第三单元博客总结
这一单元,主要是进行的JML的使用,以及考察了对于容器,对于算法选择时候的时间复杂度的控制。
JML的理论基础和相关工具
JML的核心就是规格和规范,当我们作为设计者想要向开发表达出让他们做什么的时候,我们往往需要用注释的方式来进行表述,比如某个类应该有什么变量,干什么,再比如某个方法应该做什么,什么可以变,什么不可以变化,以及对于数据有着特殊的要求等等一系列的要求。我最开始的时候认为如果用自然语言模仿规格进行表述的话,可以有着更好的效果。同样,最开始作为一个开发者,我或许更加希望能有类似于规格的自然语言描述。
那么问题来了,我们为什么要用一种规范的类似于伪代码的方式去写注释呢?因为只要有了规范,就代表可以自动化验证,自动化验证可以避免人思维的死角,能够从一个更加完整的系统的方法进行规格的验证,检测正确性,除此之外,为了进行大规模,批量复杂的验证,光靠人力去一点一点看注释解答注释,或者说,让测试人员去先读明白注释,再去读明白代码,检测是否正确,需要大量的人力和时间。如果机器可以代替我们的工作,当然是最好的。但是机器是死的,只能按照模板按照规矩来解读,所以我们不得不创造一个约定,让机器可以识别,但是对于书写者来说便于书写,对于开发者来说便于看,最终就诞生了我们的JML。除此之外,自然语言会有各种各样的歧义,也会导致很大的问题。
JML的核心是用表达式,对于方法规格,类型规格进行控制的一种语言。
这里面就涉及到了三个要素,什么是JML表达式,什么式方法规格,什么是类型规格
注释的形式为两种
行注释和块注释。其中行注释的表示方式为 //@annotation ,块注释的方式为 /* @ annotation @*/
(1)表达式
有关于表达式的内容,说白了就是JML的语法的核心内容,这部分在JML手册里面规定的很详细了,我这里不再过多赘述,
包括原子表达式,量化表达式,集合表达式,操作符等一系列表达式。这些就是JML语言的基本语法,用这些语句表达出具体的意思。
补充一下,表达式内容特别接近离散数学一里面的谓词逻辑系列的内容,在有大一离散数学的基础之上,我们可以不太困难的理解JML的表达式语言
关于表达式的各个内容,比如 esult , forall , exist , max , min , 等等的东西都是很好理解的
esult表示非void的返回值,
forall表示全称量词,给定范围,全部满足约束
exist表示存在量词,给定范围,存在一个满足约束
max表示给定范围最大值
min表示给定范围最小值
ot_assigned(x,y,...)括号内没赋值就是true,反之false
othing 表示空集
everything 表示全集
以上是比较常用的表达式,还有一些不常见的
product连乘, um_of求个数等等
唯一一个需要特别注意的是 old
old(p.length) 和 old(p).length 看起来一样,实际上第一个表示的是变化前的长度,后面表达的是变化后的长度
原因就是,p是一个引用,指向的地址是不变的,也就是 old(p)=p
但是p.length是一个int类型的数据,所以old(p.length)代表先前的数字,
我个人认为,究其本质原因,就在于对象在栈里面就是存了一个地址而已
所以对象p内部数据变了之后,old(p)还是p,然后再查询或者调用变化之后的p的相关数据与方法
(2)方法规格
方法规格的核心就是,满足什么条件达成什么样的结果。特别强调的是,方法规格只规定了满足什么条件,和产生什么结果。不关心产生结果的过程
在这句核心的基础之上,生发出来各种各样的约束,
前置条件(@require):就是需要满足什么要的条件才能进行方法,
后置条件(@ensure):你这个方法做完了要满足什么结果。
在这里特别提出一下,后置条件只规定了方法结束应该满足什么,不规定方法怎么执行。
副作用(@assignable):允许你的方法对什么进行成员修改,不允许你修改的不可以动
在这里补充一下,有一些单独的访问方法,即不会对对象的状态进行任何改变,也不需要提供输入参数,
这样的方法无需描述前置条件,也不会有任何副作用,且执行一定会正常结束。对于这类方法,可以使用
异常(@exceptional_behavior,@signal):满足什么条件,需要你去抛出什么样的异常(使用signal 标注出异常类型)
由此可见,方法规格,或者叫JML的核心,就是调用方法如果满足A条件,必须得到B结果,怎么得到结果?我不关心,那是开发者的事情。
(3)类型规格
类型规格的核心是变于不变,
不变式(invariant)就是告诉你,在方法执行前,完成等可见状态下某种数据变量的要求。
与之相对的约束就是状态变化约束(constraint),如果要变化,怎么变,描述变前变后的关系。
有关JML的工具有很多
如, 使用OpenJml检查JML规范性
如, 使用SMT Solver检查等价性
如, 使用JMLUnitNG自动化生成数据测试
JML相关工具的使用
说到JML相关工具使用,可以说一把心酸,工具的不成熟,JDK版本的不对劲,还有各种各样的神奇bug的出现,导致了一些工具可以使用,而有一些的工具在我的电脑之上完全无法运行。
在查阅了各种各样的资料之后,无论是同学的帮助,还是网上教程,还是学长往届博客,我的工具问题还是没有解决,我就只能简单的说一说我使用过的工具。
注意:一定要用jdk8,不然疯狂报错!!!!!!!!!!!!!!!!!!
