目前正在使用tispark 进行离线计算,简单记录一下操作过程
一、技术验证
- 场景:计算每次充电过程中单体最高电压的变化速率
解决方案:
使用tispark 直接访问tidb的数据,采用spark的lag函数计算
SELECT billid,MAX(Diff) AS MaxHVDiff,MIN(Diff) AS MinHVDiff,
'20190801' AS bizdate FROM (SELECT upttime,billid,HighestVoltage , (HighestVoltage -lag(HighestVoltage ) over (PARTITION BY billid ORDER BY upttime)) AS Diff FROM ETL_SingleCharging
计算资源 :
/home/teld/tispark/spark-2.3.3-bin-hadoop2.7/bin/spark-shell --master=spark://***:7077 --executor-memory 32G 48核
计算结果:
参与计算的数据量: 451105735 –4.5亿
结果数据:6463684 –646万
时间:16分钟
监控资源
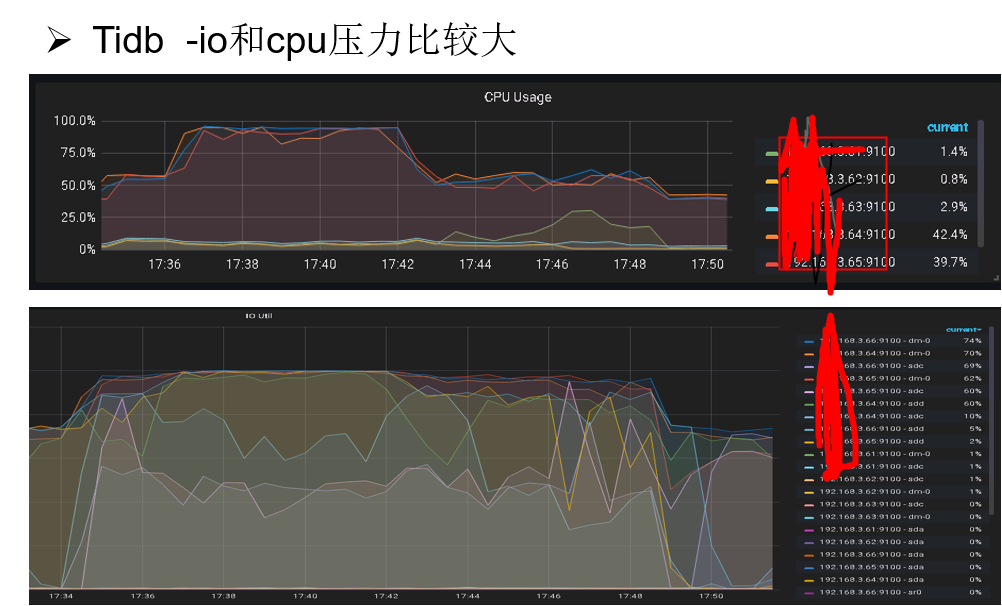
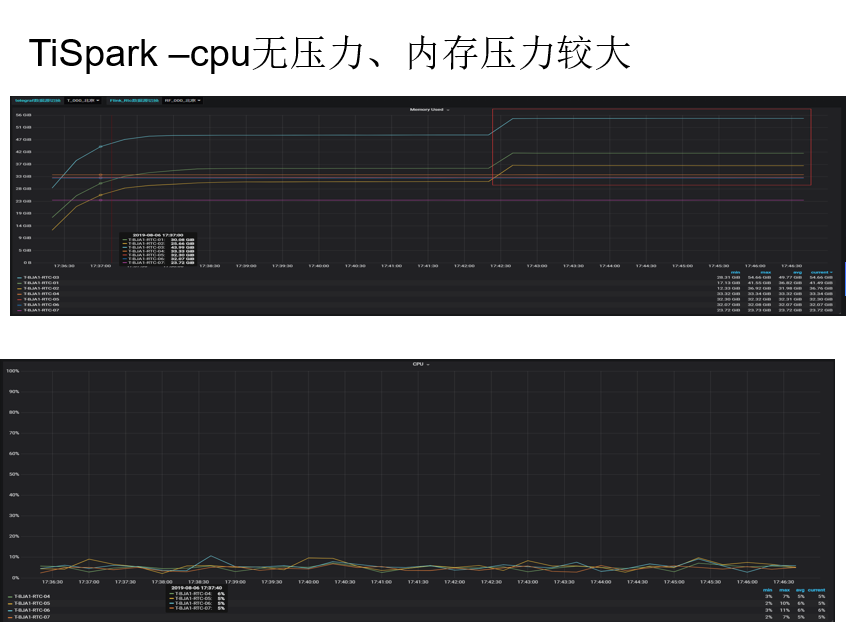
2. 相同的场景,将资源占用控制在 24G,36核心。 观察tispark 内存压力下降 --说明 tispark的资源占用可控
/home/teld/tispark/spark-2.3.3-bin-hadoop2.7/bin/spark-shell --master=spark://***:7077 --executor-memory 24G --total-executor-cores 36
二、生产部署
场景:生产环境需要计算每分钟的每个订单的充电的soc、温度、单体最高电压的变化速率,因此分析查找出异常的订单数据
