本教程展示了如何对结构化数据进行分类(例如CSV中的表格数据)。我们使用Keras定义模型,并将csv中各列的特征转化为训练的输入。 本教程包含一下功能代码:
- 使用Pandas加载CSV文件。
- 构建一个输入的pipeline,使用tf.data批处理和打乱数据。
- 从CSV中的列映射到用于训练模型的输入要素。
- 使用Keras构建,训练和评估模型。
1.数据集
我们将使用克利夫兰诊所心脏病基金会提供的一个小数据集。 CSV中有几百行。 每行描述一个患者,每列描述一个属性。 我们将使用此信息来预测患者是否患有心脏病,该疾病在该数据集中是二元分类任务。
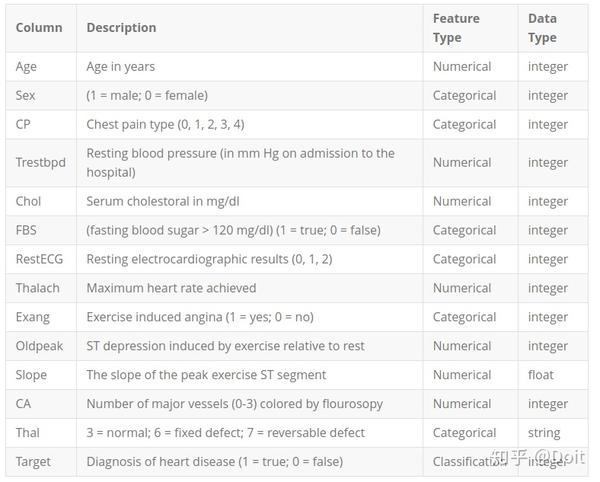
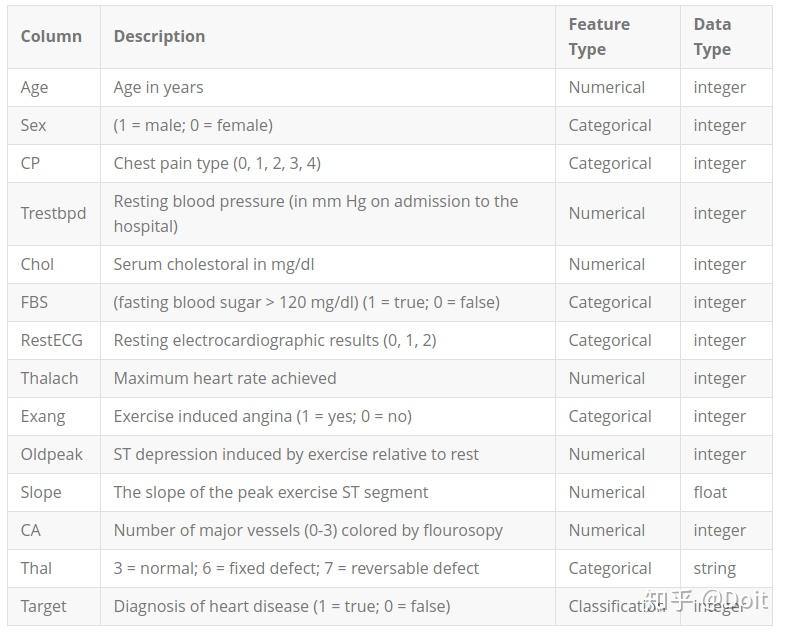
2.准备数据
使用pandas读取数据
URL = 'https://storage.googleapis.com/applied-dl/heart.csv'
dataframe = pd.read_csv(URL)
dataframe.head()age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal target 0 63 1 1 145 233 1 2 150 0 2.3 3 0 fixed 0 1 67 1 4 160 286 0 2 108 1 1.5 2 3 normal 1 2 67 1 4 120 229 0 2 129 1 2.6 2 2 reversible 0 3 37 1 3 130 250 0 0 187 0 3.5 3 0 normal 0 4 41 0 2 130 204 0 2 172 0 1.4 1 0 normal 0
划分训练集验证集和测试集
train, test = train_test_split(dataframe, test_size=0.2)
train, val = train_test_split(train, test_size=0.2)
print(len(train), 'train examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
193 train examples
49 validation examples
61 test examples使用tf.data构造输入pipeline
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop('target')
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
return ds
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
for feature_batch, label_batch in train_ds.take(1):
print('Every feature:', list(feature_batch.keys()))
print('A batch of ages:', feature_batch['age'])
print('A batch of targets:', label_batch )
Every feature: ['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg', 'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'thal']
A batch of ages: tf.Tensor([61 51 57 51 44], shape=(5,), dtype=int32)
A batch of targets: tf.Tensor([0 0 0 1 0], shape=(5,), dtype=int32)3.tensorflow的feature column
example_batch = next(iter(train_ds))[0]
def demo(feature_column):
feature_layer = layers.DenseFeatures(feature_column)
print(feature_layer(example_batch).numpy())数字列
特征列的输出成为模型的输入。 数字列是最简单的列类型。 它用于表示真正有价值的特征。 使用此列时,模型将从数据框中接收未更改的列值。
age = feature_column.numeric_column("age")
demo(age)
[[61.]
[51.]
[57.]
[51.]