(1) openjml与solver
执行语句:java -jar .openjml.jar -exec C:Users73939 Solversz3-4.7.1.exe -esc C:Users73939 *.java
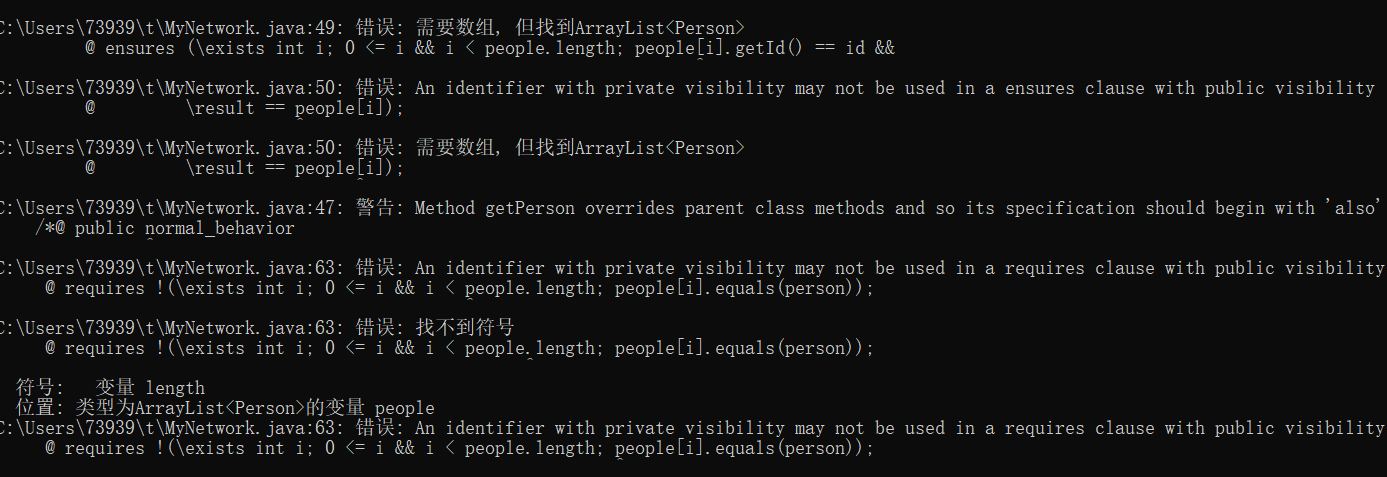
JML域和Java域不能重名,所以完全没法弄,修改的话也设计很多乱七八糟的东西
比如JML里面的Person [ ] people在不同方法里面映射到不同的容器,如hashset,hashmap,arraylist等
还有什么继承的原因,以及各种各样的bug,找不到文件之类的。
就会导致一系列问题,所以我放弃了直接测试,选择分段测试,只测试几个能成功运行的函数
import java.math.BigInteger;
public class Person {
public int id;
public String name;
public BigInteger character;
public int age;
public Person[] acquaintance;
public int[] value;
//@ ensures
esult == id;
public /*@ pure @*/int getId() {
return id;
}
//@ ensures
esult.equals(name);
public/*@ pure @*/ String getName() {
return name;
}
//@ ensures
esult.equals(character);
public /*@ pure @*/BigInteger getCharacter() {
return character;
}
//@ ensures
esult == age;
public/*@ pure @*/ int getAge() {
return age;
}
/*@also
@ public normal_behavior
@ requires obj != null && obj instanceof Person;
@ assignable
othing;
@ ensures
esult == (((Person) obj).getId() == id);
@ also
@ public normal_behavior
@ requires obj == null || !(obj instanceof Person);
@ assignable
othing;
@ ensures
esult == false;
@*/
public/*@ pure @*/ boolean equals(Object obj) {
if (obj != null && obj instanceof Person) {
return (((Person) obj).getId() == id);
} else {
return false;
}
}
/*@ public normal_behavior
@ ensures
esult == name.compareTo(p2.getName());
@*/
public /*@ pure @*/int compareTo(Person p2) {
return name.compareTo(p2.getName());
}
}
这是非常简单的魔改版demo,简单测试了一下
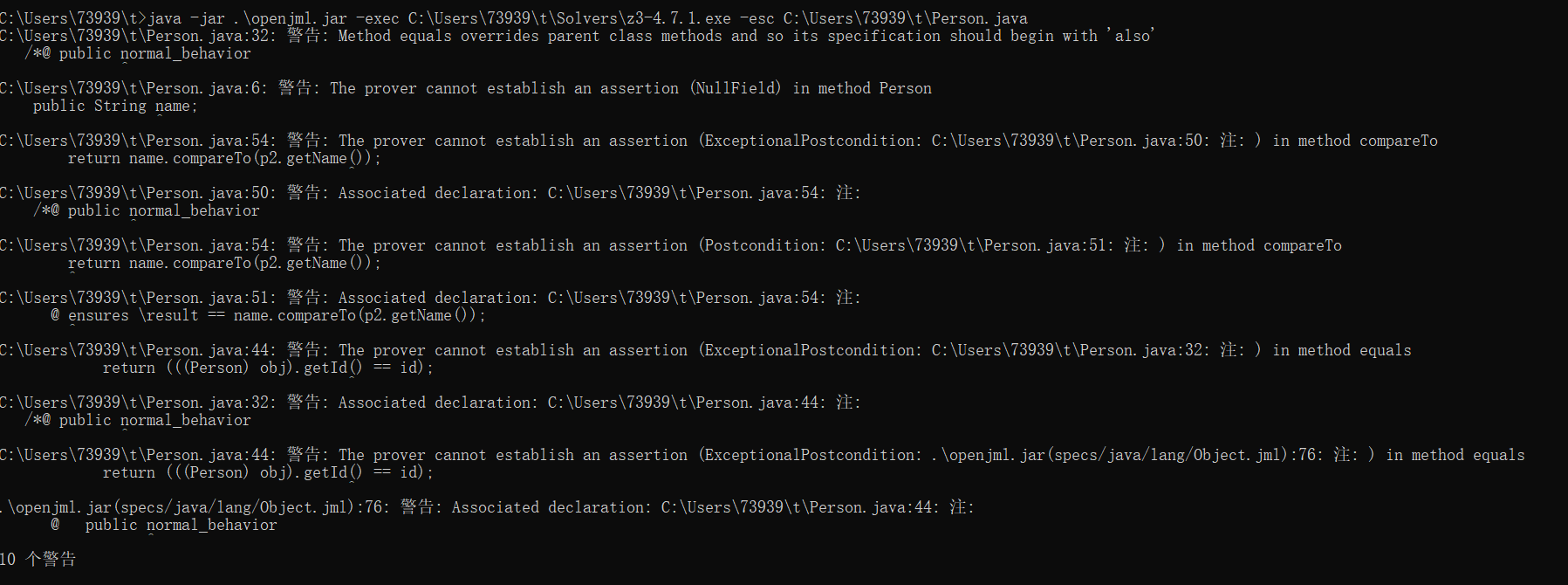
一些警告问题不大,没有错误,不需要过多担心。
