一、大数据下的ETL工具是否还使用Kettle
kettle 作为通用的ETL工具,非常成熟,应用也很广泛,这里主要讲一下 目前我们如何使用kettle的?
在进行大数据处理时,ETL也是大数据处理的主要场景之一。 针对大数据下的ETL, 在大数据研究之初,曾经花费很大精力去寻找大数据下比较成熟的ETL工具,但是不多。主要分类如下:
-
- 开源的图形界面 类似 kettle 的nifi
- 命令形式的 如 sqoop、DataX
- 还有使用Spark 自定义开发ETL框架的
大数据下的ETL处理过程和传统关系型数据库下的ETL处理过程,我的理解本质还是一样的,要说区别 可能是大数据下需要ETL处理的数据速度足够快,这就要求可以充分利用分布式的能力,比如利用分布式的资源进行分布式的的计算。
基于使用经验和产品成熟度,在大数据下我们针对一些对数据处理速度不是非常之高的场景,我们仍然使用kettle。 这里我为什么不说数据量,因为对于一个ETL过程,说数据量是无意义的,好的ETL工具的核心引擎一定是一个类似现在的流式计算
也就是说数据向水一样的流动,流动的过程中做数据处理。也可kettle本身的含义类似。
基于个人的理解,任务kettle的优势主要体现在以下几点
- 设计时:
-
- 提供了成熟的图形界面,相比命令行形式的etl工具,更容易被推广应用
- 提供了丰富的各种数据库类型的插件,数据转换插件,涵盖场景众多
