Queue
队列是一种支持 FIFO 的数据结构或者容器。Queue 接口下面的实现类包括 Deque,非阻塞队列和阻塞队列。
PriorityQueue
PriorityQueue 是一个基于优先级的无界队列。比如我们的作业系统中,当一个作业完成后,在所有等待调度的作业中选择一个优先级最高的作业来执行,并且可以添加新的作业到优先队列中。
特点:
- 元素按照自然顺序进行排列或者根据传入的 Comparator 进行排序。
- 不允许插入 null 或者不可比较的对象(没有实现 Comparable 接口的对象)。
- 优先级队列的头部元素最小(底层是一个最小堆)。
- 底层实现是一个数组,会根据元素的数量进行扩容。
- 线程不安全的
方法分析:
先来看这个优先级队列的构成,我们发现了一个非常重要的问题,就是优先级队列的底层是一个数组。
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
transient Object[] queue; //队列容器, 默认是11
private int size = 0; //队列长度
private final Comparator<? super E> comparator; //队列比较器, 为null使用自然排序
//....
}
PriorityQueue 通过最小堆来实现,可以用一颗完全二叉树来表示。
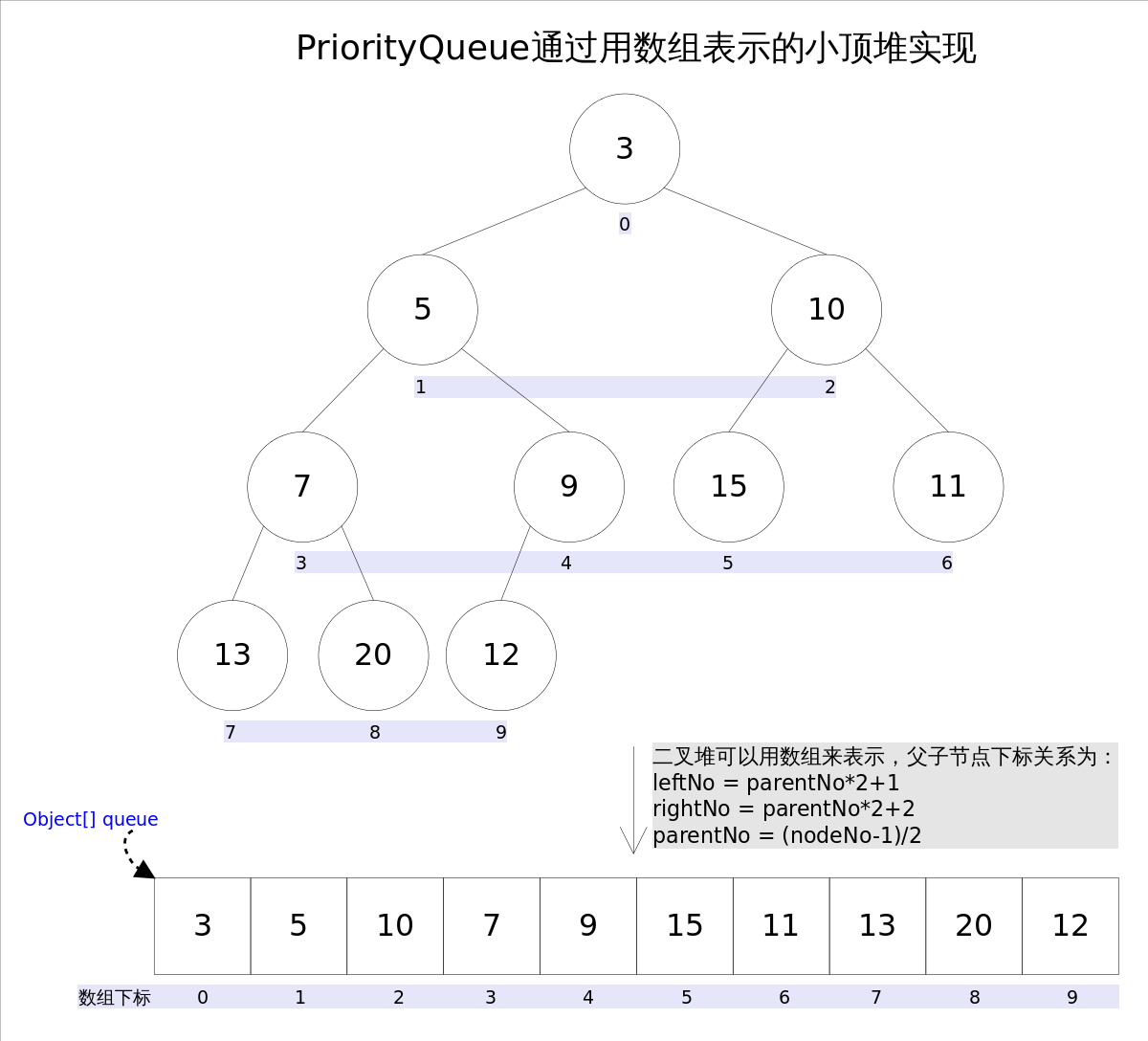