但是这只是个demo,我的主要函数想验证特别困难,几乎无法实现,报错信息也没什么价值,就不贴出来了。
除此之外,我最想验证的几个方法,如同最短路径,强连通,连通之类的方法,由于openJML似乎不支持对于 (forall int [] path)之类对于数组的判断,加上我本身使用的各种hashmap,hashset,以及为了满足算法规定增加的若干变量,都没法进行有效的进行openJML的判断 。
到这一步我觉得,如果我为了穿鞋,把脚砍去一半的话,完全体现不出这个博客的意义,所以我在这一步选择了放弃
至少我觉得,如果让程序员抛弃程序效率,抛弃程序简洁度,甚至说是抛弃程序能否满足课程组要求(算法时间之类的),去满足一个比较低下的工具,我真的觉得本末倒置。
(2)JMLUNITNG相关测试
在用这个工具之前,我是满心期待的,这也太爽了吧,我不用对拍了,不用自己写测试代码了
但是我看到一片夹杂的FAILED和PASSED之后,我整个人是完全无语的,
由于实际实现和规格差别过大,疯狂报错,我就为了成功测试Group类,只能先魔改了一下,然后顺便写了一个demo作为测试
魔改版的代码把arraylist换成了数组,可以符合规定
测试结果如下:
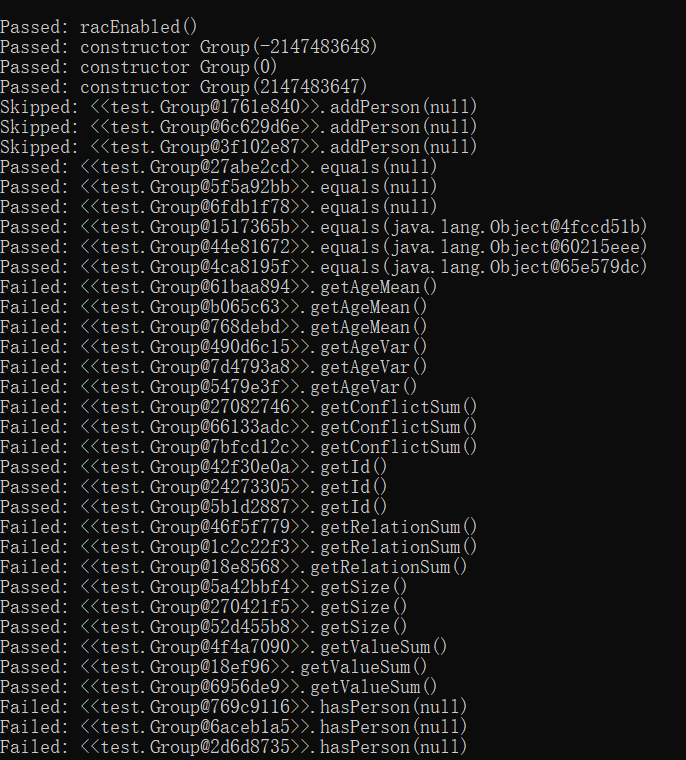
(补充一下,del函数也过了测试)
(魔改版删除了一些我自创的函数,只保留了有规格的函数)
group里面的函数没有什么传参数的,这个包就是靠着传奇怪参数进行测试,所以有一些函数通过了,比如直接返回的函数
hasPerson由于不会出现null,和预计也是一样的,所以falied了
但是怎么解释其他的Falied呢?我仔细分析,发现我的动态维护方法不适合这个包进行测试。
我测试的时候没有加main函数,也没有加network,导致加人的时候,一些方法没有被调用。
因为我的这个类利用的是缓存机制,没有外界同步的进行更新,只有单纯的针对一个方法来回测试,就会导致那些getRelationsum,getValuesum等函数失效
原因就是:单独测试一个函数不一定能保证正确,因为缺少之前添加的很多步骤,尤其是需要network调用这里面的函数更新缓存
换句话说,我因为用的是缓存机制,必须进行完整的指令验证,而不是给定一些数据,计算出结果
我需要从network里面加入之后,在network层次调用函数,更新新的valueSum和relationSum
显然,据我的观测,这个包就是给出一些数据然后判断结果
但是我的动态维护做法必须要求,这些数据每一次出现都是指令产生的,而不是随意给出来的,
用最简单的话来说就是,你想测试这个组里面有三个人时候的平均值,那么必须要一步一步用指令加入三个人,再运算
而不是直接给出三个人,调用函数计算出结果。
这和方法实现有关,同时也是这个测试包本身的限制
一言以蔽之,这个包不适合检查一些动态维护方法,原因就是动态维护需要完整的数据生成过程,每一次进行更新
但是这个包就是给你一些数据,利用函数进行计算而已,它要你的函数返回计算结果,要求无论何时都是计算出来的。
但是显然,课程组要求记忆化,要求动态维护减少复杂度,这个包特别不适合进行验证
这可能是我的猜测,为了验证我的猜测,我深入研究了评测机制
为了深入研究这个包的评测机制,我又写了个demo跑了一下,然后发现这个评测包局限性很大
