Elasticsearch 入门
简介
全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。它可以快速地存储、搜索和分析海量数据。它的底层是开源库 Lucene,但是 Lucene 不能直接使用,必须自己写代码去调用它的接口。而 Elastic 是 Lucene 的封装,提供了 Rest API,可以开箱即用。
基本概念
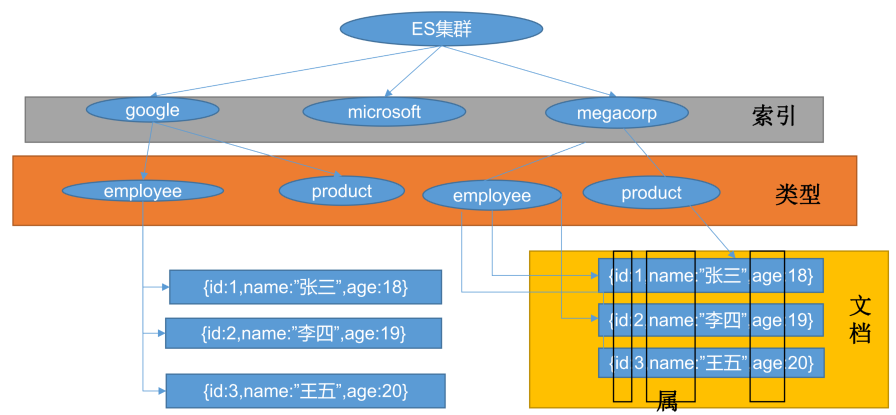
Index(索引)
动词意思,添加数据,相当于 MySQL 中的 insert;
名词意思,保存数据的地方,相当于 MySQL 中的 Database。
Type(类型)
在 Index(索引)中,可以定义一个或多个 Type(类型)。相当于 MySQL 中的 Table,它将每一种类型的数据放在一起。
Document(文档)
保存在某个 Index(索引)下,某种 Type(类型)的一个数据,就叫做 Document(文档),文档是 JSON 格式的,它相当于 MySQL 中的摸一个 Table 里面的内容。
倒排索引
为什么 ES 搜索快?这是因为使用了倒排索引。
通过分词,将整句拆分为单词。
假设保存的记录为:
- 红海行动
- 探索红海行动
- 红海特别行动
- 红海记录片
- 特工红海特别探索
那么会得到倒排索引表为:
| 词 | 记录 |
|---|---|
| 红海 | 1,2,3,4,5 |
| 行动 | 1,2,3 |
| 探索 | 2,5 |
| 特别 | 3,5 |
| 纪录片 | 4, |
| 特工 | 5 |
例如检索:红海特工行动,查出后计算相关性得分,3 号记录命中了 2 次,且 3 号本身才有 3 个单词,2/3,所以 3 号最匹配。
例如检索:红海行动,1 号最匹配。
去掉 Type 概念
关系型数据库中两个数据表示是独立的,即使它们里面有相同名称的列也不影响使用,但 ES 中不是这样的。ES 是基于Lucene 开发的搜索引擎, ES 中不同 type 下名称相同的 filed 最终在 Lucene 中的处理方式是一样的。
- 两个不同 type 下的两个 user_name,在 ES 同一个索引下其实被认为是同一个 filed,必须在两个不同的 type 中定义相同的 filed 映射。否则,不同 type 中的相同字段名称就会在处理中出现冲突的情况,导致 Lucene 处理效率下降。
- 去掉 type 就是为了提高 ES 处理数据的效率。
- Elasticsearch 7.x 中,URL 中的 type 参数为可选。比如,索引一个文档不再要求提供文档类型。
- Elasticsearch 8.x 中,不再支持 URL 中的 type 参数。
- 解决方法:将索引从多类型迁移到单类型,每种类型文档一个独立索引。
Docker 安装 ES
-
下载安装 elasticsearch(存储和检索)和 kibana(可视化检索)
docker pull elasticsearch:7.8.0 docker pull kibana:7.8.0 -
配置
# 将 docker 里的目录挂载到 linux 的 /docker 目录中 # 修改 /docker 就可以改掉 docker 里的 mkdir -p /docker/elasticsearch7.8.0/config mkdir -p /docker/elasticsearch7.8.0/data mkdir -p /docker/elasticsearch7.8.0/plugins # 让 es 可以被远程任何机器访问 echo "http.host: 0.0.0.0" >> /docker/elasticsearch7.8.0/config/elasticsearch.yml # 修改文件权限 chmod -R 777 /docker/elasticsearch7.8.0/ -
启动 elasticsearch
# 查看可用内存 [root@10 /]# free -m total used free shared buff/cache available Mem: 990 616 72 1 302 232 Swap: 2047 393 1654 # 9200 是用户交互端口,9300 是集群心跳端口 # 第一个 -e,指定是单阶段运行 # 第二个 -e,指定占用的内存大小,生产时可以设置 32G # 考虑到虚拟机情况,设置内存不超过 512m docker run --name elasticsearch7.8.0 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" -v /docker/elasticsearch7.8.0/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /docker/elasticsearch7.8.0/data:/usr/share/elasticsearch/data -v /docker/elasticsearch7.8.0/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.8.0 # 设置开机启动 docker update elasticsearch7.8.0 --restart=always -
测试 elasticsearch
访问 http://192.168.56.56:9200/ 返回 elasticsearch 版本信息 { "name": "0f6d6c60bc96", "cluster_name": "elasticsearch", "cluster_uuid": "sDTdW7KnQayVrFC5ioijiQ", "version": { "number": "7.8.0", "build_flavor": "default", "build_type": "docker", "build_hash": "757314695644ea9a1dc2fecd26d1a43856725e65", "build_date": "2020-06-14T19:35:50.234439Z", "build_snapshot": false, "lucene_version": "8.5.1", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search" } 访问 http://192.168.56.56:9200/_cat/nodes 返回 elasticsearch 节点信息 127.0.0.1 60 93 6 0.04 0.19 0.18 dilmrt * 0f6d6c60bc96 -