2.运行时
- 控制流和数据流的设计思想的划分
- 真正意义的数据流驱动的数据处理引擎,这一点也认为是同ESB等控制流产品不同的地方
- 通过多线程执行插件实例和分布式执行,提升执行速度
- 和目前大数据主流的数据库进行集成,当然这个地方主要还是集成调用
3.可扩展性
-
- 良好的插件架构,保证了设计时和运行时的可扩展性
4.待完善点
- kettle 任务定义多了,当数据结构发生变化时,需要修改较多,最好有统一的数据对象管理
- kette的图形化设计器虽然好用,但是web 化的设计器更容易多人使用,提升设计效率
目前kettle 的定位:
-
- 传统关系型数据库和大数据库之间数据导入导出
- 基于关系型数据库和大数据库由数据驱动的简单数据流任务
- 目前针对kettle做的扩展开发
- 插件开发
-
-
- 基于ES的sdk 开发ES的 input和output插件
- 封装支撑Druid 数据导出的input 插件
- 封装支持redis的插件
- 封装支持调用Kylin build job的插件
- 封装支持调用Tidb sql的插件
- 优化基于Azure wasb存储的hbase input 和output 插件
- 调度集成
- 大数据下的调度主要使用的Ooize,界面上主要使用HUE,通过扩展开发HUE 的插件的形式 调用Kettle的web服务进行调度集成
- 待完善点
