2.1 模型评估指标
评估指标是用来反应模型效果好坏的量度。这里主要介绍回归,分类和聚类这三种常见任务的评估指标。评估指标与损失函数有很大的关系,损失函数不同评估指标也不尽相同。
2.1.1 回归模型指标
-
概念:表示了预测值与真实值之间的差距。
python实现
abs(y_ture,y_hat)sklearn实现
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_ture,y_hat) -
均方误差
概念:预测值与实际值之差平方和的均值。
python实现
def mean_squared_error(X,Y,W,b):
return sum([(y - w * x + b) ** 2 for x,y in zip(X,Y)]) / len(X)
sklearn实现
from sklearn.metrics import mean_squared_error
mean_squared_error(y_true,y_hat)
2.1.2 分类模型评估指标
-
准确率
概念:这是分类任务中必备的一个评估指标。它表示了在测试样本中正确预测的比例。
sklearn实现
from sklearn.metrics import accuracy_score
accuracy_score(y_ture,y_pred,normalize=True)
'''
y_true:实际类别
y_pred:预测类别
normalize:True输出准确率,False输出正确分类的数目。
''' -
精度--查准率
概念:预测为正例的样本中真正正例的比例。预测为正例的样本中有真为正例的情况和错误检测为正例的情况。反应模型检测效果的准确性。这里就有一种问题,就是比如一共有10个正例,模型检测出来一个,还检测正确。那精度也是100%。
sklearn实现
from sklearn.metrics import precession_score
precession_score(y_true,y_pred,average=None)
'''
当选择None时,会直接返回各个类别的精度列表。
当选择macro时,直接计算各个类别的精度值的平均(这在类别不平衡时不是一个好的选择)。
当选择weight时,可通过对每个类别的score进行加权求得。
当选择micro时,在多标签问题中大类将被忽略。
'''
-
召回率
概念:测试集所有正例被正确检测的比例。召回率可以弥补精度的不足。
sklearn实现
from sklearn.metrics import recall_score
recall_score(y_true,y_pred,average=None)
-
F1值
我们知道precession与recall是互补的两个指标。那么F1值就利用这么特性来找折中点,从而得到最好的模型效果。
这里不懂的话参考:
sklearn实现
from sklearn.metrics import f1_score
f1_score(y_true,y_pred,average=None)
输出以上指标报告
可以直接使用sklearn方法将上述值同时生成。这里吐槽依据,sklearn确实是机器学习很便捷得 使用工具,就是不搞GPU加速0.0
from sklearn.metrics import classification_report
classification_report(y_true,y_pred,target_names)
'''
target_names:是类别列表。如['class1','class2']
'''
ROC曲线

该曲线的横坐标为假阳性率(False Positive Rate, FPR),N是真实负样本的个数, FP是N个负样本中被分类器预测为正样本的个数。纵坐标为真阳性率(True Positive Rate, TPR)。
这里很容易一头雾水。首先来看看真阳性率,如上面公式所示。表示所有预测数据中,正确 预测为正例得比例。假阳性率则表示所有预测数据中,错误预测为正例的比例。
绘制曲线的步骤:
(1)假如已经得到了所有样本的概率输出prob值,我们就可以根据每个测试样本属于正样本 的概率值从大到小排序。
(2)接下来,我们从高到低,依次将prob值作为阈值(threshold),当测试样本属于正样本 的概率大于或等于这个 threshold 时,我们认为它为正样本,否则为负样本。
