隔了好久,才想起来更新博客,最近倒腾的数据库从Oracle换成了MySQL,研究了一段时间,感觉社区版的MySQL在各个方面都逊色于Oracle,Oracle真的好方便!
好了,不废话,这次准备记录一些关于MySQL分布式集群搭建的一个东东,MyCAT,我把他理解为一个MySQL代理。
-----------------------------------------------------------------重要的TIPs-----------------------------------------------------------------------
MyCAT的团队已经发布了1.4Alpha版本,这其中修复了不少的bug,也添加了新功能,
博主这边测试用的是1.3的版本,所以和最新版本的测试结果可能出现不一致!
-------------------------------------------------------------------背景介绍------------------------------------------------------------------
MyCAT的背景介绍直接略过,没啥用,当然,这是一个由JAVA开发的东东,这一点需要了解~。
-----------------------------------------------------------------MyCAT的前身----------------------------------------------------------------
MyCAT的前身,是阿里巴巴于2012年6月19日,正式对外开源的数据库中间件Cobar,Cobar的前身是早已经开源的Amoeba,不过其作者陈思儒离职去盛大之后,阿里巴巴内部考虑到Amoeba的稳定性、性能和功能支持,以及其他因素,重新设立了一个项目组并且更换名称为Cobar。Cobar是由 Alibaba 开源的 MySQL 分布式处理中间件,它可以在分布式的环境下看上去像传统数据库一样提供海量数据服务。
Cobar自诞生之日起, 就受到广大程序员的追捧,但是自2013年后,几乎没有后续更新。在此情况下,MyCAT应运而生,它基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能,以及众多成熟的使用案例使得MyCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,MyCAT能看到更远。
---------------------------------------------------------MyCAT的下载方式--------------------------------------------------------------------
MyCAT的SVN地址为:http://code.taobao.org/svn/openclouddb/
---------------------------------------------------------MyCAT的重要特性--------------------------------------------------------------------
支持 SQL 92标准;
支持MySQL集群,可以作为Proxy使用;
支持JDBC连接ORACLE、DB2、SQL Server,将其模拟为MySQL Server使用;
支持galera for mysql集群,percona-cluster或者mariadb cluster,提供高可用性数据分片集群;
自动故障切换,高可用性;
支持读写分离,支持MySQL双主多从,以及一主多从的模式;
支持全局表,数据自动分片到多个节点,用于高效表关联查询;
支持独有的基于E-R 关系的分片策略,实现了高效的表关联查询;
多平台支持,部署和实施简单。
------------------------------------------------------------MyCAT的体系结构----------------------------------------------------------------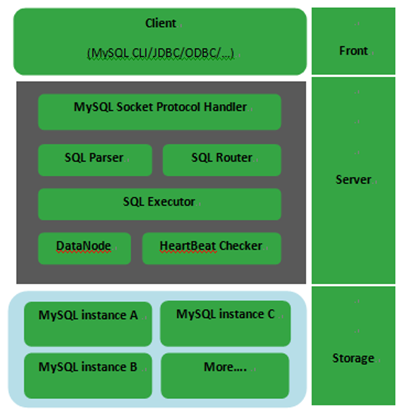
总体上分成三个部分,最前端的是连接器,线程管理使用了资源池,并且默认采用了AIO的方式(这些基本信息可以再启动日志里面看到);
中间层在图中已经描述的很清楚了,SQL解析器+SQL路由,SQL Executor需要具体看源码才能了解,因为通过这段时间对MyCAT的测试,没有感觉到SQL Executor的存在,更多的感觉是一个SQL process的东西,DataNode和心跳检测算是中间层实现的两个组件,一个是和MySQL的库(注意,不是实例)相关,一个是常见的监测机制的功能模块;
最下层的存储就是是MySQL的集群了~怎么玩MySQL的集群,由我们自己决定╰(?? ▽ ??)╯。
MyCAT目前通过配置文件的方式来定义逻辑库和相关配置,主要是包括三个文件:
MYCAT_HOME/conf/schema.xml中定义逻辑库,表、分片节点等内容;
MYCAT_HOME/conf/rule.xml中定义分片规则;
MYCAT_HOME/conf/server.xml中定义用户以及系统相关变量,如端口等。
不着急,这一篇简单介绍这几个配置文件的作用和一些参数的意义。
一个一个来,先看schema.xml,这是从网上摘抄的一个示例模板
