项目地址
https://github.com/TragedyN/personal-project
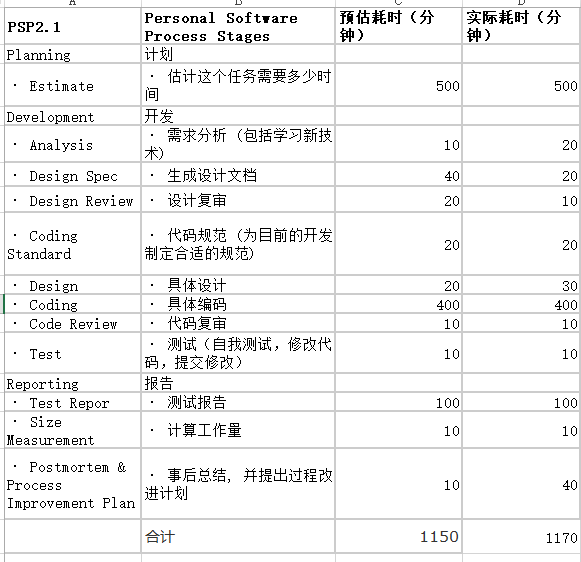
PSP表格
解题思路描述
按题目要求,先读入文件内容,使用ifstream逐个读取字符,计字符数变量自增,遇到换行符计行数变量自增,而在加入字符串时,将换行符转化成空格字符,并逐个存入设置为全局变量的string对象中,作为一个完整连续的字符串供检测词频函数使用,最后结果用ofstream写到.txt中。
找资料的话,一开始我是不大了解要如何写一个函数可以逐个读字符,且这个函数必须可以读到换行符,之后就是查了一下如何根据题意分割字符串,还有对map对象进行排序等。
设计实现过程
抱着一切从简的想法,我将计算行数的步骤并到计算字符串的过程中,因此只是设置了一个全局变量记录行数,而读取字符设计为一个函数,该函数可以根据文件名直接读取文件中的内容,并最终将内容处理合成为一个字符串,并返回统计的字符数。
而在统计词频的函数中,我根据题意先后设置了将字符串转换为全小写的函数和切割字符串的函数,此外又设置了一个函数判断字符串组中的字符串是否符合题意,最后就是一个对设置为全局变量的容器(vector)排序的函数,之后返回统计单词数的量。
做功能分割之后,就按照要求设计了三个函数,都放在WordCount.cpp中,各自可以完成自己的功能,函数接受以字符串形式存在的文件名,根据题意分别返回int和打印排序结果,统计行数生成lines.txt文件,统计字符数生成characters.txt,统计单词数写到words.txt,统计前十词频写到WordsFrequency.txt中。
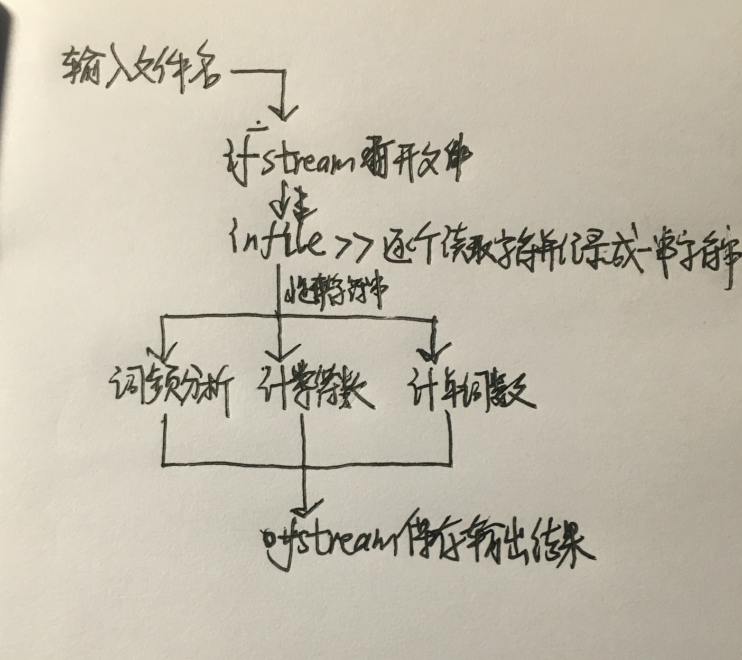
流程图:
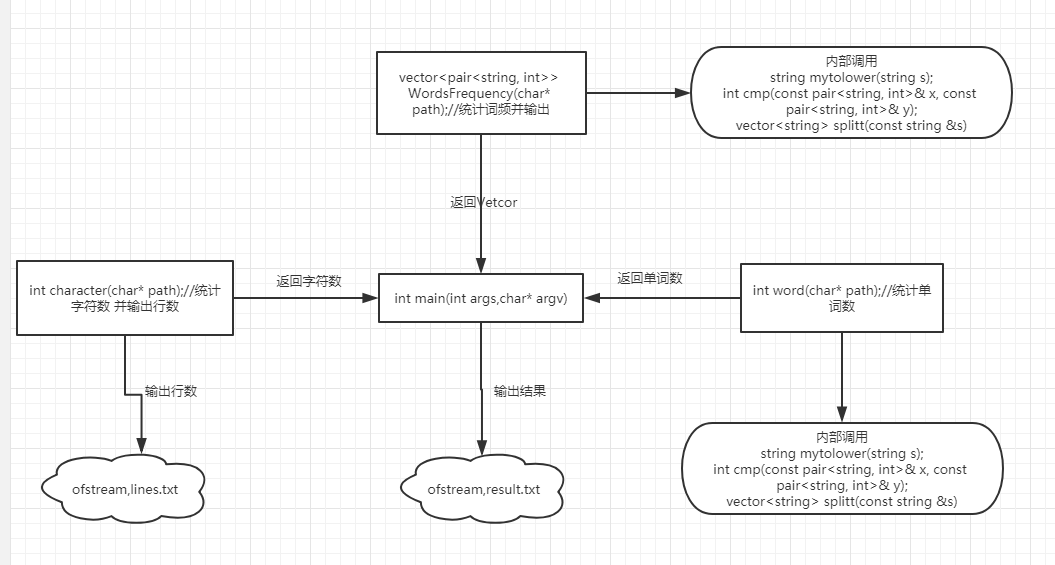
关键代码说明
//统计字符数 int character(char* path) { ifstream infile; infile.open(path); //将文件流对象与文件连接起来 char c; int count = 0,i = 0; infile >> noskipws; while (!infile.eof()) { infile >> c;//逐个读取文件中的字符 if (c == ' ') { if (ff[i] != ' '&&i!=0) { //cout << i << endl; lines++;//统计行数 } c = ' '; } ff += c; //cout << ff[i] << endl; count++;//统计字符数 i++; } ff[i] = '�';//多了一次循环 infile.close();