生产解决方案:
2.1 整体思路:
通过计算平台的HUE上扩展TIspark的插件,实现tispark的相关操作,由于涉及到相关的临时表操作,因此在HUE的数据流里面还涉及到清楚临时表,导入数据到sqlserver等操作,因此还涉及kettle操作
2.2 实现方案:
1.数据流定义:
1.定义HUE数据流任务
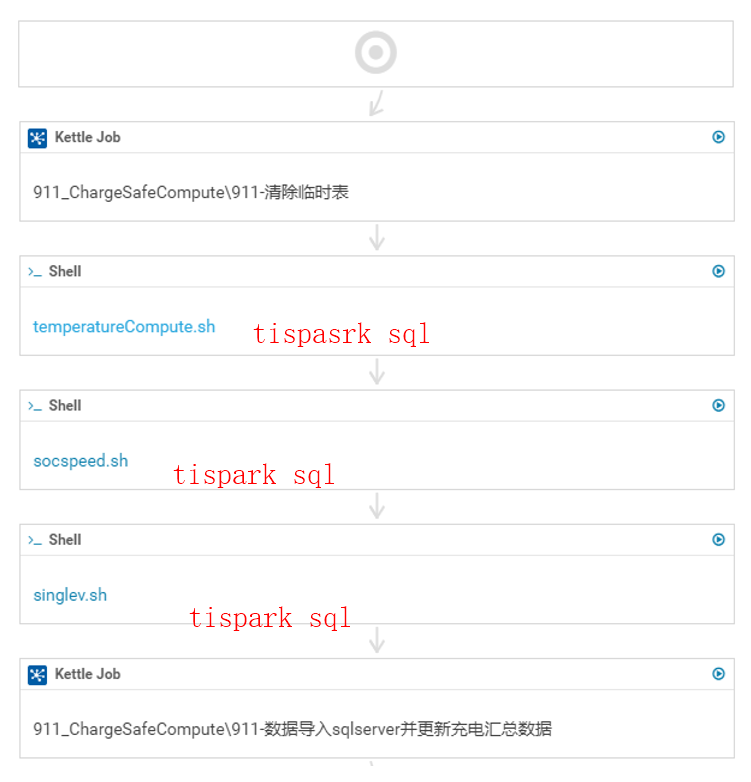
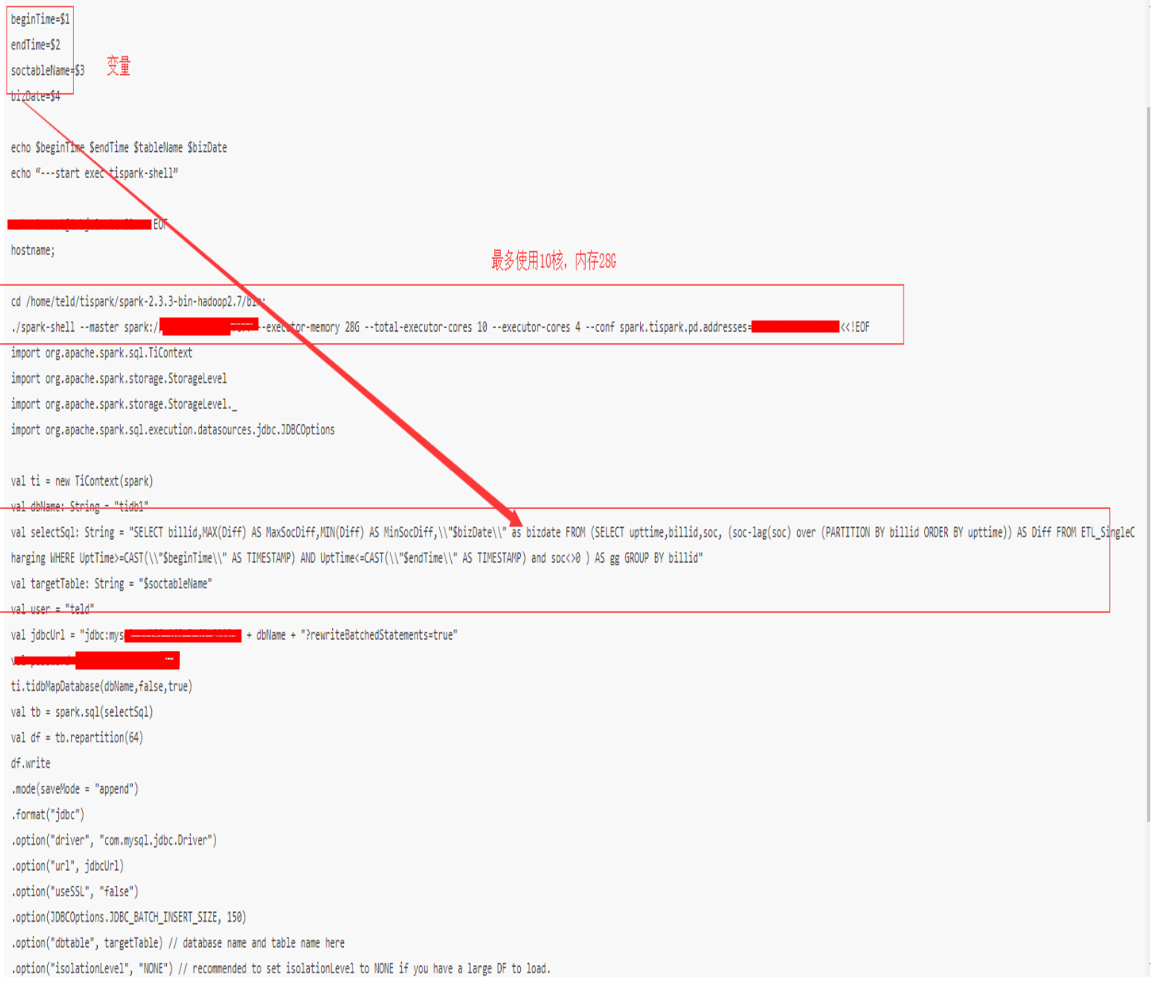
tispark sql --临时用shell 插件,扩张的hue上的tispark的插件正在开发
2.执行监控
每个sparksql 执行时间为2分钟
三 下一步规划
3.1 下一步逐步增加更深入的离线任务
3.2 tispark 的hue 更易用性的插件开发,并返回给社区
3.3 继续增加tidb的 oltp业务观察 tp和ap业务的 关系和对资源的占用冲突情况