通过数组就完全可以表示上面的二叉树。所以 PriorityQueue 的 peek 和 element 方法来获取第一个元素的时间复杂度都是常数级别,而增加和删除的复杂度为 log(N)。
add 和 offer
add 和 offer 都是像数组中插入元素,新加入的元素会放入到数组的最后一个位置,然后根据优先级对最小堆进行调整。
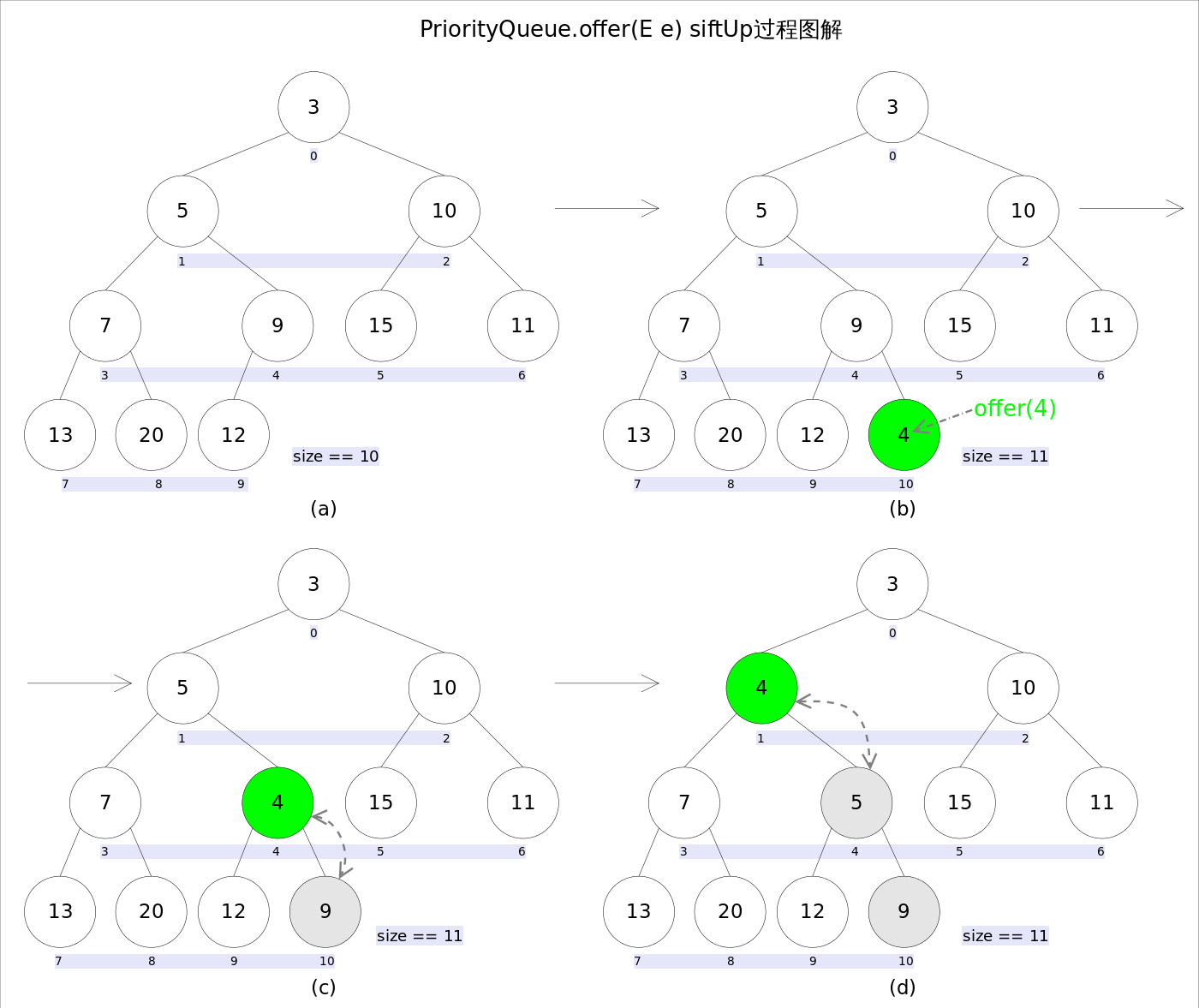
//offer(E e)
public boolean offer(E e) {
if (e == null)//不允许放入null元素
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);//自动扩容
size = i + 1;
if (i == 0)//队列原来为空,这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e);//调整
return true;
}
element 和 peek
这两个方法的语义完全相同,都是获取队首元素且不删除,所以直接返回数组下标为 0 的元素即可。
//peek()
public E peek() {
if (size == 0)
return null;
return (E) queue[0];//0下标处的那个元素就是最小的那个
}
remove 和 poll