count--;//多了一次循环 lines++;//最后一行没有换行符,所以要加上最后一行 return count; }
//统计词频和单词数 int word(string strr) { int i = 0, count = 0; map <string, int> m1; map <string, int>::iterator m1_Iter; vector<string> split = splitt(strr);//存字符串和对应的次数 for (vector<string>::size_type i = 0; i != split.size(); ++i){ //cout << split[i] << endl; string key = split[i]; if (key.size() >= 4 && isstring(key) == 1) { cout << "符合条件的字符串是:" << key << endl; if (m1.count(key) == 0) { count++; m1.insert(pair <string, int>(key, 1)); } else { m1[key]++; } } } reorder(m1); return count; }
//分隔符判断并切割字符串 vector<string> splitt(const string &s) { vector<string> result; typedef string::size_type string_size; string_size i = 0; while (i != s.size()) { //找到字符串中首个不等于分隔符的字母; int flag = 0; while (i != s.size() && flag == 0) { flag = 1; if (isalnum(s[i])==0) { ++i; flag = 0; break; } } //找到又一个分隔符,将两个分隔符之间的字符串取出; flag = 0; string_size j = i; while (j != s.size() && flag == 0) { if (isalnum(s[j])==0) {//isalnum()判断输入参数是否为字母或者数字 flag = 1; break; } if (flag == 0) ++j; } if (i != j) { result.push_back(s.substr(i, j - i)); i = j; } } return result; }