package test; import java.math.BigInteger; public class Person { public int id; public String name; public BigInteger character; public int age; public Person[] acquaintance; public int[] value; //@ ensures esult == value[i]; public int getValue(int i) { return value[i]; } //@ ensures esult == id; public int getId() { return id; } //@ ensures esult.equals(name); public String getName() { return name; } //@ ensures esult.equals(character); public BigInteger getCharacter() { return character; } //@ ensures esult == age; public int getAge() { return age; } /*@ also @ public normal_behavior @ requires obj != null && obj instanceof Person; @ assignable othing; @ ensures esult == (((Person) obj).getId() == id); @ also @ public normal_behavior @ requires obj == null || !(obj instanceof Person); @ assignable othing; @ ensures esult == false; @*/ public boolean equals(Object obj) { if (obj != null && obj instanceof Person) { return (((Person) obj).getId() == id); } else { return false; } } /*@ also @ public normal_behavior @ ensures esult == name.compareTo(p2.getName()); @*/ public int compareTo(Person p2) { return name.compareTo(p2.getName()); } public static void main(String[] args) { System.out.println("hello") ; } }
然后输入命令
java -jar jmlunitng.jar test/Person.java
javac -cp jmlunitng.jar test/*.java
java -jar openjml.jar -rac test/Person.java
java -cp jmlunitng.jar test.Person_JML_Test
贴图如下
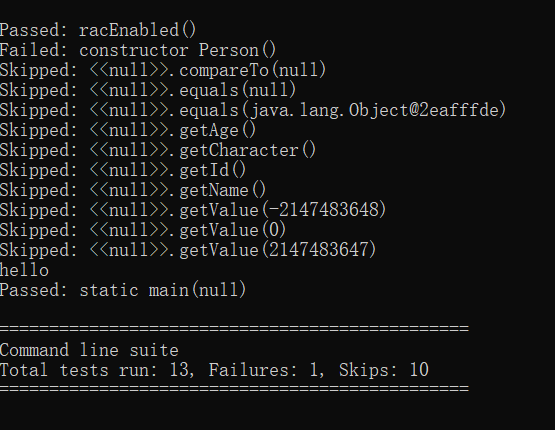
完全不是随机测试
它就是给你的方法输入一些“随机”参数,输入,告诉你Passed还是Failed
之后我又测试了几个demo,发现了神奇的事情,数据长得一模一样
如果参数是int,就给你输入0,int最大值,int最小值
如果参数是对象,就给你一个null进去
之后进行排列组合,进行测试
Passed和Failed的标准似乎是你的程序会不会出现类似于让程序中断的异常
但是新的问题来了,为什么我前面的一些get系列函数会Failed了呢?
如果只是根据异常判断对错的话,理论上get系列函数不会出问题啊?
我前几个fail是因为结果错了还是异常错了?