remove 和 poll 方法的作用就是删除队首元素。删除了这个元素后,为了维护最小堆的特性,会进行调整。
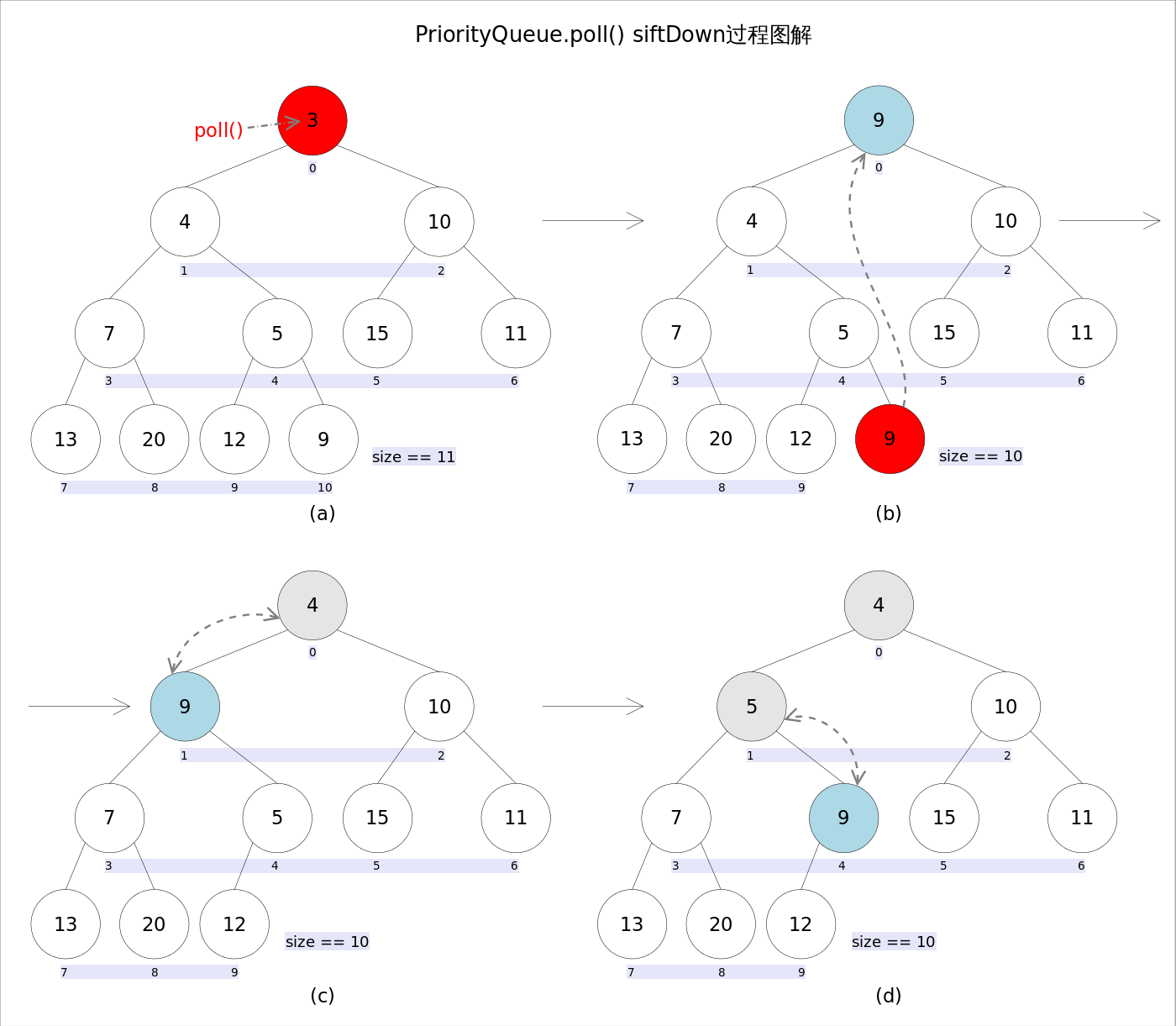
使用最后一个元素替换队首的元素,然后使用 siftDown 方法进行调整。siftDown 的作用是从最后当前第一个元素开始,与左右孩子中较小的一个进行比较,知道小于或等于左右孩子中的任意一个为止。
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}
remove
remove(Object o) 用于删除队列中跟 o 相等的某一个元素(如果有多个,只删除一个)。删除会改变队列结构,所以需要进行调整。如果删除的是最后一个元素,直接删除即可。如果不是最后一个元素,把最后一个元素放入到它的位置再进行 siftDown 即可。

//remove(Object o)
public boolean remove(Object o) {
//通过遍历数组的方式找到第一个满足o.equals(queue[i])元素的下标
int i = indexOf(o);
if (i == -1)
return false;
int s = --size;
if (s == i) //情况1
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);//情况2
......