//比较 int cmp(const pair<string, int>& x, const pair<string, int>& y) { if(x.second != y.second) return x.second > y.second; else { return x.first < y.first;//字典序靠前 } } //排序 void reorder(map <string, int> m) { //map <string, int>::iterator m1_temp; for (map<string, int>::iterator curr = m.begin(); curr != m.end(); curr++) tVector.push_back(make_pair(curr->first, curr->second)); sort(tVector.begin(), tVector.end(), cmp); }
性能分析
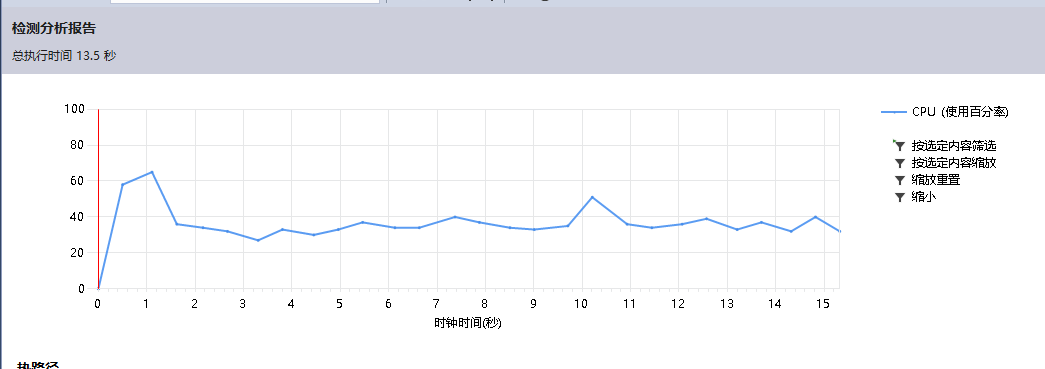
调用最大资源的函数
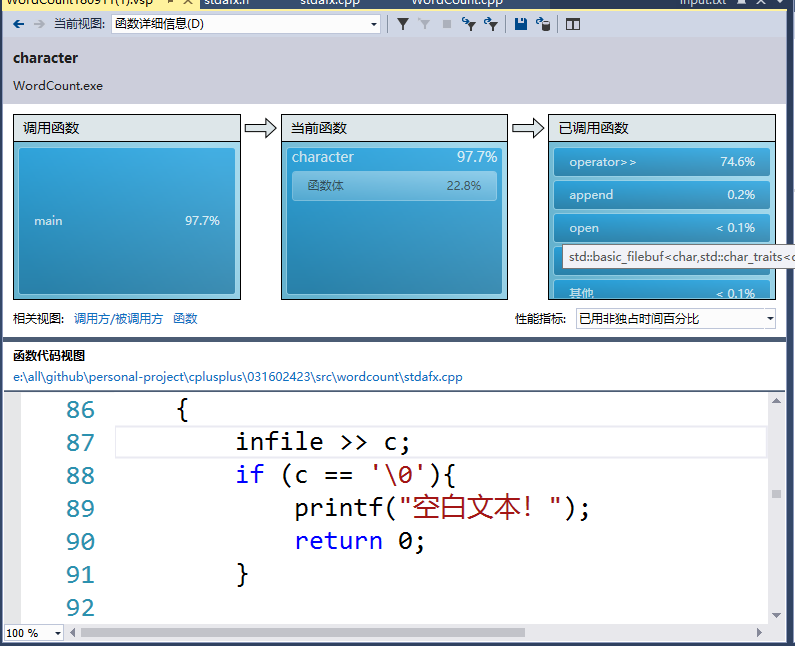
结果显示,使用infile>>占用了较多的时间,且输出格式使用c++的cout<<也比较耗时
单元测试
- TestMethod1:空文本
- TestMethod2:单字符文本
- TestMethod3:全空格文本
- TestMethod4:非字母与数字文本
- TestMethod5:单词全部大写文本
- TestMethod6:单词数字开头文本
- TestMethod7:最后一行有换行
- TestMethod8:单词长度小于4
- TestMethod9:汉字文本名
- TestMethod10:无输入

VS2015没有找到查看测试分支覆盖率的插件
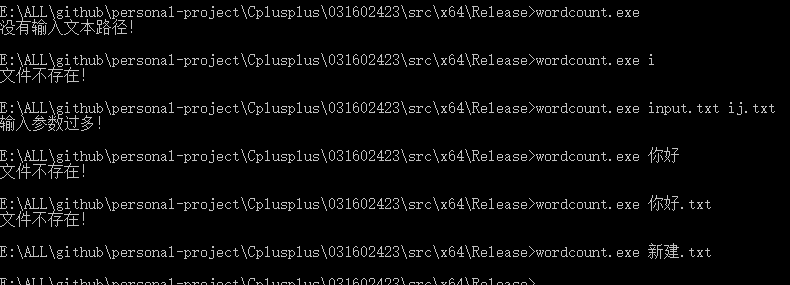
异常处理
可以处理基本的输入异常
总结
《构建之法》中提到的,“能证明所开发的软件是可以继续维护和发展的”,项目不仅仅做到满足用户需求,还要做到容易维护,无论是方便以后别人参与进来还是接手你的项目,都会更省时间。这次个人项目基本上我算是天天都在更新进度,我自己给自己的目标是一天完成一点功能,且对前一天的代码做一些优化。因为从了解到上手项目的时间还算比较长,所以总体来说还是比较顺利。反正感觉这次项目在文档整理上可能和其他同学还是有些差距,但我会总结这次的经验,争取下次做的更快更好。虽然是一次个人项目,但我还是得到了许多人的帮助,因为他们的解答和经验让我少走了很多弯路,希望我也能坚持在自己变强的过程中分享自己的历程和体会,以帮助更多的人。