图学习初印象
Part1 什么是图
- 图的两个基本元素:点、边
- 图是一种统一描述复杂事物的语言
- 常见的图:社交网络、推荐系统、化学分子结构...
Part2 什么是图学习
- 图学习: Graph Learning。深度学习中的一个子领域,强调处理的数据对象为图。
- 与一般深度学习的区别:能够方便地处理不规则数据(树、图),同时也可以处理规则数据(如图像)。
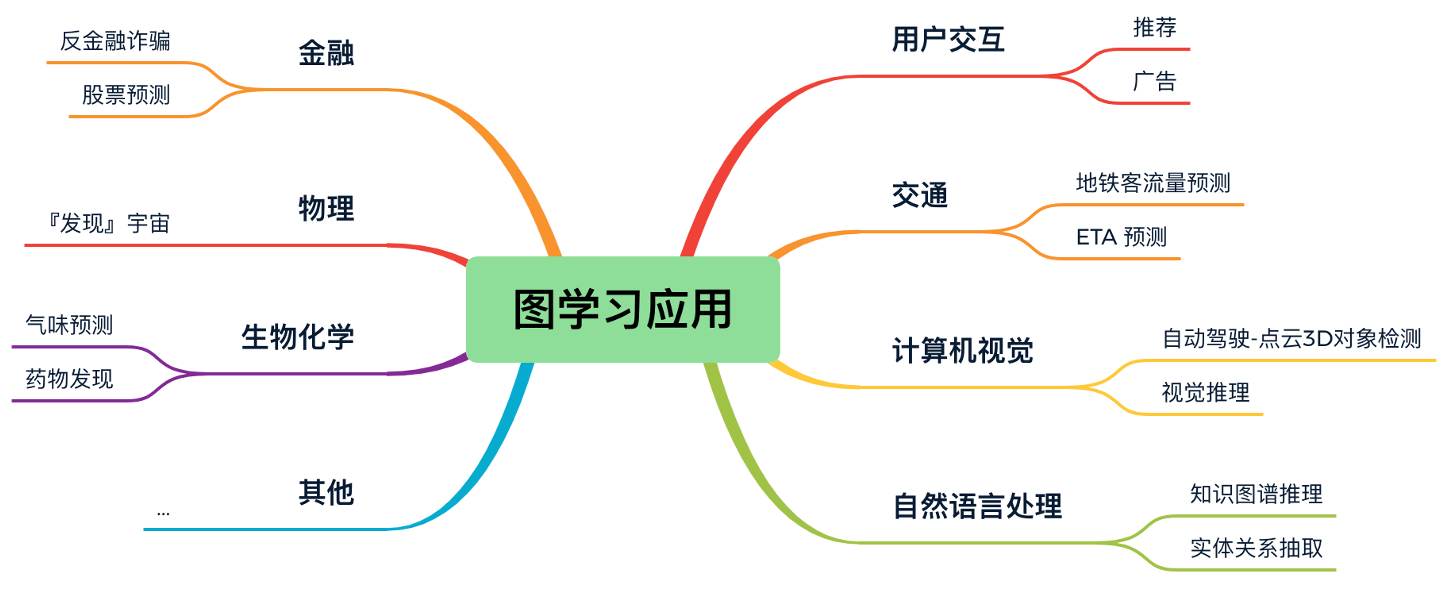
Part3 图学习的应用
我们可以把图学习的应用分为节点级别任务、边级别任务、图级别任务。 课程中介绍了以下几种任务。
- 节点级别任务:金融诈骗检测(典型的节点分类)、自动驾驶中的3D点云目标检测
- 边级别任务:推荐系统(典型的边预测)
- 图级别任务:气味识别(典型的图分类)、发现“宇宙”
做一个小结:
Part4 图学习是怎么做的
- 图游走类算法:通过在图上的游走,获得多个节点序列,再利用 Skip Gram 模型训练得到节点表示(下节课内容)
- 图神经网络算法:端到端模型,利用消息传递机制实现。
- 知识图谱嵌入算法:专门用于知识图谱的相关算法。
Part5 PGL 图学习库简介
-
Github 链接:https://github.com/PaddlePaddle/PGL
-
API文档: https://pgl.readthedocs.io/en/latest/
Part6 熟悉 PGL 使用
2. 使用 PGL 来创建一张图
假设我们有下面的这一张图,其中包含了10个节点以及14条边。
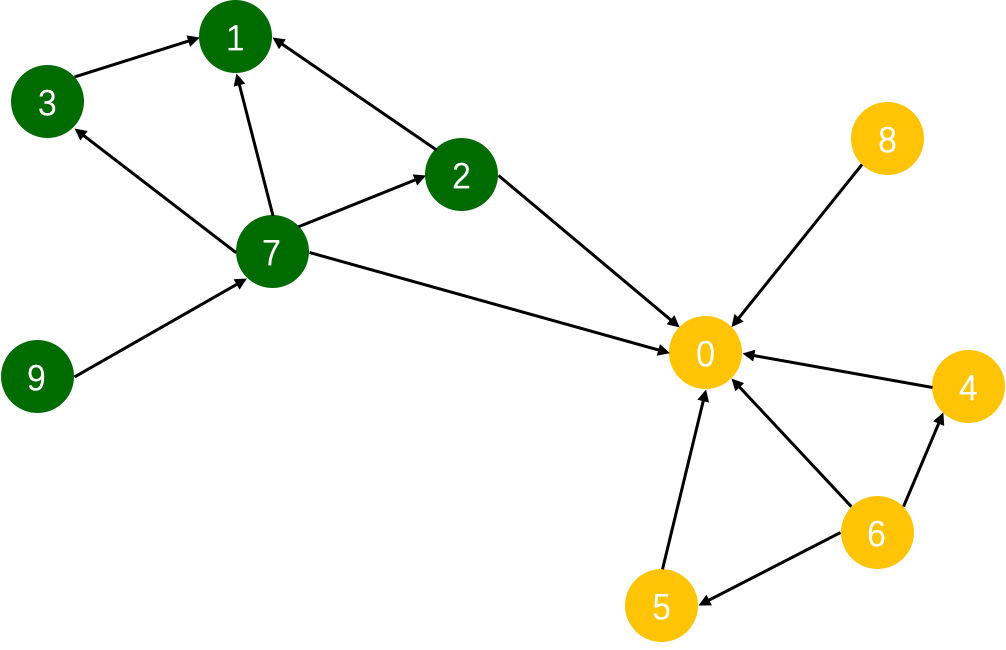
我们的目的是,训练一个图模型,使得该图模型可以区分图上的黄色节点和绿色节点。我们可以使用以下代码来构图。
import pgl
from pgl import graph # 导入 PGL 中的图模块
import paddle.fluid as fluid # 导入飞桨框架
import numpy as np
def build_graph():
# 定义图中的节点数目,我们使用数字来表示图中的每个节点
num_nodes = 10
# 定义图中的边集
edge_list = [(2, 0), (2, 1), (3, 1),(4, 0), (5, 0),
(6, 0), (6, 4), (6, 5), (7, 0), (7, 1),
(7, 2), (7, 3), (8, 0), (9, 7)]
# 随机初始化节点特征,特征维度为 d
d = 16
feature = np.random.randn(num_nodes, d).astype("float32")
# 随机地为每条边赋值一个权重
edge_feature = np.random.randn(len(edge_list), 1).astype("float32")
# 创建图对象,最多四个输入
g = graph.Graph(num_nodes = num_nodes,
edges = edge_list,
node_feat = {'feature':feature},
edge_feat ={'edge_feature': edge_feature})