- kettle的商业版中包含了元数据管理,下一步需要将kettle中使用的表和字段,和大数据的数据治理集成
- kettle处理日志通过ELK将日志采集到ES进行进一步的分析
- kettle web 提高kettle任务的定义效率
-
- 二、核心执行逻辑
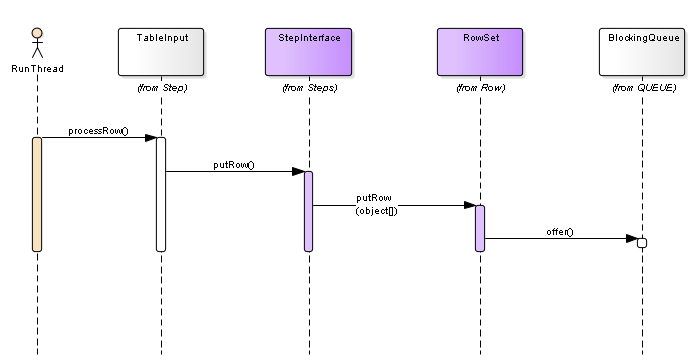
kettl的数据流处理过程,充分体现了其引擎对数据的流式处理过程。这里主要通过展现kettle 源码序列图的方式进行体现,希望大家可以通过这里的序列图了解其执行的基本原理,也就方便进行插件的扩展开发和日常问题的解决。
2.2 数据流处理核心逻辑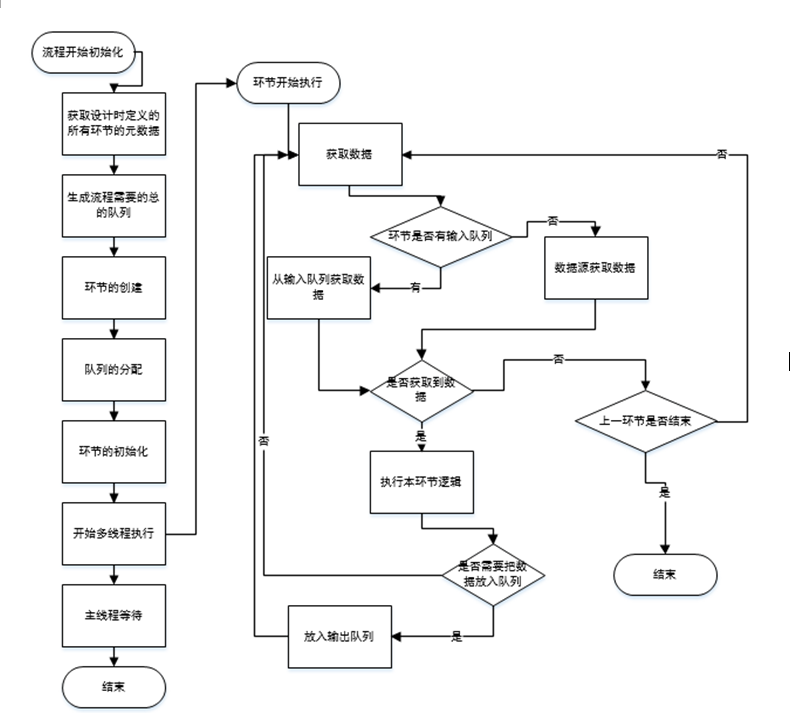
2.2 数据流处理的核心序列
2.2.1 任务的执行顶层序列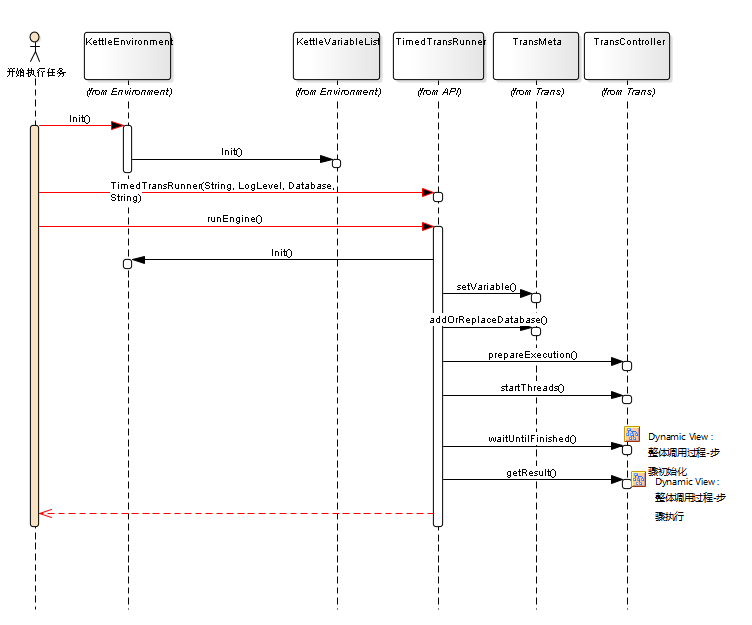
-
2.2.2步骤的初始化

- 2.2.3 步骤的执行
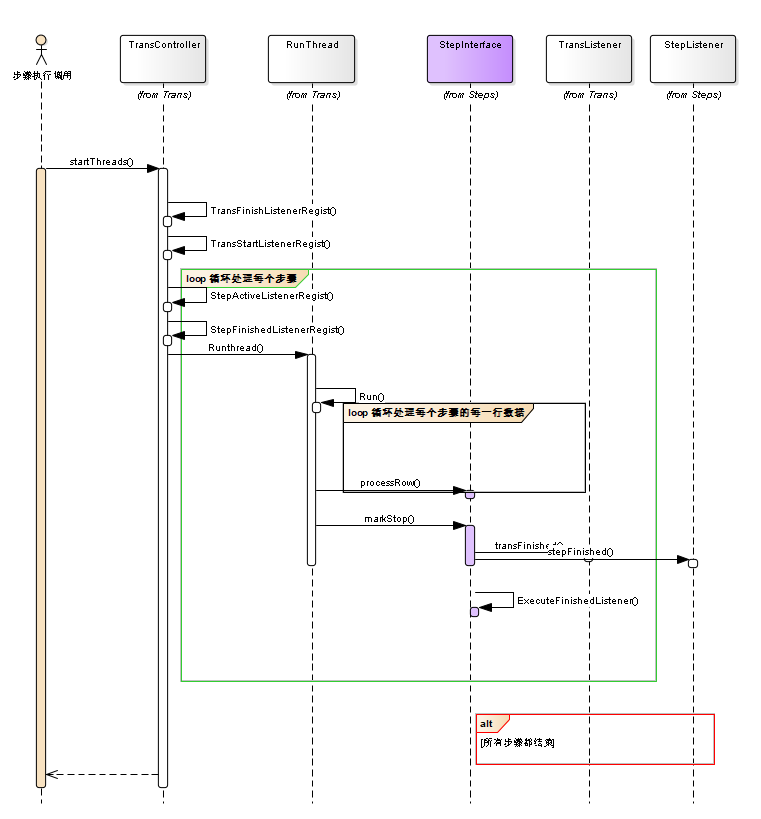
每个步骤队列的分配过程
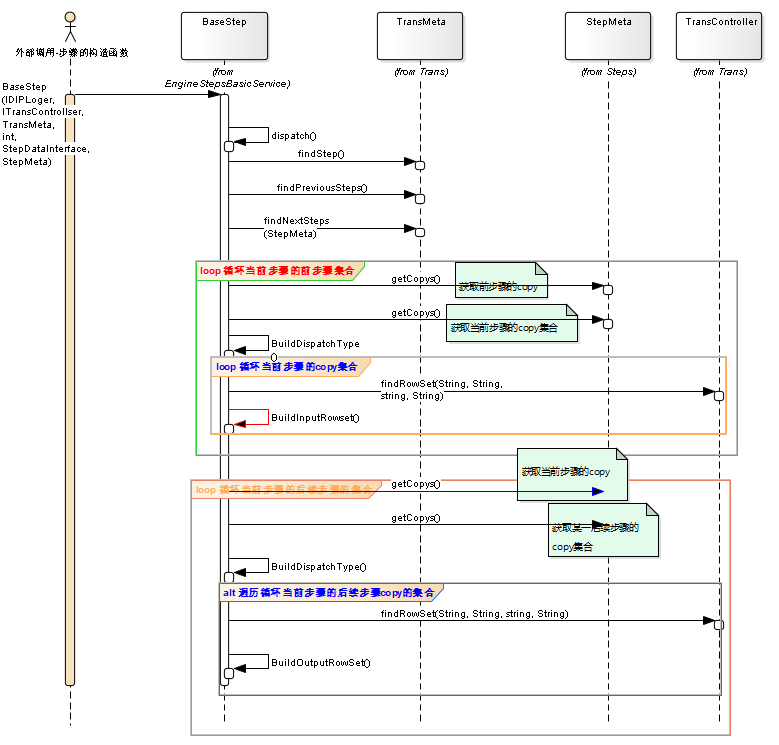
数据放入队列

- 2.2.4 具体步骤 -table input
2.2.5 table out put

以上 是kettle 核心数据流处理的核心过程。分享给大家