}
return true;
}
ConcurrentLinkedQueue
ConcurrentLinkedQueue 是 Doug Lea 为我们准备的一个并发容器,是一个线程安全的队列。
特点:
- 线程安全的并发容器
- 底层基于 CAS 实现。
- 底层的数据接口是链表。
方法分析:
Node 类的源码,里面包含的属性一个是值,另一个是指向下一个节点的引用。
private static class Node<E> {
volatile E item;
volatile Node<E> next;
.......
}
ConcurrentLinkedQueue 包含了一个头指针,一个尾指针。
在队列进行入队,出队的时候免不了对节点进行操作,在处理器执行集能够支持 CMPXCHG 指令后,在 java 源码涉及到并发处理都会使用 CAS 操作。下面列举了几个针对 Node 的 CAS 操作。
//更改Node中的数据域item
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
//更改Node中的指针域next
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
//更改Node中的指针域next
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
UNSAFE 是虚拟机底层提供的方法,我们知道 CAS 是由它实现的即可。
offer
先假设我们要插入两个元素:
1. ConcurrentLinkedQueue<Integer> queue = new ConcurrentLinkedQueue<>();
2. queue.offer(1);
3. queue.offer(2);
先来看 offer 方法的源码。
public boolean offer(E e) {
//e为null则抛出空指针异常
1 checkNotNull(e);
//构造Node节点构造函数内部调用unsafe.putObject,后面统一讲
2 final Node<E> newNode = new Node<E>(e);
//从尾节点插入
3 for (Node<E> t = tail, p = t;;) {
4 Node<E> q = p.next;
//如果q=null说明p是尾节点则插入
5 if (q == null) {
6 //cas插入(1)
7 if (p.casNext(null, newNode)) {
//cas成功说明新增节点已经被放入链表,然后设置当前尾节点(包含head,1,3,5.。。个节点为尾节点)
8 if (p != t) // hop two nodes at a time
9 casTail(t, newNode); // Failure is OK.