(3)每次选取一个不同的threshold,我们就可以得到一组FP和TP,即ROC曲线上的一点。 这样我们可以得到很多组FP和TP的值,将它们画在ROC曲线上的结果如图所示。
sklearn实现
from sklearn import metrics
metircs.roc_curve(y_ture,y_pred_prob,pos_label)
'''
y_pred_prob:预测概率值
pos_label:正例的类别
'''
注意:P-R曲线与ROC曲线有一个一致的属性,如果其中一条曲线包含另一条曲线,那么前 者效果肯定优于后者。
AUC
概念:当ROC曲线发生交叉时的判断优劣的依据,AUC表示ROC两条曲线的面积。
sklearn实现
from sklearn.metrics import roc_auc_score
roc_auc_score(y_true,y_pred_prob)#这里仅限二分类情况
混淆矩阵
混淆矩阵时评估分类模型好坏的形象化工具。
sklearn实现
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true,y_pred)
2.1.3 聚类模型的评估指标
已经了解了回归任务评估指标与分类任务评估指标,发现就是按照任务来想办法判断模型是否有效与多有效的问题,这里会结合最终输出来具体找寻统计学方法来判断。
那么聚类要如何评估呢?我们考虑一下聚类的初衷是什么。聚类是让模型主动挖掘数据间隐含的关系,最终达到的效果也是分类效果。如何来判断数据的类别呢?聚类是将相似度高的聚为一类,每个类别或这蔟都是相关性低的。那么就依此作为模型的评估指标。
通常聚类模型的评估指标有外部指标与内部指标两种。
这里发现一个总结得很好得博客推荐下:
2.1.4 常用距离公式
曼哈顿距离
曼哈顿距离表示来了样本点间距离的绝对值之和。用来统计预测试与真实值的差距。
python实现
sum(abs(X1 - X2))
欧氏距离
欧式距离和我们常用L2范数是一致的。它是距离之差的平方和开2次根号。
python实现
#第一种方法
(sum((X1 - X2)**2)) ** 0.5
#第二种方法
import math
math.sqrt((sum((X1 - X2)**2)))
#第三种方法
import numpy as np
np.sqrt((sum((X1 - X2)**2)))
闵可夫斯基距离
闵可夫斯基在欧式距离上做了变化,更细致得说是一种推广变体。欧式距离是平方和开平方根,都是2次得。而闵可夫斯基公式是p方和开p方根,p是可以自由指定的。
python实现
(sum((X1 - X2)**p)) ** (1/p)
切比雪夫距离
无穷级数。不要被这个外国人名字迷惑,也别怕无穷级数。就是求最大距离。
python实现
max(abs(X1-X2))
余弦(xian二声)夹角
余弦定理大家都学过。这里直接上代码。
import numpy as np
d1=np.dot(X,Y)/(np.linalg.norm(X)*np.linalg.norm(Y))
汉明距离
汉明距离表示两字符串中不相同位数的数目。没用过,不敢说。
杰卡德相似系数
这通常会在聚类中出现,表示集合A,B的关系。用来衡量集合的相似程度,杰卡德相似系数与集合相似程度呈正相关。
J(A,B) = |A ∩ B| / |A ∪ B|
杰卡德距离
distance(J) = 1 - J(A,B)
吐槽:我如果有这些外国朋友,我觉得把他们按one-hot编码排一下比较好。名字太难记,我相信更难写。
2.2 模型复杂度量度
2.2.1 偏差与方差
这应该是除中高中的知识吧,或者有人小学也学过。这俩指标是经典的模型泛化能力衡量指标,无论是机器学习模型还是深度学习。
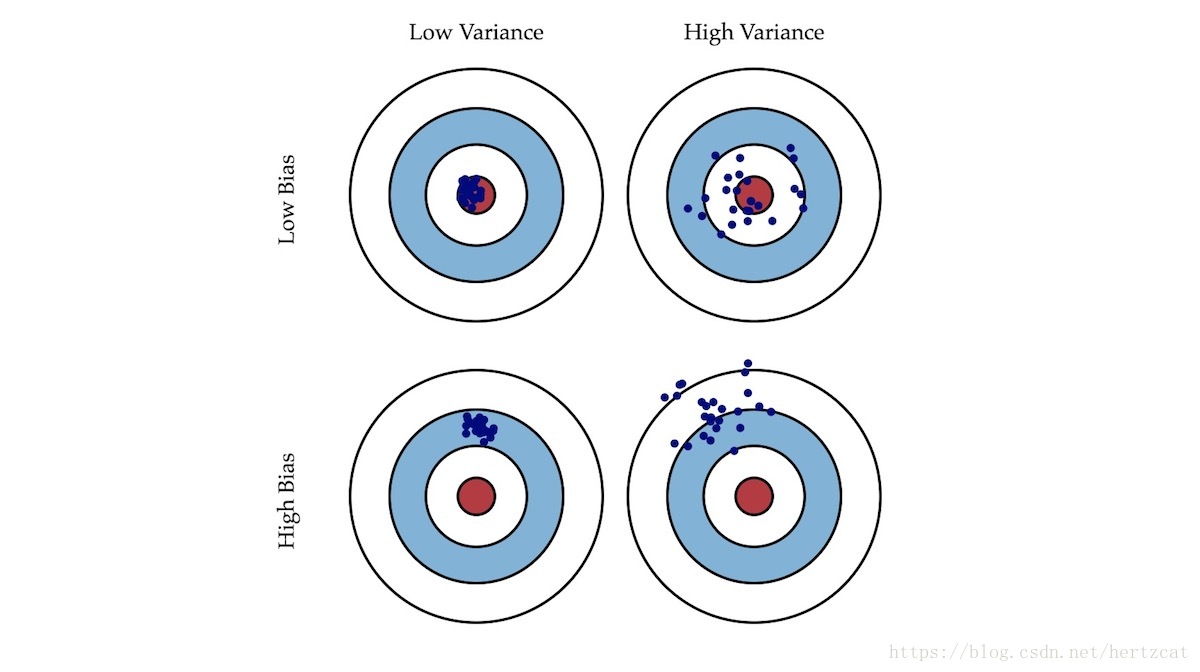
这个图是吴恩达机器学习课程中的教学用图。很直观的体现了偏差与方差的区别。先来了解一下偏差和方差映射到模型与数据上的关系,就很容易解读这个图。
偏差:指预测试与真实值的差距大小。那么偏差越小,说明模型更好的拟合了训练数据。一般随着模型训练次数的增加,偏差会逐渐减小。去过偏差过大,就说明模型没有很好的拟合训练数据,出现欠拟合情况。这里需要思考一个问题,偏差越小,模型泛化能力越好吗?