启动 kibana
# kibana 指定了 ES 交互端口 9200 # 5601 为 kibana 主页端口 docker run --name kibana7.8.0 -e ELASTICSEARCH_HOSTS=http://192.168.56.56:9200 -p 5601:5601 -d kibana:7.8.0 # 设置开机启动 docker update kibana7.8.0 --restart=always -
测试 kibana
访问 http://192.168.56.56:5601 返回可视化界面
Docker 安装 Nginx
-
启动一个 Nginx 实例,复制出配置文件
# 不存在时会自动下载 docker run -p 80:80 --name nginx1.10 -d nginx:1.10 # 创建存放 nginx 的文件夹 mkdir docker/nginx1.10 # 把容器内的配置文件拷贝到当前目录 cd docker/ docker container cp nginx1.10:/etc/nginx . # 暂停删除容器,修改文件名称为 conf,并移动到 nginx1.10 文件夹 docker stop nginx1.10 docker rm nginx1.10 mv nginx conf mv conf nginx1.10/ -
启动 Nginx
docker run -p 80:80 --name nginx1.10 -v /docker/nginx1.10/html:/usr/share/nginx/html -v /docker/nginx1.10/logs:/var/log/nginx -v /docker/nginx1.10/conf:/etc/nginx -d nginx:1.10 # 设置开机启动 docker update nginx1.10 --restart=always -
测试 Nginx
访问 http://192.168.56.56 返回界面
初步检索
检索信息
-
GET /_cat/nodes查看所有节点# http://192.168.56.56:9200/_cat/nodes 127.0.0.1 64 93 2 0.00 0.03 0.10 dilmrt * 0f6d6c60bc96 # 0f6d6c60bc96 代表节点,* 代表主节点 -
GET /_cat/health查看 es 健康状况# http://192.168.56.56:9200/_cat/health 1617779285 07:08:05 elasticsearch green 1 1 6 6 0 0 0 0 - 100.0% # green 表示健康值正常 -
GET/_cat/master查看主节点# http://192.168.56.56:9200/_cat/master -fBJbk3HQxq4oxHVP5o8XQ 127.0.0.1 127.0.0.1 0f6d6c60bc96 # -fBJbk3HQxq4oxHVP5o8XQ 代表主节点唯一编号 # 127.0.0.1 代表虚拟机地址 -
GET/_cat/indices查看所有索引,相当于 MySQL 中的show databases;# http://192.168.56.56:9200/_cat/indices green open .kibana-event-log-7.8.0-000001 NSvWWbd7SaqNmoJ6QmjIRg 1 0 1 0 5.3kb 5.3kb green open .apm-custom-link mn9tqI-0QnOkI5JAp1rCHw 1 0 0 0 208b 208b green open .kibana_task_manager_1 k5bSwn03TA-Hpisuzf677A 1 0 5 2 74.2kb 74.2kb green open .apm-agent-configuration ZXRvqEdDSL2555OE8MyNSA 1 0 0 0 208b 208b green open .kibana_1 _yCppL1mQ1a0-v88yOXNTQ 1 0 13 1 72.4kb 72.4kb
新增文档
保存一个数据,保存在哪个索引的哪个类型下,相当于 MySQL 中的哪个数据库的哪张表下。指定用哪一个唯一标识。
PUT customer/external/1 在 customer 索引下的 external 类型下保存 1 号数据:
# postman 新增文档-PUT
# PUT http://192.168.56.56:9200/customer/external/1
# 创建数据成功后,显示 201 created 表示插入记录成功。
# 发送多次是更新操作
{
"_index": "customer", # 表明该数据在哪个数据库下
"_type": "external", # 表明该数据在哪个类型下
"_id": "1", # 表明被保存数据的 id
"_version": 1, # 被保存数据的版本
"result": "created", # 创建了一条数据,如果重新 put 一条数据,则该状态会变为 updated,并且版本号也会发生变化
"_shards": { # 分片
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0, # 序列号
"_primary_term": 1
}
POST customer/external
# postman 新增文档-POST
# POST http://192.168.56.56:9200/customer/external
# 发送多次是更新操作
{
"_index": "customer",
"_type": "external",
"_id": "dBNCq3gBsa8QUaibccNi", # 不指定 ID,会自动的生成 id,并且类型是新增的
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
POST customer/external/3
# postman 新增文档-POST
# POST http://192.168.56.56:9200/customer/external/3
# 发送多次是更新操作
{
"_index": "customer",
"_type": "external",
"_id": "3", # 指定 ID,会使用该 id,并且类型是新增的
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1
}
总结:
- POST 新增。如果不指定 id,会自动生成 id。
- 可以不指定 id,不指定 id 时永远为创建
- 指定不存在的 id 时也为创建
- 指定存在的 id 时为更新,并且 version 会根据内容变没变而指定版本号是否递增
- PUT 新增或修改。PUT 必须指定 id。
- 一般用来做修改操作,不指定 id 会报错
- version 总是递增
_version指版本号,起始值都为 1,每次对当前文档成功操作后都加 1_seq_no指序列号,在第一次为索引插入数据时为 0,每对索引内数据操作成功一次加 1, 并且文档会记录是第几次操作使它成为现在的情况的
查询文档
GET /customer/external/1
# GET http://192.168.56.56:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 2,
"_seq_no": 1, # 并发控制字段,每次更新都会 +1,用来做乐观锁
"_primary_term": 1, # 同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": {
"name": "parzulpan"
}
}
乐观锁用法:通过 if_seq_no=1&if_primary_term=1 参数,当序列号匹配的时候,才进行修改,否则不修改。
-
将 name 更新为 parzulpan1
# PUT http://192.168.56.56:9200/customer/external/1?if_seq_no=1&if_primary_term=1 { "_index": "customer", "_type": "external", "_id": "1", "_version": 3, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 8, "_primary_term": 1 } # 再次查询 # GET http://192.168.56.56:9200/customer/external/1 { "_index": "customer", "_type": "external", "_id": "1", "_version": 4, "_seq_no": 9, "_primary_term": 1, "found": true, "_source": { "name": "parzulpan1" } }
更新文档
方式一:POST customer/external/1/_update
# POST http://192.168.56.56:9200/customer/external/1/_update
{
"doc": { # 注意要带上 doc
"name": "parzulpanUpdate"
}
}
# 返回
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 5,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 10,
"_primary_term": 1
}
# 如果再次执行更新,则不执行任何操作,版本号和序列号也不发生变化
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 5,
"result": "noop", # 无操作
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"_seq_no": 10,
"_primary_term": 1
}
方式二:POST customer/external/1
# POST http://192.168.56.56:9200/customer/external/1
{
"name": "parzulpanUpdate"
}
# 返回
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 6,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 1
}
# 如果再次执行更新,数据会更新成功,并且版本号和序列号会发生变化
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 7,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 12,
"_primary_term": 1
}
方式三:PUT customer/external/1
# PUT http://192.168.56.56:9200/customer/external/1/
{
"name": "parzulpanUpdate"
}
# 返回
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 8,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 13,
"_primary_term": 1
}
# 如果再次执行更新,数据会更新成功,并且版本号和序列号会发生变化
总结:
- POST ,带 _update 时,如果数据相同,不会重新保存并且版本号和序列号不会发生变化
- POST ,不带 _update 时,总是会重新保存并且版本号和序列号会发生变化
- PUT,总是会重新保存并且版本号和序列号会发生变化
- 使用场景:对于大并发更新,推荐不带 _update,而对于大并发查询且偶尔更新,推荐带 _update
删除文档或索引
注意,ES 并没有提供删除类型的操作,只提供了删除文档或者索引的操作。
删除文档
# 删除 id=1 的数据,删除后继续查询
# DELETE http://192.168.56.56:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 10,
"result": "deleted", # 已被删除
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 15,
"_primary_term": 1
}
# 再次执行 DELETE http://192.168.56.56:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 11,
"result": "not_found", # 找不到
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 16,
"_primary_term": 1
}
# GET http://192.168.56.56:9200/customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"found": false # 找不到
}
删除索引
# 删除整个 customer 索引
# 删除前,GET http://192.168.56.56:9200/_cat/indices
green open .kibana-event-log-7.8.0-000001 NSvWWbd7SaqNmoJ6QmjIRg 1 0 1 0 5.3kb 5.3kb
green open .apm-custom-link mn9tqI-0QnOkI5JAp1rCHw 1 0 0 0 208b 208b
green open .kibana_task_manager_1 k5bSwn03TA-Hpisuzf677A 1 0 5 2 74.2kb 74.2kb
green open .apm-agent-configuration ZXRvqEdDSL2555OE8MyNSA 1 0 0 0 208b 208b
green open .kibana_1 _yCppL1mQ1a0-v88yOXNTQ 1 0 15 0 34.9kb 34.9kb
yellow open customer t6RCi8QZQoiEx-wxJQvlmw 1 1 5 0 4.6kb 4.6kb
# DELETE http://192.168.56.56:9200/customer
{
"acknowledged": true
}
# 删除后,GET http://192.168.56.56:9200/_cat/indices
green open .kibana-event-log-7.8.0-000001 NSvWWbd7SaqNmoJ6QmjIRg 1 0 1 0 5.3kb 5.3kb
green open .apm-custom-link mn9tqI-0QnOkI5JAp1rCHw 1 0 0 0 208b 208b
green open .kibana_task_manager_1 k5bSwn03TA-Hpisuzf677A 1 0 5 2 74.2kb 74.2kb
green open .apm-agent-configuration ZXRvqEdDSL2555OE8MyNSA 1 0 0 0 208b 208b
green open .kibana_1 _yCppL1mQ1a0-v88yOXNTQ 1 0 15 0 34.9kb 34.9kb
批量操作-bulk
这里的批量操作,指的是当发生某一条执行发生失败时,其他的数据仍然能够接着执行,也就是说彼此之间是独立的。
bulk api 以此按顺序执行所有的 action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。当 bulk api 返回时,它将提供每个动作的状态(与发送的顺序相同),所以可以检查一个指定的动作是否失败了。
注意,由于 bulk 不支持 json 或者 text 格式,所以不能在 postman 中测试,可以使用 kibana 的 DevTools。
实例 1:执行多条数据
# 在 kibana 的 DevTools 的控制台执行以下命令
POST /customer/external/_bulk
{"index":{"_id":"1"}}
{"name":"John Doe"}
{"index":{"_id":"2"}}
{"name":"John Doe"}
# 返回
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
"took" : 368, # 命令花费时间
"errors" : false, # 没有发送任何错误
"items" : [ # 每个数据的结果
{
"index" : { # 第一条数据
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201 # 新建完成
}
},
{
"index" : { # 第二条数据
"_index" : "customer",
"_type" : "external",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
}
]
}
实例 2:对于整个索引执行批量操作
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}
# 返回
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
"took" : 450,
"errors" : false,
"items" : [
{
"delete" : { # 删除
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 404
}
},
{
"create" : { # 创建
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : { # 保存
"_index" : "website",
"_type" : "blog",
"_id" : "nxPjrHgBsa8QUaibx-rD",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"update" : { # 更新
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 200
}
}
]
}
样本测试数据
一份顾客银行账户信息的虚构的 JSON 文档样本,文件地址
格式为:
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
}
POST bank/account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
...