return g
g = build_graph()
# 定义一个同时传递节点特征和边权重的简单模型层。
def model_layer(gw, nfeat, efeat, hidden_size, name, activation):
'''
gw: GraphWrapper 图数据容器,用于在定义模型的时候使用,后续训练时再feed入真实数据
nfeat: 节点特征
efeat: 边权重
hidden_size: 模型隐藏层维度
activation: 使用的激活函数
'''
# 定义 send 函数
def send_func(src_feat, dst_feat, edge_feat):
# 将源节点的节点特征和边权重共同作为消息发送
return src_feat['h'] * edge_feat['e']
# 定义 recv 函数
def recv_func(feat):
# 目标节点接收源节点消息,采用 sum 的聚合方式
return fluid.layers.sequence_pool(feat, pool_type='sum')
# 触发消息传递机制
msg = gw.send(send_func, nfeat_list=[('h', nfeat)], efeat_list=[('e', efeat)])
output = gw.recv(msg, recv_func)
output = fluid.layers.fc(output,
size=hidden_size,
bias_attr=False,
act=activation,
name=name)
return output
4. 模型定义
这里我们简单的把上述定义好的模型层堆叠两层,作为我们的最终模型。
class Model(object):
def __init__(self, graph):
"""
graph: 我们前面创建好的图
"""
# 创建 GraphWrapper 图数据容器,用于在定义模型的时候使用,后续训练时再feed入真实数据
self.gw = pgl.graph_wrapper.GraphWrapper(name='graph',
node_feat=graph.node_feat_info(),
edge_feat=graph.edge_feat_info())
# 作用同 GraphWrapper,此处用作节点标签的容器
self.node_label = fluid.layers.data("node_label", shape=[None, 1],
dtype="float32", append_batch_size=False)
def build_model(self):
# 定义两层model_layer
output = model_layer(self.gw,
self.gw.node_feat['feature'],
self.gw.edge_feat['edge_feature'],
hidden_size=8,
name='layer_1',
activation='relu')
output = model_layer(self.gw,
output,
self.gw.edge_feat['edge_feature'],
