文章来源:云栖社区,经同意授权转载
链接:https://yq.aliyun.com/articles/226984?spm=5176.8091938.0.0.nCksaV
错误解决记录:
java druid 连接池频繁初始化后导致的too many connection数据库报错。
修改/etc/my.cnf
#加大连接列表数量
max_connections = 2000
# 调整失效连接清理时长 缩短
wait_timeout=7200
interactive_timeout=7200
以上两个配置项配合使用。
一、什么是too many connection
1、重要参数
max_user_connections: The maximum number of simultaneous connections permitted to any given MySQL user account允许的每个用户最大链接数,如果超过这个数值,则会报: ERROR 1203 (42000): User dba already has more than 'max_user_connections' active connections。
一般这样的报错只会出现在业务机器上,并不会在DB server层报错,这样的话DBA就无法真正感知到错误,MySQL也非常贴心的推出了一个status供DBA查看:Connection_errors_max_connections
<section class="135brush" style="margin: 10px 0px; padding: 15px 20px 15px 45px; font-size: 14px; line-height: 22.39px; outline: 0px; border- 0px; border-style: initial; border-color: currentcolor; color: rgb(62, 62, 62); vertical-align: baseline; box-sizing: border-box; background-image: url(" https:="" mmbiz.qlogo.cn="" mmbiz_jpg="" tibrg3aoijtvy5gucqkfy5hqooqnktqmcc1e2igtetiaodqfbqphxthjdmycxagsoko2flsvbtyh2tekiklw2vcg="" 0?wx_fmt="jpeg");" ="" background-position:="" 1%="" 5px;="" background-repeat:="" no-repeat;"=""> Connection_errors_max_connections : The number of connections refused because the server max_connections limit was reached.细心的同学就会发现:那如果出现'max_user_connections' 的报错,就无法发现啦,这块目前我还没找到对应status。
二、什么情况下会发生too many connection
1、slow query 引起
-
真正的slow:该query的确非常慢
-
伪装的slow:该query本身并不慢,是受其它因素的影响导致
2、sleep 空连接引起
-
没有任何query,只是sleep,这种情况一般是代码里面没有主动及时释放链接导致。
三、实战案例
1、sleep 空链接引起的TMC(too many connection简称)
原因由于代码没有主动及时的释放链接,那么在DB Server中存在大量的sleep链接,一旦超过max_connections则报错。
解决方案(1)遇到这样的报错,如果没有及时解决,则会导致后面的业务都一直连不上数据库,影响面很大。
(2)所以我们第一件事情必须是保护数据库,kill掉这些sleep链接。关于kill这件事,又有很多技巧可以谈:
-
如果是人工kill,这简直无法完成这样艰巨的任务,因为业务会时刻产生这样的sleep链接,有无尽头
-
如果自己写脚本,没秒去kill,当然可行。但是我们却碰到过非常极端的情况,那就是MySQL无法响应你的kill请求。
-
所以,这里还有一个更加靠谱的方案就是:设置wait_timeout, 它会自动帮你完成这项庞大且艰巨的任务,且一定可以kill掉
(3)完成上面几个步骤之后,只能保证你的数据库不会被压到,且你有机会登陆进去做一些管理事情,但要彻底解决还必须让业务方处理这些sleep链接。
-
业务团队排查没有释放链接的原因。
-
通常,如果可以,DBA协助业务方提供TMC期间top ip,让业务方排查服务哪里异常。
(4)启用thread_pool功能可能可以解决这个问题,但是由于种种原因没有使用。
-
MySQL官方社区版不支持
-
无法解决slow query引起的TMC
-
可能因为该组件导致其本身的问题
2、 slow query 引起的TMC
(1)先来说说真正的slow query
一般这种情况,也非常清晰明了,找到它,优化它,当然前提是你的数据库还活着。
我们通常有SQL防火墙保护,大大降低了这样的风险。预知SQL防火墙为何物,且听下回分享。
(2)伪装的slow query
好了,终于开始介绍这种最难的故障场景。
难点就是:因为它不是真正的slow,优化点难以寻找,所谓对症下药,就是要找到对应的症状,这也是难点所在。
废话不多说,这里介绍下前一段时间遇到的一次真实的案例。
-
too many connection error
-
threads_runnig 非常多
-
几乎找不到有问题的query,没有明显慢的query
-
几乎任何语句都变得非常慢
-
服务器IO压力并不大
 重要参数详解
重要参数详解
官方文档的解释我不多说,这里简单介绍下自己的理解。
-
innodb_thread_concurrency : 进入innodb存储引擎的线程数量,如果数量满了,就要排队
-
innodb_thread_sleep_delay : 排队等候进入innoDB的时候需要睡眠多长时间
-
innodb_adaptive_max_sleep_delay : 设置一个自适应的最大睡眠时间
-
innodb_concurrency_tickets: 一旦进入innoDB,就会获取一个票据tickets,在票据期间可以随意进入innoDB不需要排队,如果用完了,理论上则要排队(实测后发现并不是严格这套机制)
表结构
 关键参数设置
关键参数设置
set global innodb_thread_concurrency = 1; --方便模拟
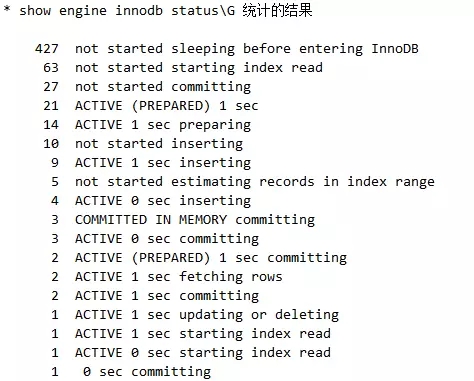
测试用例,三个语句开始执行时间不差1秒 跟踪结果
跟踪结果
 总结
总结
1. 通过以上测试和结果分析得出:当query超过innodb_thread_concurrency时,其余query会等待,及时这样的query非常快,也还是会等待,这就是所谓的伪装的slow query。
2. 通过trx_started,now()分析得出:这些query直接的切换轮询并不是真正意义上的平均公平分配,里面有一套自己的自适应算法,这里面我没有深究下去,有兴趣的同学可以继续了解源码。
3. 既然真正的原因找到,那么解决方案也就很快出来,那就是让并发线程少一点,通过我们的omega平台可以很方便地得出这段时间哪些query和connect最多,那么协助业务一起沟通业务场景和优化方案,问题得到解决。