方差:表示了预测值与均值差距的平方和。体现了预测数据的稳定性。方差越大数据波动越大,这时会出现一个问题那就是过拟合。
泛化能力:模型最终是要在训练数据以外的场景数据下作应用,也就是作测试。这就要求模型在训练集有着好的效果,在未知测试集也要有好的效果。那么反应到偏差和方差的体现就是低偏差和低方差。
2.2.2 解决欠拟合与过拟合
1.过拟合与欠拟合
上面介绍了模型泛化的反应指标,也介绍了欠拟合与过拟合概念。下面来看看形成underfitting与overfitting的原因与解决办法。
欠拟合的成因
1.数据量过少
由于数据量少,模型无法学习到足够的表示数据关系的规则
2.模型复杂度低
原因同上
3.训练不够充分
同上。其实欠拟合基本就是学习不充分的原因,那么不充分具体体现在哪里,就是上面介绍的三个地方。
如何解决欠拟合现象
解决欠拟合也就是往成因的反方向进行
1.增加数据
可以采用数据增强,或者采集数据
2.增加模型复杂度
这里可以选择更复杂的模型,比如深度学习可以从VGG换为Resnet。
3.叠加训练次数
增加epoch值。训练迭代更多次。
过拟合的原因
主要介绍一下三点,随着学习和工作自然会对欠拟合与过拟合有更深入的认识与了解。
1.样本复杂而样本samples少。和欠拟合第一条一致
2.噪声过大
噪声属于样本中的异类,不代表真正数据的关系。
3.模型对于任务来说过于复杂
比如一个线性分布的数据做拟合,直接用线性回归和用多层感知机来拟合。多层感知机得到的曲线一般是经过数据的每一个点的折现或者光滑曲线。
如何解决过拟合
思路同解决欠拟合一致
1.获取更多数据采用交叉验证
交叉验证是机器学习中常用的数据划分与模型训练方式。后面章节会有具体演示。
2.加入正则化
正则化的思想是限制模型复杂度,使用的手段是增加模型复杂度带来的惩罚,具体实现是给损失函数增加偏置项。由于过拟合会导致损失函数更小,体现在曲线拟合上,会产生更加平滑的拟合曲线,这是由于梯度传播导致的。这项偏执就会使梯度下降在一个合理的范围内,进而防止过拟合。如果听不懂,引用吴恩达老师的一句经典口头禅:'Dont worry about that',第一眼看不懂就看第二次,第二次看不懂就往下学,学得多了,代码写多了自然就会了。
3.对网络采用Dropout
这主要用在深度神经网络中,对某层的神经元节点进行随机的失活,也就是不要它了。
4.选用更轻量的网络。
轻量意味着更简单的网络
2. 经验风险与结构风险
这里先介绍一个概念。
经验风险:就是损失函数。怎么理解经验风险这个名词呢。学习一般指有监督学习,这个监督是由人类经验造成的,加之选择模型本身规则与数据关系规则的差异,这都可以叫做经验,这些经验经过损失函数的体现与度量,也就形成了经验风险。
结构风险:就是正则化参数。这里的结构指的是模型结构,模型结构的复杂程度带来的差异我们称为结构风险。
python伪代码来体现
min(1/m * sum(loss)) + λ * J(W)
'''
这里+号前半部分就是经验风险,即最小化损失函数
+号后,λ是系数,J(W)为选择的范数,比如L1,L2等
'''
3.正则化
正则化方法我们已经讲过,它是由不同种类的范数来体现的。这里主要介绍常用的L0,L1,L2三种范数。我记得花书里有更多种类的范数,有余力可以看看。
L0范数
||W||p = (sum( |Wj| ** p)) ** 1 / p
这里的W表示权重向量。L0范数的物理意义可以理解为向量中非0元素的个数。如果我们用L0范数来规则化权重向量w,就是希望w中的大部分元素都是0;换句话说,就是让权重向量w是稀疏的。
L1范数
|| W1 ||1 = sum(| Wj |)
L1范数与L0范数相似,也会使得权重向量变稀疏,但L1容易优化求解,所以一般使用L1范数。
L2范数
L2范数指的是权重向量个元素的平方和的开平方。
在添加了L2正则后,第j个特征对应权重wj由原来的wj变成了(1−η)wj;由于η都是正数,所以1−η≤1,因此它的效果就是减小wj,这就是所谓的权重衰减。L2范数是应用最广泛的正则化范数。
这里感兴趣的化使用梯度下降推到一下偏导数,会对过程有更深入的理解。
2.3 特征工程与模型调优
简要介绍一个机器学习或者特征工程的流程,方便建立全局观和熟悉工作流程。
-
业务理解
需要知道要干什么,整体分析规划
-
数据分析
查看数据分布和规模。了解数据格式,数据是否存在问题,了解数据情况
-
特征工程
对数据进行处理,提取有效特征。
-
模型选择
选择合适模型
-
模型评估
对模型效果进行测试
-
项目落地
将最终训练模型投入实际生产环境
这里涉及python数据分析,与特征工程两项工作。后续在实例中会具体讲解。这也是机器学习必备的技能。