换句话说,这个东西到底能不能利用JML语言判断返回值是多少,我陷入了怀疑
我觉得作为一个工具,不能,至少不应该只靠异常判断正误,所以我又写了一个demo
//@ ensures esult == 0; public int getZero(int x) { System.out.println(people.length); return 1; } //@ ensures esult == 1; public int getOne(int x) { return 1; }
结果如下
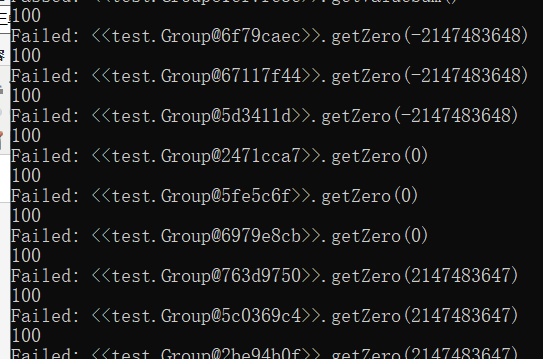

发现这个测试代码是可以根据我的JML判断代码的对错的
也就是说,他不是单纯的极端测试数据测试异常,是可以根据JML判断返回值正确性的!!!
至此,我觉得已经清晰明了了,
仔细观察输出发现三个问题:
(1)测试一个函数不会调用其他函数
(2)测试数据随机生成,而非按照我们要求调用add函数生成
(3)测试参数过于单一
对于有参数的数据:带入极端参数,根据类加生成数据,进行JML结果验证
对于无参数的数据:根据类生成一定数据,进行一定检验,进行JML结果验证
到了这一步,已经验证了我前面为什么failed了的猜想
和我的猜想一模一样,就在于里面的People数组是随机生成的,不是调用add函数加入的,没有同步更新缓存
总而言之,Failed原因:测试包根据类的数据随机生成people,没有从network级调用更新动态维护的数据,也没有走addPerson渠道更新动态维护数据,导致用来缓存的数据 ,不能被及时更新。在函数返回值和根据JML计算值比较的时候,由于返回值并没有在这一次测试的时候更新过,所以出现了错误,导致了Failed。
到此为止可以说是完美破案了
说实话,课程组以及规定了各种异常处理方式,各种数据的限制
很多测试做的无用功,求年龄在-2147483648到0之间的人。。。
总而言之,这个方法只能判断极端条件下的异常,和少数情况下JML的正确性
说实话,限制挺大的,不适合我们这次这种强制在线类型的作业。
(3)JUNIT系列
这个系列是典型的测试,有着完备的工具,规范简单的使用方法,也是我进行测试的主力,但是这个和JML怎么搭配呢?
由于上述工具基本对我都是没有帮助的收益,我只能利用JUnit和自己写其他函数的方式,来模仿一个我希望的“JMLUNIT”“openjml”的功能
我希望有一个测试方法,完全按照规格,只判断满足条件之后的结果
所以我就相当于在测试代码翻译了JML语言后置条件,进行比对操作等等。
总而言之,JML本意是节省人力和时间,但是使用出来之后,却造成了没太大意义的结果
说实话,这不是JML的问题,这是不成熟工具链的问题,我们要给JML工具链发展的时间
我只能说,在现在这个时间段,JML的这几个工具没法高效率投入工作生产甚至课后作业里面发挥很大的良性作用,
这一系列的工具,目前顶多是跑一跑demo,给一点小的提示防止遗漏判断,完全不能满足JML希望的“用规格保证正确”的这种目的。
三次作业架构设计
第一次作业
第一次作业架构很简单