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <schema name="weixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="weixin" > <schema name="yixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="yixin" /> <dataNode name="dn1" dataHost="localhost0" database="weixin" /> <dataNode name="dn2" dataHost="localhost0" database="yixin" /> <dataHost name="localhost0" maxCon="450" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="localhost:3306" user="root" password="123456" /> <readHost host="hostS1" url="localhost:3307" user="test" password="123456" /> </dataHost> </mycat:schema>
比如在这个配置文件里面,就配置了两个数据库,weixin和yixin,这两个库各自包含一张user表。
注意:MyCAT对外端显示出来的数据库,和数据库里面的表,全部在schema里面配置,没有写在这个里面的表或者库,即使后端的MySQL里面存在,也无法通过MyCAT去访问,不过MyCAT不会去定义具体表的结构。
然后是datanode,这个属性指定了schema的表,具体存放在哪个数据库,比如这个配置里面,指定了dn1的数据节点位于localhost0,这个数据库实例的名为weixin的数据库,dn2同理。
datahost列出了实际的后端MySQL集群的具体信息,writehost是负责写入数据的MySQL实例,writehost是负责读的MySQL实例,如果两个实例的具体信息写成一样,那就意味着后端使用单实例,如果配置成不同的实例,那么就在两个实例之间配置主从同步,然后通过MyCAT实现读写分离
对数据库进行垂直切分,主要由schema.xml来完成,这个以后再详细介绍。
rule.xml如示例
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://org.opencloudb/"> <tableRule name="rule"> <rule> <columns>user_id</columns> <algorithm>func1</algorithm> </rule> </tableRule> <function name="func1" class="org.opencloudb.route.function.PartitionByLong"> <property name="partitionCount">2</property> <property name="partitionLength">512</property> </function> </mycat:rule>
rule.xml里面的配置主要用于对表的水平切分,MyCAt本身提供了很多种水平切分的策略,这个示例显示的是取模分片,总共分成四片,user_id对1024取模,然后分成两片,每一片512个。
其他的切分策略以后再详细介绍
server.xml如示例
<!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://org.opencloudb/"> <system> <property name="sequnceHandlerType">0</property> </system> <user name="test"> <property name="password">test</property> <property name="schemas">weixin,yixin</property> </user> </mycat:server>
server.xml里面配置MyCAT的逻辑库参数,如示例,配置的就是逻辑库weixin和yixin的登录用户名和密码
这个XML里面其实还有一些有关于MyCAT性能调整的参数,不过略去了,东西太多,以后再详细介绍
----------------------------------------------------------------------华丽的分割线-------------------------------------------------------------
简单的MyCAT搭建大致上就包括这些内容,现在讲讲使用一段时间以后,对MyCAT的一些总结;
1.MyCAT的性能表现还是不错的,这几天一直对MyCAT的各方面进行测试,发现MyCAT作为一个代理,虽然是在JAVA虚拟机上面运行,但是面对接近9K的QPS的峰值的时候,本身并没有出现无响应或者丢失连接的问题;
2.MyCAT对前端显示的所有的库,表,全部由schema来配置,但是本身不定义表结构,这使得后端的表结构如果出现不一致,MyCAT前端是察觉不到的,不太方便吧;
3.第二点的不方便,也反映了一点,没有配置到schema的表,完全无法通过MyCAT去操作,这也算是安全性良好的一个表现吧;
4.之前说SQL Executor没感觉到,也是因为在一些测试中,发现MyCAT更像一个提供转发和结果合并功能的代理,只是对SQL和结果进行了process,不过这个需要去看源代码才知晓细节了。
这次只打算写这么多,关于MyCAT的一些细节介绍,留给下一章~
MySQL分布式集群之MyCAT(一)简介(修正)-wangwenan6-ITPUB博客
http://blog.itpub.net/29510932/viewspace-1664499/