10 return true;
}
// Lost CAS race to another thread; re-read next
}
11 else if (p == q)//(2)
//多线程操作时候,由于poll时候会把老的head变为自引用,然后head的next变为新head,所以这里需要
//重新找新的head,因为新的head后面的节点才是激活的节点
12 p = (t != (t = tail)) ? t : head;
else
// 寻找尾节点(3)
13 p = (p != t && t != (t = tail)) ? t : q;
}
}
-
第一行代码对传入的元素进行 null 判断。
-
讲 e 包装成一个 node 节点。
-
通过 for 循环进行 CAS 操作,这个 for 循环只有初始化条件,没有结束条件,这很符合 CAS 的套路(在循环体中 CAS 成功会直接 return 返回,失败就在 for 循环中不断重试直至成功)。这里 t 被初始化为 tail,p 被初始化为 t,即 tail。
-
如果 p 的下一个节点为 null,则 p 就是当前的尾节点,使用 casNext 将我们新建的 node 设置成尾节点 p 的 next 节点。如果 casNext 的操作失败则在循环中重试。
-
此时 p == t,直接返回,队列中插入了第一个元素。
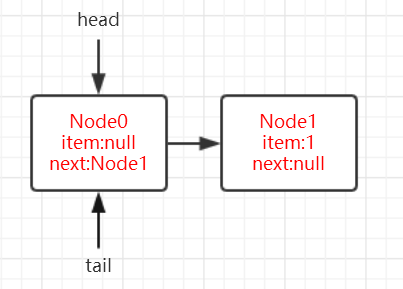
-
此时的队尾尾 node1,而 tail 节点依然指向了 node0。
下面我们继续插入第二个元素。
- 插入第二个元素走到第四行时,q 就不是 null 了,而是 node1。
- 第五行为 false。
- 第十一行为 false。
- 此时代码走到了第十三行。这里说明我们在插入元素的时候,tail 可能并不是真正的队尾节点,所以第十三行的作用是找到真正的队尾节点,然后将 p 的引用指向它。
- 第十三行代码在单线程的环境中执行时,p == t,所以 p 被赋值为 q,也就是 node1。
- 再次循环。通过 casNext 将 p 的 next 设置为新增的 node。
- 走到第八行,这时 p!=t,会通过 casTail 将当前节点 node 设置为队尾节点。
- 我们发现第九行的注释里面写 CAS failed 也可以,原因是我们通过 p 的下一个节点是否为 null 来判断后面的逻辑,如果 第九行失败,下面插入的元素多进行几步第十三行的操作就可以了。
我们回头来看寻找尾节点的逻辑,p = (p != t && t != (t = tail)) ? t : q,这段代码永远不会将 p 赋值为 t,因为在单线程中 p 一直等于 t。我们来看看多线程环境下的执行情况。
offer->pull->offer
- 线程 A 读取了变量 t,t 指向队尾。
- 线程 B 刚好在这个时候 offer 了一个 node 之后,tail 发生了变化。此时 p != t。
- 此时 t != tail, 最后将 tail 赋值为 t。这时 t 就指向了最新的队尾节点。然后就可以执行 offer 操作了。
第十一行代码等我们学习完 poll 的源码之后再来看。
poll
public E poll() {
restartFromHead:
1. for (;;) {
2. for (Node<E> h = head, p = h, q;;) {
3. E item = p.item;
4. if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