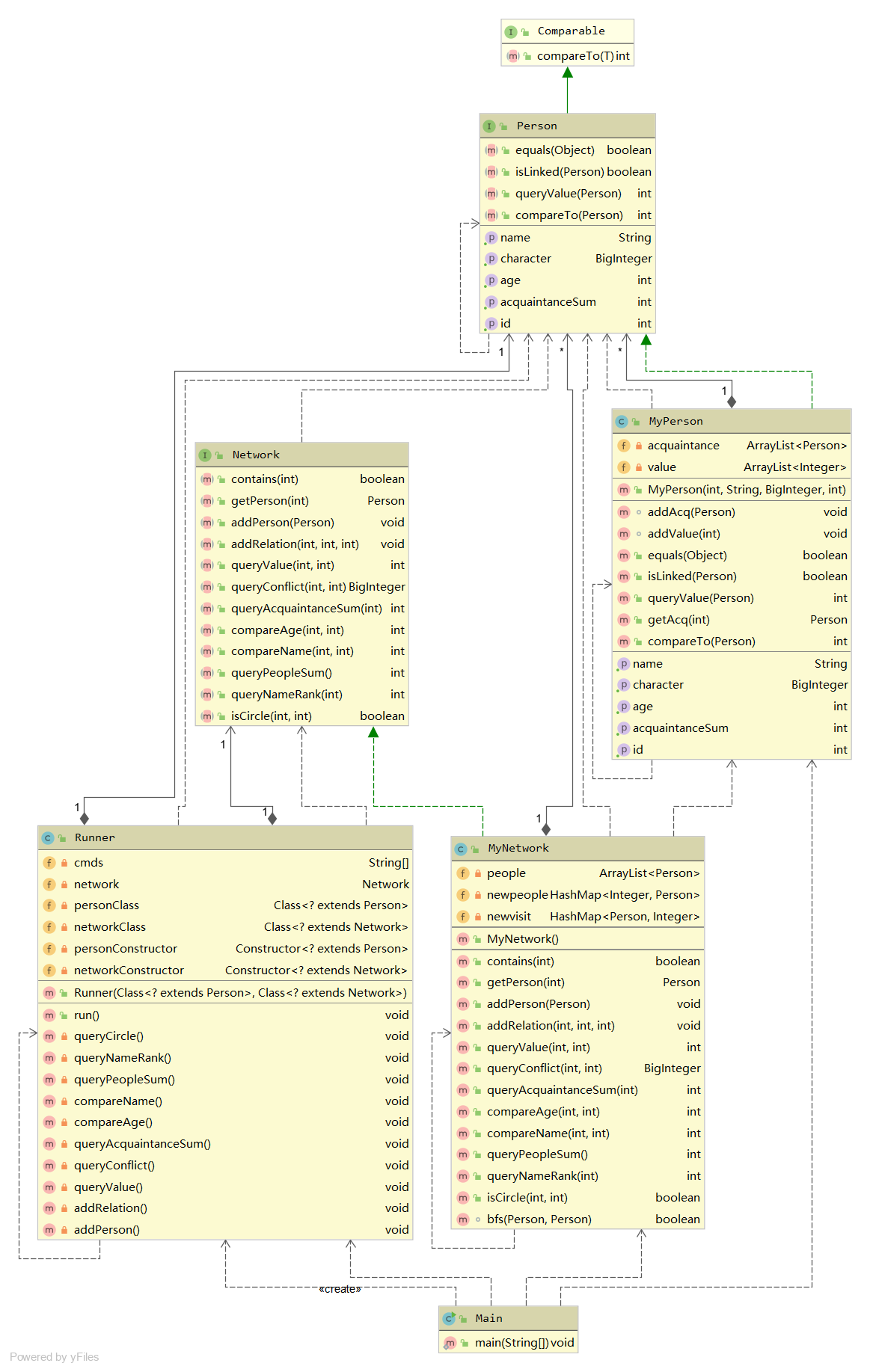
总体来说,没什么好的架构,在当时的时间内,我还处于认为JML规格就是方法执行步骤的阶段
(1)架构设计
JML用的数组,我就用arraylist
(2)算法分析
JML用循环遍历,我也循环遍历
第一次作业唯一一个难度,就是判断两个点是不是直接可达的,这里用到了一个dfs函数,没有更多复杂的东西了
dfs就是简单的遍历每个人相邻的人,还要给访问的人标记访问
标记访问的方法我采用了hashmap,person为索引,(0/1)代表访问与否作为值
第一次作业由于测试很弱,我这种无脑循环的方式可以没有任何bug的通过中测,强测,拿到满分
当时我还以为照着规格翻译就好了,然后第二次作业酿成了大祸
(3)复杂度分析
Myperson复杂度

Mynetwork复杂度

总的来说,不复杂,就是有几个循环而已
第二次作业
第二次作业和第三次类图是一样的

总体结构很简单,因为架构是课程组规定好的,不需要我大幅度更改
(1)架构变化
我做的最大的改变就是:使用hashmap和arraylist结合的方法,
因为hashmap方便取,方便判断存在,但是不方便遍历,而arraylist刚好可以补充遍历困难的弱点,所以我通过两种方法一起使用,相互补充,最大限度减少时间开销,也让代码更加简洁。
当我判断存在的时候,我就调用hashmap,id为索引,person为值
当我遍历的时候,我就取arraylist,更加简单直接
(2)算法改变
我前面说过了,第二次实验,我最开始是无脑的按照规格进行的双循环遍历,
在10w条指令的轰炸之下,出现了巨大的问题,所以我使用了缓存机制
缓存机制也很简单,观察所有算法里面,只有两个函数是O(n*n)的,那就是group里面的getRelationSum()和getValueSum()两个函数
使用双循环直接超时
但是仔细观察这个函数,发现有窍门,可以在每一次加入group的时候更新一次,在每一次加关系时,可能更新一次
所以我进行了更改,先是加人的时候和组里面所有人比对,如果有link的人,就更新relationsum和valuesum
除此之外,还要加上relationsum的自圈数。
但是,有个巨大的问题,那就是当两个人先加入group再加关系的时候,难以直接通过已经有的函数进行更新
那怎么办呢?我选择了牺牲封闭性的方法,额外加了个方法,允许外界更新relationsum,valuesum,那就是加关系的时候判断两个人都在组里面的话,就更新这个组的有关数据
总的来说,这次在JML不代表方法运行方式上面这一点吃了大亏,因为超时出了问题。
(3)复杂度分析
这一次,MyPerson没有变化
MyGroup复杂度

MyNetwork复杂度
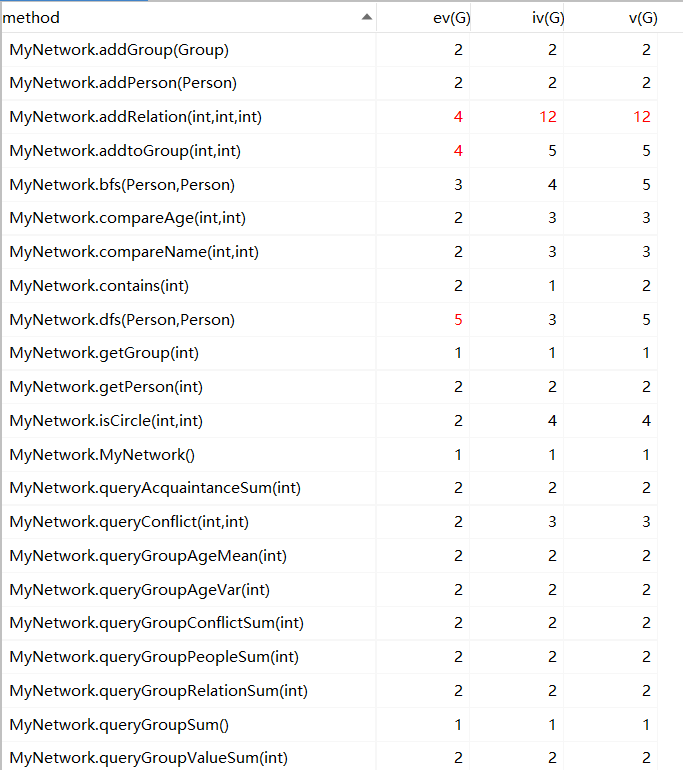
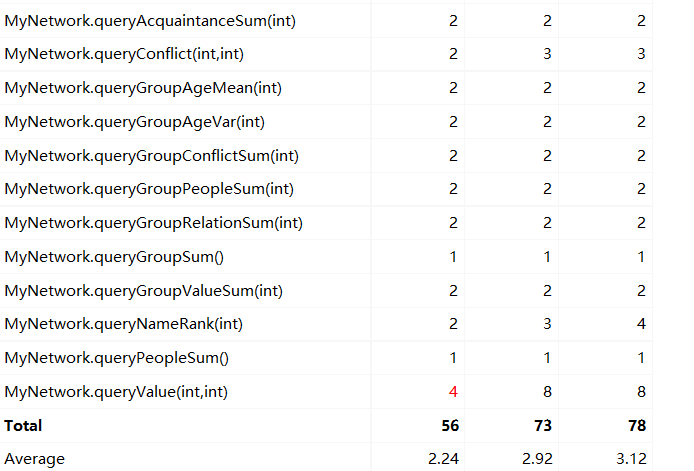
所有复杂度在于添加关系上面。和预想的一样,但是这样子会减少超时的错误,所以是合理的复杂。
第三次作业
第三次作业是这一单元灵魂所在,虽然我的方法最终还是超时了,但是我个人认为,我的一些方法有着很好的借鉴意义。

(1)架构变化
这次为了管理人和钱的关系,使用了hashmap,id为索引,money为值
为了计算最短距离,增加了二维数组,记录两个点之间最短距离,增加关系时动态维护
同时,为了找到每个人对应数组的位置,增加了hashmap,id为索引,在数组位置为值
(2)算法分析
这次的增加了从组里面删除一个人,就是增加一个的镜像操作,把加改成减,利用缓存更新就可以了,问题不大
至于增加的年龄范围的人数,借钱,判断一个人钱多少这种操作,就不提了,因为是很简单的一次遍历或者不用遍历的操作。
这次主要三个大难点
第一,最短路径
最短路径我使用了一个矩阵记录任意两个点之间最短距离,再添加一次关系的时候,更新所有点的最短距离
当调用函数计算最短距离的时候,就是一次二维矩阵的读取操作,是O(1)
但是问题来了,更新最短距离的时候,是一次O(n*n)的操作,特别浪费时间,也是我超时+被hack的直接原因
这一部分内容会在bug里面详细展开
思路就是,最开始所有人之间距离无限大,每次添加关系,如果两个人之间最短距离大于加入的关系,就更新最短距离
如果更新了最短距离,就会进行二重循环遍历,遍历任意两个点的最短距离会不会因为这条边距离的变化而变化,
由于终点和起点都需要包括所有点,所以复杂度数O(n*n)
第二,强连通
强连通我使用了课程组给的方法,如果两个人不是直接连接,就采取每次删除一个人,遍历删除所有人的每一个,之后判断起点终点是否可达的方法
如果两个人因为删除一个人无法连通,就不是强连通。
但是有一个问题,那就是两个人直接link的时候,这种做法是无效的
所以这种情况需要特殊判断,就是遍历起点所有的相邻结点,如果起点的相邻结点(除去终点)有一条不经过起点可以到达终点的路径,那就是强连通的
所以做法分两个分支,直接相连和不直接相连,复杂度都接近O(n*n)
第三,连通块数
使用双循环一定暴毙,所以我用了缓存技术,每次加入一个人,就blocksum加一,每次加入一个关系,如果加关系的两个人之前不是可达的,
那就blocksum-1,代表两个块变成了一个块
这个方法是我觉得的最简单也是最省时间的方法
由于我的最短距离矩阵存在,所以我的isCircle是O(1),所以这个方法也不复杂
(3)复杂度分析
总的来说,这一次我把所有复杂度丢给了addrelation上面,导致了方法臃肿,时间缓慢。


这是network的复杂度,所有复杂度堆在了stronglink和addrelation上面,和预料一致
现在反思,应该降低单个方法复杂度,使用堆优化方法的迪杰斯特拉算法,计算最短路径。
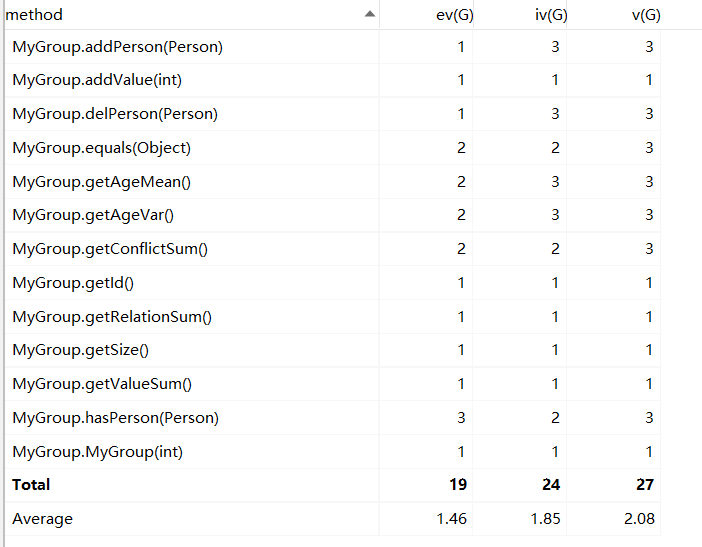
MyGroup的复杂度也没大的变化
这一次作业呕心沥血,担心自己会强测0分,但是结果比想的好了不少,虽然错了几个点,也被hack一次,但是可以接受了
毕竟当时只能想到O(n*n)的方法了,是自己能力不足导致的。
bug实现和修复
第一次,没有bug,
课下进行了大量测试检查正确性
同时我还使用了大量伪JUnit代码进行了测试
都没有发现特别大的问题,也顺利拿下了第一次满分