hidden_size=1,
name='layer_2',
activation=None)
# 对于二分类任务,可以使用以下 API 计算损失
loss = fluid.layers.sigmoid_cross_entropy_with_logits(x=output,
label=self.node_label)
# 计算平均损失
loss = fluid.layers.mean(loss)
# 计算准确率
prob = fluid.layers.sigmoid(output)
pred = prob > 0.5
pred = fluid.layers.cast(prob > 0.5, dtype="float32")
correct = fluid.layers.equal(pred, self.node_label)
correct = fluid.layers.cast(correct, dtype="float32")
acc = fluid.layers.reduce_mean(correct)
return loss, acc
# 是否在 GPU 或 CPU 环境运行
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 定义程序,也就是我们的 Program
startup_program = fluid.Program() # 用于初始化模型参数
train_program = fluid.Program() # 训练时使用的主程序,包含前向计算和反向梯度计算
test_program = fluid.Program() # 测试时使用的程序,只包含前向计算
with fluid.program_guard(train_program, startup_program):
model = Model(g)
# 创建模型和计算 Loss
loss, acc = model.build_model()
# 选择Adam优化器,学习率设置为0.01
adam = fluid.optimizer.Adam(learning_rate=0.01)
adam.minimize(loss) # 计算梯度和执行梯度反向传播过程
# 复制构造 test_program,与 train_program的区别在于不需要梯度计算和反向过程。
test_program = train_program.clone(for_test=True)
# 定义一个在 place(CPU)上的Executor来执行program
exe = fluid.Executor(place)
# 参数初始化
exe.run(startup_program)
# 获取真实图数据
feed_dict = model.gw.to_feed(g)
# 获取真实标签数据
# 由于我们是做节点分类任务,因此可以简单的用0、1表示节点类别。其中,黄色点标签为0,绿色点标签为1。
y = [0,1,1,1,0,0,0,1,0,1]
label = np.array(y, dtype="float32")
label = np.expand_dims(label, -1)
feed_dict['node_label'] = label