5. if (p != h) // hop two nodes at a time
6. updateHead(h, ((q = p.next) != null) ? q : p);
7. return item;
}
8. else if ((q = p.next) == null) {
9. updateHead(h, p);
10. return null;
}
11. else if (p == q)
12. continue restartFromHead;
else
13. p = q;
}
}
}
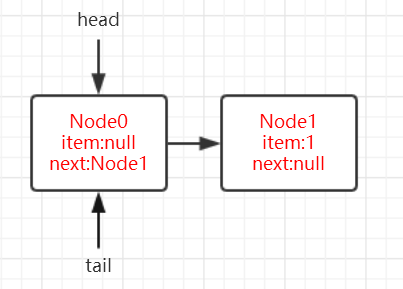
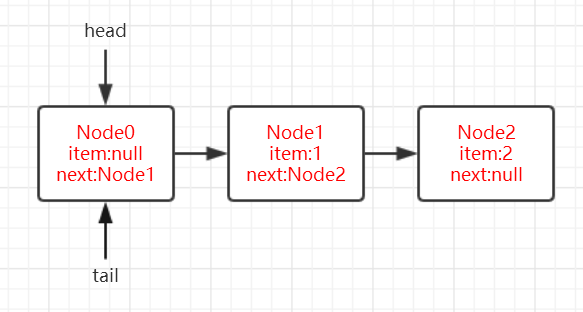
首先假设加入完两个元素后的队列状态如下,tail 没有更新。
- 我们还是把 p 作为要删除的真正的头节点,h 指向的并不一定是头节点。
- 由于 p=h=head,此时第四行代码的 item!=null 为 true,接下来通过 casItem 将 node1 的数据值设置为 null。
- 如果 CAS 失败则继续循环。
- 进入第五行时,p 和 h 都指向 node1,因此为 false。直接返回刚才的值。
运行之后的结果。

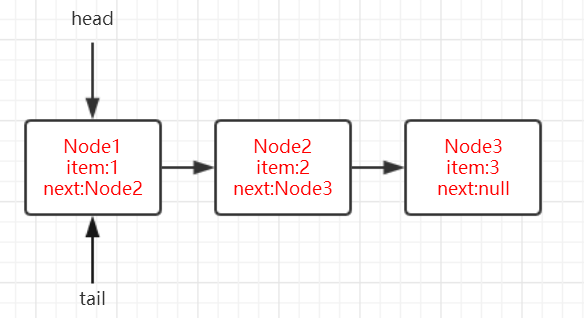
继续 poll。
- 此时 h 和 p 指向的节点的数据值为 null,要重新定位头节点(找到数据值不为 null 的节点)。
- 走到第八行代码,q 指向了 node2。然后走到第十三行代码,这时 p 和 q 同时指向了 node2。
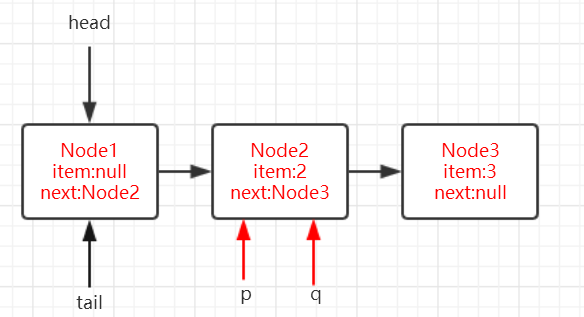
进行下一次循环。
- 第四行将 p 的 item 设置为 null。
- 因为 p 指向了 node2,而 h 还是 node1,因此第五行为 ture。
- 将 head 指向 node3,同时通过 h.lazySetNext 将 node1 的 next 指向他自己。
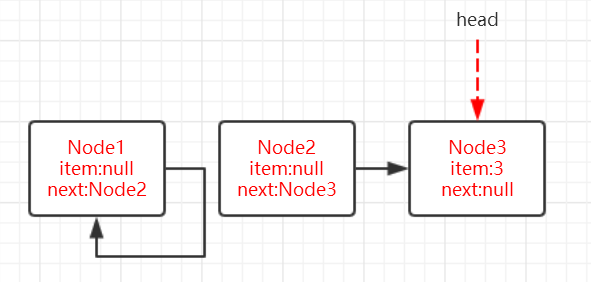
再来看多线程情况下需要注意的点:
else if (p == q)
continue restartFromHead;
上一个判断 q = p.next 就是说 q 是 p 的下一个节点,那么什么时候 q 会等于 p 那?只有 p 指向的节点被 lazySetHead 了之后。即 A 在判断 p==q 时,线程 B 已经 poll 完,并且将 p 指向节点变为了 lazySetHead 的节点。所以使用 continue restartFromHead 来保证拿到最新的 head。
offer 方法最后的补充
对于 offer 方法的第十一行代码,我们来做一个补充。假设队列的初识状态如下。
在 offer 方法的执行过程中,当 p 指向第一个节点时,此时第一个节点恰巧被 poll 了,这个节点变为一个哨兵节点。
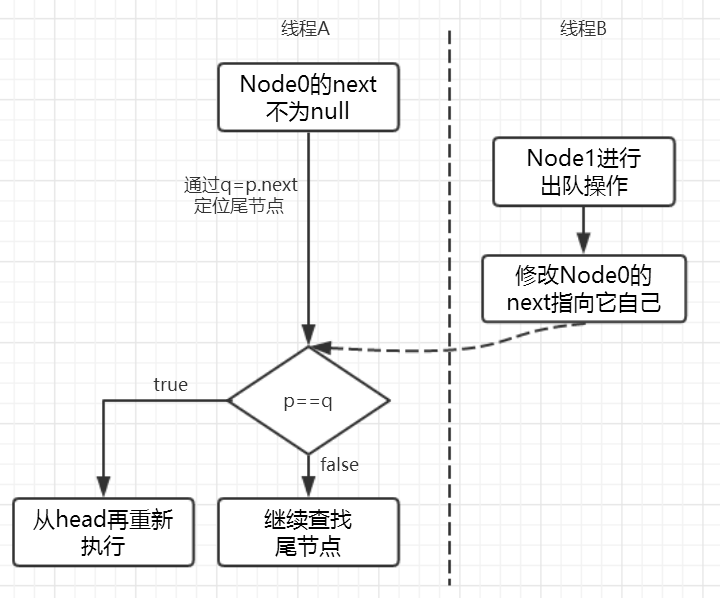
这里会重新寻找 head 节点。
更新机制
对于 offer 和 poll 方法,我们发现 tail 和 head 是延迟更新的。源码中的注视为 hop two node at a time。如果让 tail 永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是会有新能损耗。如果能够减少 CAS 的更新操作,无疑可以提升效率。