互测阶段,大家写得基本是一个模子刻出来的,所以没什么测试必要性,
拍了一些没发现大的问题,就没继续管
但是在课下阶段,我最大的问题是isLink函数的实现,想当然认为自己和自己之间不是link的,没有管规格语句,还好及时在课下阶段发现
好几个人,因为这个函数的问题,强测0分
同样的,还有dfs,bfs不标记循环到死的,也在强测拿了0分
这些我在课下都遇到了,也解决了,出现这个问题就是课下不到位,没看规格
第二次,超时bug
这次就是方法完全按照规格后置条件造成的错误
没记忆化,没缓存,无脑循环,不去考虑时间问题
是我这次最大的失误
解决方案就是前文描述的那样,增加缓存机制
组里加人的时候更新,加关系的时候如果在同一组就给这个组更新
很成功的两次解决两个bug。
hack别人也是hack这两个函数,失败了
第三次,超时bug
如同前文所言,所有复杂度堆在了addrelation上面,被人使用addrelation多次给hack了
强测也因为这个问题挂掉了四个测试点
解决bug的方法要完全重构代码,从isCircle,minpath,stronglink到之前若干函数
都要进行大大小小改动调整,截止到写博客这一天,bug还没修理
预计使用堆优化迪杰斯特拉方法修理bug
心得体会
(1)对于JML的用途感悟
经过这一单元,我对于规范化有了更加深刻的认知,虽然因为openjml工具出了问题,导致我的一些验证失败了,但是这个小插曲并不能阻挡我对JML的赞赏。
同样是注释,如果别的课也可以用这种注释给大家进行方法规格的注释,开发者的任务量就会少很多,而且更容易传达相应的信息,防止各种各样的歧义,防止自然语言的一些死角。
自然语言往往为了消除歧义追加内容
然后为了消除追加内容的歧义追加新的内容
再之后每次修订很可能是在改正上一次歧义导致的错误,而不是本身的问题
但是JML语言消除这种歧义,让注释简单易懂,直接了当。
(2)对于JML本身的理解
对于理解JML语言而言,我也有了很高的进步
第一次作业我是忽视JML,按照自己的性子写,觉得差不多就没管
第二次作业我是误以为后置条件是方法执行过程,导致出现了tle
第三次作业是我个人算法设计问题导致了超时,但是完美对接了JML规格,有着很大的进步
多次作业下来,我对规格有了更加深刻的认识,虽然自身代码功底有一些不足,一些算法没实现成功,但是我深刻感受到了读懂规格,遵守规格是一种什么感受,感觉有了规格的帮助,写起代码心里就有了保底,有了底气,只要我满足规格,我就是对的。
规格核心就是,允许你改什么数据,怎么改数据,满足条件达成什么结果
但是规格不关心你取得结果的方法,只关心更改之后的结果是什么样子,以及更改之后的结果和之前应该有什么关系
这种看似锁定但是很自由的规格,真的让我收获很多。
(3)对于java语言的掌握
对于容器选择,对于算法把握,对时间复杂度的分析,
不同容器的不同好处相互结合降低时间,
都是我这个单元很重要的收获
最后,再次强调,虽然openjml没法实现生活中大部分工作和作业要求,但是这不代表JML是有问题的,这种想法,一定会随着工具链逐渐成熟,一步一步深入到软件设计和开发之中。