一、Hbase 写入慢时的集群异常指标
关于hbase写入优化的文章很多,这里主要记录下,生产hbase集群针对写入的一次优化过程。
hbase写入慢时,从hbase集群监控到的一些指标 -hbase 采用HDP 2.6 ,Hbase -1.1.2
- HBase的吞吐量 达到一个峰值之后,瞬间下降,无法稳定 ,对应的Grafana 面板-RPC Received bytes/s
- hbase 每台服务器的写入条数不均衡 ,对应监控面板 --Num Write Requests /s
- hbase的member store 一直维持在较小的数据,远没有达到机器 设置的 读写内容的比例,比如 读写内容各站0.4, 对应监控面板-Memstore Size
基于此 任务 目前的写入慢,并非集群硬件配置造成,而是hbase集群参数设计等设置有问题。
二、重新梳理了hbase了 写入流程
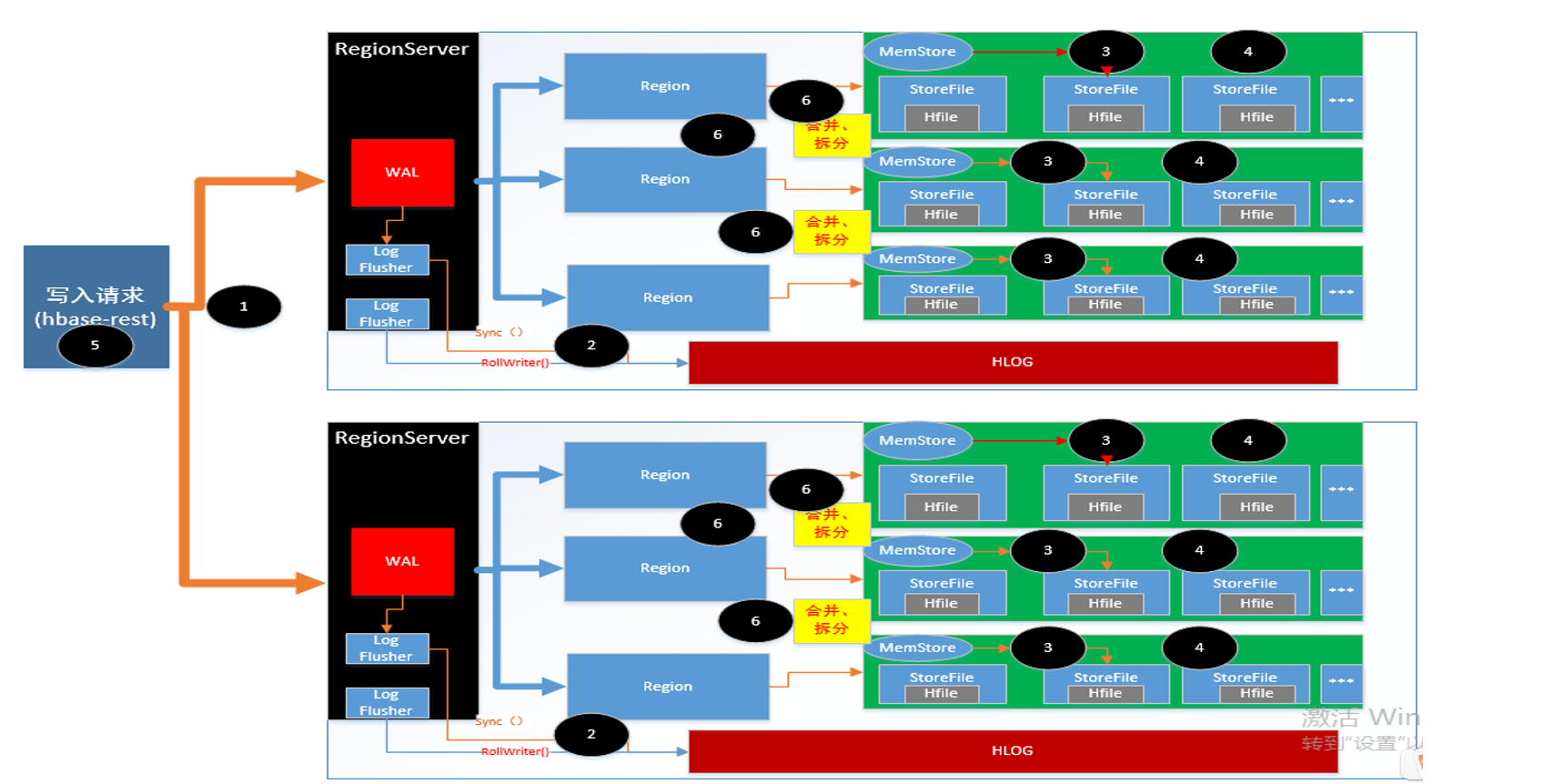
hbase 写入流程,这里就不在追溯,以上是根据理解,自己画的写入流程图 。可以查询的资料较多,这里推荐几个地址
hbase 社区 http://hbase.group/
w3c:https://www.w3cschool.cn/hbase_doc/hbase_doc-vxnl2k1n.html
牛人博客:https://www.iteblog.com/archives/category/hbase/
三、参数优化
基于以上,优化的思路主要分为如下
- 利用分布式集群优势,确保请求负载均衡
- 集群的RegionServer 在某些情况下会阻止数据的写入,尽量减少这种情况的发生
- 提高RegionServer 处理外部请求的能力
- 减少客户端和服务端ipc,请求的次数,可以批量写入的采用批量写入
- 增加hbaserest 端并行执行的能力
3.1 利用分布式集群优势,确保请求负载均衡
- 创建预分区
结合具体数据的RowKey特征创建预分区,注意:如果rowkey 业务数据为GUID,此时要注意guid 的首字母已经做了限制 即0-9 a-f 此时创建再多的分区,起作用的仅是0-9 a-f 开头的分区
create 'Monitor_RowDataMapping6','d', SPLITS => ['HSF.Response.Receive|', 'HSF.Response.Sent|', 'Teld.SQL|','HSF.Request.Time|', 'HSF.Request.Count|', 'HSF.Request.Receive|','HSF.Request.Sent|','Teld.Boss|','Teld.Core|','Teld.Redis|','Teld.WebApi|','TeldSG.Invoke|']
- rowkey的均衡
- 常用的方法:rowkey的哈希、rowkey的逆转、 当然 配套的查询也要做响应的修改
3.2 减少集群阻止写入的频率和时间
- 根据数据灵活调整WAL的持久化等级 --当然允许regionserver 重启之后数据可以丢一部分
WAL默认的等级为同步,会阻塞数据的写入,一般的持久化等级采用异步即可对于写入量很大的监控数据不在写入wal,alter 'Monitor_RowData', METHOD => 'table_att', DURABILITY => 'SKIP_WAL‘

- 调整 hbase.hstore.blockingStoreFiles 的大小,默认值为7, 生产环境调整到100000
Memstore 在flush前,会进行storeFile的文件数量校验,如果大于设定值,则阻止这个Memsore的数据写入,等待其他线程将storeFile进行合并,为了建设合并的概率,建设写入的阻塞,提高该参数值 -
由于region split 期间,大量的数据不能读写,防止对大的region进行合并造成数据读写的时间较长,调整对应的参数,
如果region 大小大于20G,则region 不在进行split
hbase.hstore.compaction.max.size 调整为20G 默认为 Long.MAX_VALUE(9223372036854775807) -
region server在写入时会检查每个region对应的memstore的总大小是否超过了memstore默认大小的2倍(hbase.hregion.memstore.block.multiplier决定),
如果超过了则锁住memstore不让新写请求进来并触发flush,避免产生OOM
hbase.hregion.memstore.block.multiplier 生产为8 默认为2 - 调整 hbase.hstore.blockingStoreFiles 的大小,默认值为7, 生产环境调整到100000
Memstore 在flush前,会进行storeFile的文件数量校验,如果大于设定值,则阻止这个Memsore的数据写入,
等待其他线程将storeFile进行合并,为了建设合并的概率,建设写入的阻塞,提高该参数值 - 增加hlog 同步到磁盘的线程个数
hbase.hlog.asyncer.number 调整大10 默认为5 -
写入数据量比较大的情况下,避免region中过多的待刷新的memstore,增加memstore的刷新线程个数
hbase.hstore.flusher.count 调整到20 默认为1
3.3 增加RegionServer 服务端的处理能力
- 针对目前每次写入的数据量变大,调整服务端处理请求的线程数量
hbase.regionserver.handler.count 默认值为10 调整到400
3.4 客户端请求参数设置
- 增加hbrest 并行处理的线程个数 ---写入部分是hbrest 服务写入
hbase.rest.threads.max 调整到400
- 采用hbase的批量写入
hbase.client.write.buffer 修改为5M