重新调度到与之前相同的节点上,比如设置了节点亲和性,或者该 Pod 以 Daemonset 的形式运行。