[44.]]Bucketized列(桶列)
通常,您不希望将数字直接输入模型,而是根据数值范围将其值分成不同的类别。 考虑代表一个人年龄的原始数据。 我们可以使用bucketized列将年龄分成几个桶,而不是将年龄表示为数字列。 请注意,下面的one-hot描述了每行匹配的年龄范围。
age_buckets = feature_column.bucketized_column(age, boundaries=[
18, 25, 30, 35, 40, 50
])
demo(age_buckets)
[[0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 1. 0.]]类别列
在该数据集中,thal表示为字符串(例如“固定”,“正常”或“可逆”)。 我们无法直接将字符串提供给模型。 相反,我们必须首先将它们映射到数值。 类别列提供了一种将字符串表示为单热矢量的方法(就像上面用年龄段看到的那样)。 类别表可以使用categorical_column_with_vocabulary_list作为列表传递,或者使用categorical_column_with_vocabulary_file从文件加载。
thal = feature_column.categorical_column_with_vocabulary_list('thal', ['fixed', 'normal', 'reversible'])
thal_one_hot = feature_column.indicator_column(thal)
demo(thal_one_hot)
[[0. 0. 1.]
[0. 1. 0.]
[0. 0. 1.]
[0. 0. 1.]
[0. 1. 0.]]嵌入列
假设我们不是只有几个可能的字符串,而是每个类别有数千(或更多)值。 由于多种原因,随着类别数量的增加,使用单热编码训练神经网络变得不可行。 我们可以使用嵌入列来克服此限制。 嵌入列不是将数据表示为多维度的单热矢量,而是将数据表示为低维密集向量,其中每个单元格可以包含任意数字,而不仅仅是0或1.嵌入的大小是必须训练调整的参数。
注:当分类列具有许多可能的值时,最好使用嵌入列。
thal_embedding = feature_column.embedding_column(thal, dimension=8)
demo(thal_embedding)
[[ 0.21029451 0.28502795 0.27186757 -0.13927 0.44176006 0.18506278
-0.14189719 0.2901029 ]
[-0.02674027 -0.21359333 -0.26675928 0.6544374 0.12530805 -0.5243998
-0.23030454 -0.10796055]
[ 0.21029451 0.28502795 0.27186757 -0.13927 0.44176006 0.18506278
-0.14189719 0.2901029 ]
[ 0.21029451 0.28502795 0.27186757 -0.13927 0.44176006 0.18506278
-0.14189719 0.2901029 ]
[-0.02674027 -0.21359333 -0.26675928 0.6544374 0.12530805 -0.5243998
-0.23030454 -0.10796055]]哈希特征列
表示具有大量值的分类列的另一种方法是使用categorical_column_with_hash_bucket。 此功能列计算输入的哈希值,然后选择一个hash_bucket_size存储桶来编码字符串。 使用此列时,您不需要提供词汇表,并且可以选择使hash_buckets的数量远远小于实际类别的数量以节省空间。
注:该技术的一个重要缺点是可能存在冲突,其中不同的字符串被映射到同一个桶。
thal_hashed = feature_column.categorical_column_with_hash_bucket('thal', hash_bucket_size=1000)
demo(feature_column.indicator_column(thal_hashed))
[[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]交叉功能列
将特征组合成单个特征(更好地称为特征交叉),使模型能够为每个特征组合学习单独的权重。 在这里,我们将创建一个与age和thal交叉的新功能。 请注意,crossed_column不会构建所有可能组合的完整表(可能非常大)。 相反,它由hashed_column支持,因此您可以选择表的大小。
crossed_feature = feature_column.crossed_column([age_buckets, thal], hash_bucket_size=1000)
demo(feature_column.indicator_column(crossed_feature))
[[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]4.选择使用feature column
feature_columns = []
# numeric cols
for header in ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'slope', 'ca']:
feature_columns.append(feature_column.numeric_column(header))
# bucketized cols
age_buckets = feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
feature_columns.append(age_buckets)
# indicator cols
thal = feature_column.categorical_column_with_vocabulary_list(
'thal', ['fixed', 'normal', 'reversible'])
thal_one_hot = feature_column.indicator_column(thal)
feature_columns.append(thal_one_hot)
# embedding cols
thal_embedding = feature_column.embedding_column(thal, dimension=8)
feature_columns.append(thal_embedding)
# crossed cols
crossed_feature = feature_column.crossed_column([age_buckets, thal], hash_bucket_size=1000)
crossed_feature = feature_column.indicator_column(crossed_feature)
feature_columns.append(crossed_feature)构建特征层
feature_layer = tf.keras.layers.DenseFeatures(feature_columns)
batch_size = 32
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)5.构建模型并训练
model = tf.keras.Sequential([
feature_layer,
layers.Dense(128, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(train_ds, validation_data=val_ds,epochs=5)
Epoch 1/5
7/7 [==============================] - 1s 133ms/step - loss: 1.1864 - accuracy: 0.6357 - val_loss: 0.6905 - val_accuracy: 0.5714
Epoch 2/5
7/7 [==============================] - 0s 24ms/step - loss: 0.9603 - accuracy: 0.6804 - val_loss: 0.4047 - val_accuracy: 0.8163
Epoch 3/5
7/7 [==============================] - 0s 24ms/step - loss: 0.5744 - accuracy: 0.7389 - val_loss: 0.6673 - val_accuracy: 0.7755
Epoch 4/5
7/7 [==============================] - 0s 24ms/step - loss: 0.4890 - accuracy: 0.8092 - val_loss: 0.6298 - val_accuracy: 0.6122
Epoch 5/5
7/7 [==============================] - 0s 24ms/step - loss: 0.5618 - accuracy: 0.6795 - val_loss: 0.3861 - val_accuracy: 0.8367
<tensorflow.python.keras.callbacks.History at 0x7fcb23e9d198>测试
loss, accuracy = model.evaluate(test_ds)
print("Accuracy", accuracy)
2/2 [==============================] - 0s 16ms/step - loss: 0.8278 - accuracy: 0.6066
Accuracy 0.60655737Tensorflow 2.0 入门教程: