什么是 MQ?
Message Queue(MQ),消息队列中间件。很多人都说:MQ 通过将消息的发送和接收分离来实现应用程序的异步和解偶,这个给人的直觉是——MQ 是异步的,用来解耦的,但是这个只是 MQ 的效果而不是目的。MQ 真正的目的是为了通讯,屏蔽底层复杂的通讯协议,定义了一套应用层的、更加简单的通讯协议。一个分布式系统中两个模块之间通讯要么是 HTTP,要么是自己开发的 TCP,但是这两种协议其实都是原始的协议。HTTP 协议很难实现两端通讯——模块 A 可以调用 B,B 也可以主动调用 A,如果要做到这个两端都要背上 WebServer,而且还不支持长连接(HTTP 2.0 的库根本找不到)。TCP 就更加原始了,粘包、心跳、私有的协议,想一想头皮就发麻。MQ 所要做的就是在这些协议之上构建一个简单的“协议”——生产者/消费者模型。MQ 带给我的“协议”不是具体的通讯协议,而是更高层次通讯模型。它定义了两个对象——发送数据的叫生产者;接收数据的叫消费者, 提供一个 SDK 让我们可以定义自己的生产者和消费者实现消息通讯而无视底层通讯协议
消息队列的流派
-
有 Broker 的MQ
生产者/消费者模式一定伴随着者观察者模式。
这个流派通常有一台服务器作为 Broker,所有的消息都通过它中转。生产者把消息发送给它就结束自己的任务了,Broker 则把消息主动推送给消费者(或者消费者主动轮询)
-
重 Topic
kafka、JMS(ActiveMQ)就属于这个流派,生产者会发送 key 和数据到 Broker,由 Broker 比较 key 之后决定给哪个消费者。这种模式是我们最常见的模式,是我们对 MQ 最多的印象。在这种模式下一个 topic 往往是一个比较大的概念,甚至一个系统中就可能只有一个 topic,topic 某种意义上就是 queue,生产者发送 key 相当于说:“hi,把数据放到 key 的队列中”
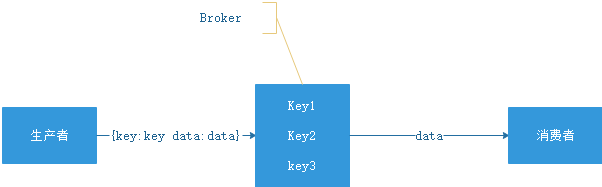
kafka 会丢数据。
虽然架构一样但是 kafka 的性能要比 jms 的性能不知道高到多少倍,所以基本这种类型的 MQ 只有 kafka 一种备选方案。如果你需要一条暴力的数据流(在乎性能而非灵活性)那么 kafka 是最好的选择
-
-
轻 Topic
这种的代表是 RabbitMQ(或者说是 AMQP)。生产者发送 key 和数据,消费者定义订阅的队列,Broker 收到数据之后会通过一定的逻辑计算出 key 对应的队列,然后把数据交给队列

AMQP 中有四种 exchange
-
Direct exchange:key 就等于 queue
-
Fanout exchange:无视 key,给所有的 queue 都来一份
-
Topic exchange:key 可以用“宽字符”模糊匹配 queue
-
Headers exchange:无视 key,通过查看消息的头部元数据来决定发给那个 queue(AMQP 头部元数据非常丰富而且可以自定义)
-
无 Broker 的 MQ
无 Broker 的 MQ 的代表是 ZeroMQ。该作者非常睿智,他非常敏锐的意识到——MQ 是更高级的 Socket,它是解决通讯问题的。所以 ZeroMQ 被设计成了一个“库”而不是一个中间件,这种实现也可以达到——没有 Broker 的目的

节点之间通讯的消息都是发送到彼此的队列中,每个节点都既是生产者又是消费者。ZeroMQ 做的事情就是封装出一套类似于 Socket 的 API 可以完成发送数据,读取数据
ZeroMQ 其实就是一个跨语言的、重量级的 Actor 模型邮箱库。你可以把自己的程序想象成一个 Actor,ZeroMQ 就是提供邮箱功能的库;ZeroMQ 可以实现同一台机器的 RPC 通讯也可以实现不同机器的 TCP、UDP 通讯,如果你需要一个强大的、灵活、野蛮的通讯能力,别犹豫 ZeroMQ
为什么要用 MQ?
-
异步处理
比如用户注册后需要发送短信和邮件,新手会怎么写那?新手会把所有业务写成串行化,注册成功后发邮件,发短信。缺点是会把接口的时间拖的很慢。
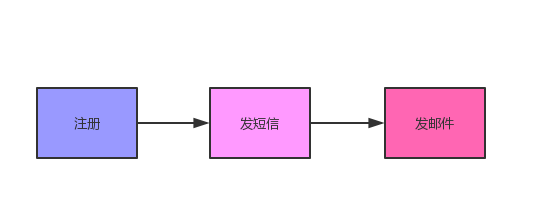
如何解决和优化那?
发送邮件和短信完全可以异步处理,注册成功,发个消息消息中间件后直接返回,让中间件去异步的发邮件和短信。

-
应用解藕
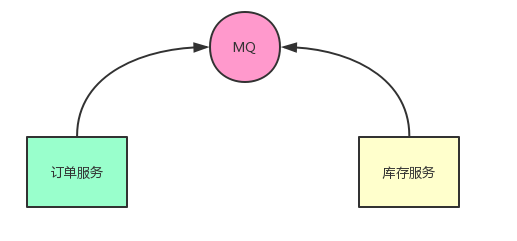
比如在分布式系统中,我们有订单服务,库存服务等等。我们订单服务下完单后通过 rpc 调用库存系统。假如你的库存系统挂了,你的订单是不是就失败了?
解决办法还是加一个消息中间件。使用发布订阅模式。
系统的耦合性越高,容错就越低。比如订单系统要去调用支付系统,库存系统和物流系统,如果任何一个系统高异常都会影响用户体验。
加入 MQ 后,比如物流系统出现异常,可以将物流消息暂时存在 MQ 中,不影响用户正常下单,等物流系统恢复后继续执行(分布式事务的概念)。
-
流量削峰
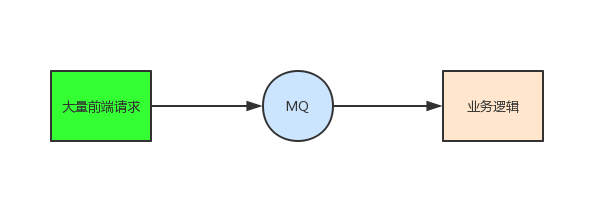
应用系统如果遇到系统请求流量的瞬间猛涨,有可能会将系统压垮,有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提高系统的稳定性和用户体验。
如果业务系统正常时段的 QPS 是 1000,流量最高峰是 10000,请求超过某个阀值后对流量进行削峰处理。
-
MQ 的优点和缺点
优点:解藕,削峰,数据分发。
缺点:
- 系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦 MQ 宕机,就会对业务造成影响。 - 系统复杂度提高
- 一致性问题
A 系统处理完业务,通过 MQ 给 B,C,D 三个系统发消息数据,如果 B,C 处理成功,D 系统处理失败。如何保证消息数据处理的一致性?
Push 和 Pull 模型
- Push 模型,即当 Producer 发出的消息到达后,服务端马上将这条消息投递给 Consumer。
- Pull 模型,指的是服务端接收到这条消息后什么也不做,只是等着 Consumer 主动到自己这里来读,即 Consumer 这里有一个 “拉取” 的动作。
RocketMQ 的角色介绍
- Producer:消息发送者。
- Consumer:消息接收者。
- Broker:暂存和传输消息,像邮局。
- NameServer:管理 Broker,命名服务。
- Topic:区分消息的种类,一个发送者可以发送消息给一个或者多个多个 Topic,一个消息的接受者可以订阅一个或者多个 Topic 消息。
- Message Queue:相当于是 Topic 的分区,用于并行发送和接收消息。
持久化

- 消息生成者发送消息
- MQ 收到消息,将消息进行持久化,在存储中新增一条记录
- 返回 Ack 给生产者
- MQ push 消息给对应的消费者,然后等待消费者返回 Ack
- 如果消息消费者在指定时间内返回 Ack,那么 MQ 会认为消息消费成功,在存储中删除消息,即执行第 6 步。如果 MQ 在指定时间内没有收到 Ack,则认为消息消费失败,会尝试重新 push 消息,重复执行 4,5,6 步骤。
- MQ 删除消息
存储介质
- 关系型数据库(ActiveMQ,数据库的 IO 读写性能往往会出现瓶颈)。
- 文件系统(RocketMQ/Kafka/RabbitMQ 均采用的是消息刷盘至所部属虚拟机/物理机的文件系统来做初始化,刷盘可以采用同步/异步两种模式)。
- RocketMQ 写文件时采用顺序写,最高 600M/s,随机写只有 100KB/s。RocketMQ 采用了零拷贝技术,提高了消息存盘和网络发送的速度。
消息存储结构
RocketMQ 消息的存储是由 ConsumerQueue 和 CommitLog 配合完成的,消息真正的物理存储文件是 CommitLog,ConsumerQueue 是消息的逻辑队列,类似数据库的索引文件,存储指向物理存储的地址。每个 Topic 下的每个 MessageQueue 都有一个对应的 ConsumerQueue 文件。
刷盘机制
RocketMQ 为了提高性能,会尽可能的保证磁盘的顺序写,消息在通过 Producer 写入 RocketMQ 的时候,有两种写磁盘方式,分布式同步刷盘和异步刷盘。
-
同步刷盘
在返回写成功状态时,消息立即被写入磁盘。具体流程是,消息写入内存的 PAGECACHE 后,立刻通知刷盘线程刷盘,然后等刷盘完成,刷盘线程执行完成后换行等待的线程,返回消息写成功的状态。
-
异步刷盘
在返回写成功状态时,消息可能只是被写入了内存的 PAGECACHE,写操作的返回快,吞吐量达,当内存里的消息积累到一定程度时,统一出发写磁盘动作,快速写入。
高可用机制
RocketMQ 分布式集群是通过 Master 和 Slave 的配合达到高可用性的。
Master 角色的 Broker 支持读和写,Slave 角色的 Broker 仅支持读,也就是 Producer 只能和 Master 角色的 Borker 连接写入消息。Consumer 可以连接 Master 角色的 broker,也可以连接 Slave 角色的 Broker 来读取消息。
消费端的高可用,默认先从 Master 读,当 Master 角色出现故障后,Consumer 仍然可以从 Slave 读取消息,达到了消费端的高可用。
双主从机制保证了发送消息的高可用。
消息主从复制
-
同步复制
同步复制方式是等 Master 和 Slave 均写成功后才反馈给客户端写成功状态。
同步复制方式下,如果 Master 出故障,Slave 上有全部的备份数据,容易恢复,但是同步复制会增大数据写入延迟,降低系统吞吐量。
-
异步复制
异步复制方式只要 Master 写入成功即可反馈给客户端写入成功状态。
在异步复制方式下,系统拥有较低的延迟和较高的吞吐量,但是如果 Master 出了故障,有些数据因为没有被写入 Slave,又可能会丢失。
-
一般把刷盘配置成异步的,主从之间同步配置成同步的,这样即使有一台机器出故障,仍然能保障数据不丢失,是个不错的选择。
负载均衡
Producer 端,每个实力在发送消息的时候,默认会轮训所有 message queue 发送,以达到让消息平均落在不同的 queue 上,而由于 queue 可以散落在不同的 broker,所以消息就发送到不同的 broker 下。

Consumer 负载均衡
-
集群模式
在集群消费模式下,每条消息只需要投递到订阅这个 topic 的 Cosnuemr Group 下的一个实例即可。RocketMQ 采用主动拉取并消费消息,在拉取的时候需要明确指定拉取哪一条 message queue。
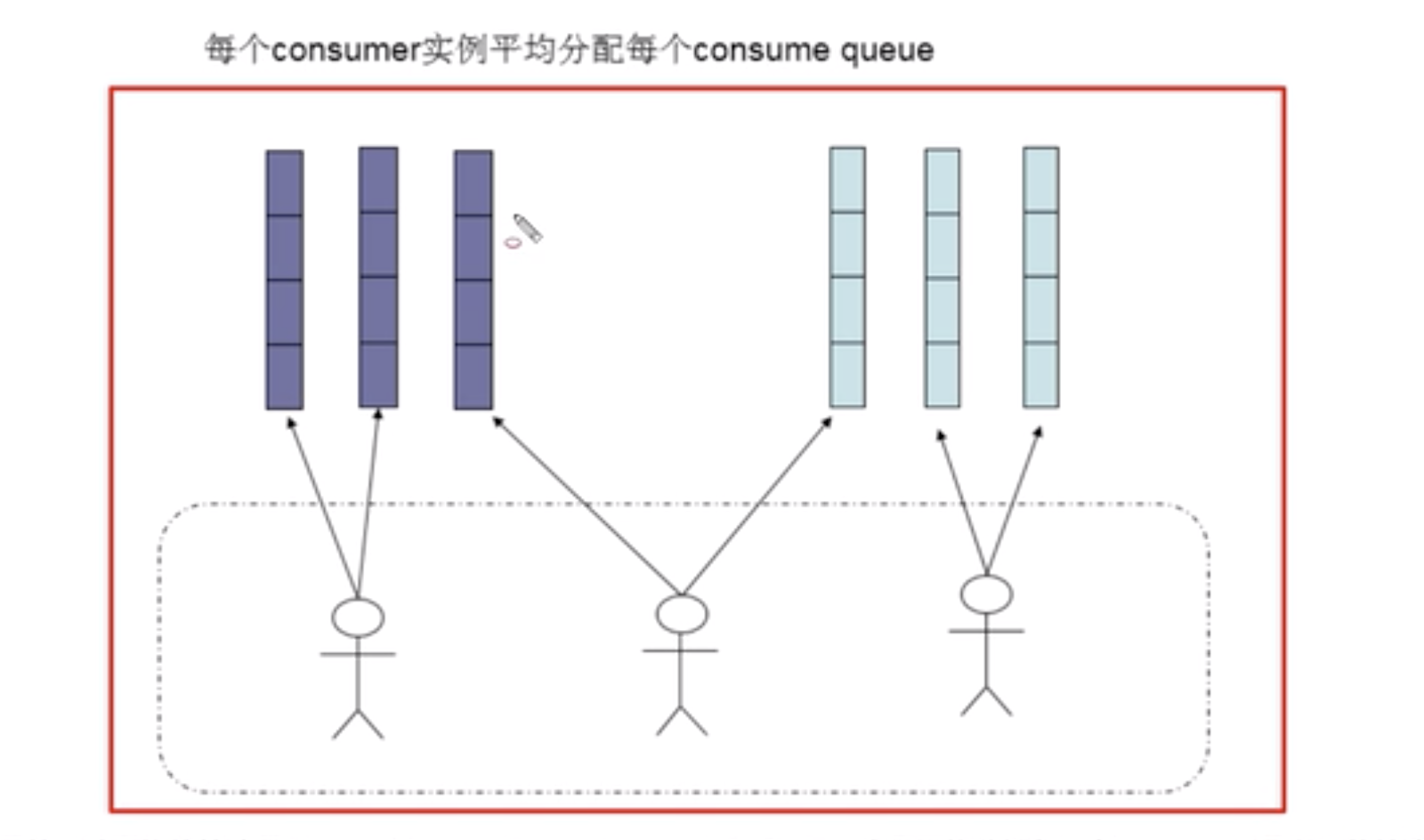

消息重试
-
顺序消息的重试
对于顺序消息,当消费者消费消息失败后,消息队列 RocketMQ 会自动不断进行消息重试,这时,应用会出现消息消费被阻塞的情况。因此,在使用顺序消息时,无比保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生。
-
无序消息的重试
对于无序消息(普通,定时,延时,事务消息),当消费消费消息失败时,您可以通过设置返回状态达到消息重试的结果。
死信队列
当一条消息消费失败,消息队列 RocketMQ 会自动进行消息重试,达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列 RocketMQ 不会立刻将消息丢弃,而是发送到死信队列中。
消费幂等
消息队列 RocketMQ 消费者在接收到消息以后,有必要根据业务上的唯一 Key 对消息做幂等处理的必要性。互联网应用中,尤其是网络不稳定情况下,消息队列 RocketMQ 的消息可能会出现重复:
- 发送消息重复
- 投递消息重复
- 负载均衡时消息重复
因为 Message ID 又可能出现冲突的情况,所以真正的安全的幂等处理,不建议以 Message ID 作为处理依据,最好方式是以业务唯一标识作为幂等的关键依据,而业务的唯一标示可以通过消息 Key 进行设置。