GET http://192.168.56.56:9200/_cat/indices
green open .kibana-event-log-7.8.0-000001 NSvWWbd7SaqNmoJ6QmjIRg 1 0 1 0 5.3kb 5.3kb
yellow open website 3rGabFSISrq8ZwdXxP331g 1 1 2 2 8.8kb 8.8kb
yellow open bank ZpN0_upESxqV84IVAgyvJw 1 1 1000 0 397kb 397kb
green open .apm-custom-link mn9tqI-0QnOkI5JAp1rCHw 1 0 0 0 208b 208b
green open .kibana_task_manager_1 k5bSwn03TA-Hpisuzf677A 1 0 5 2 74.2kb 74.2kb
green open .apm-agent-configuration ZXRvqEdDSL2555OE8MyNSA 1 0 0 0 208b 208b
green open .kibana_1 _yCppL1mQ1a0-v88yOXNTQ 1 0 28 2 63.9kb 63.9kb
yellow open customer kYEsiy1iQWa2S_7JSsG9kQ 1 1 2 0 3.6kb 3.6kb
# 可以看到 bank 索引导入了 1000 条数据
进阶检索
SearchAPI
ES 支持两种基本方式检索:
-
通过 REST request uri 发送检索参数,即 uri + 检索参数
GET http://192.168.56.56:9200/bank/_search?q=*&sort=account_number:asc # q=* 表示查询所有 # sort 表示排序字段 # asc 表示升序 # 返回 { "took": 2, # 花费多少 ms 检索 "timed_out": false, # 是否超时 "_shards": { # 多少分片被搜索了,以及多少成功/失败的搜索分片 "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1000, # 多少匹配文档被找到 "relation": "eq" }, "max_score": null, # 文档相关性最高得分 "hits": [ { "_index": "bank", "_type": "account", "_id": "0", "_score": null, # 相关得分 "_source": { "account_number": 0, "balance": 16623, "firstname": "Bradshaw", "lastname": "Mckenzie", "age": 29, "gender": "F", "address": "244 Columbus Place", "employer": "Euron", "email": "bradshawmckenzie@euron.com", "city": "Hobucken", "state": "CO" }, "sort": [ # 结果的排序 key(列),没有的话按照 score 排序 0 ] }, // ... { "_index": "bank", "_type": "account", "_id": "9", "_score": null, "_source": { "account_number": 9, "balance": 24776, "firstname": "Opal", "lastname": "Meadows", "age": 39, "gender": "M", "address": "963 Neptune Avenue", "employer": "Cedward", "email": "opalmeadows@cedward.com", "city": "Olney", "state": "OH" }, "sort": [ 9 ] } ] } } -
通过 REST request body,即 uri + 请求体
GET http://192.168.56.56:9200/bank/_search { "query": { "match_all": {} }, "sort": [ { "account_number": "asc" }, { "balance":"desc"} ] } # 返回 { "took": 3, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1000, "relation": "eq" }, "max_score": null, "hits": [ { "_index": "bank", "_type": "account", "_id": "0", "_score": null, "_source": { "account_number": 0, "balance": 16623, "firstname": "Bradshaw", "lastname": "Mckenzie", "age": 29, "gender": "F", "address": "244 Columbus Place", "employer": "Euron", "email": "bradshawmckenzie@euron.com", "city": "Hobucken", "state": "CO" }, "sort": [ 0, 16623 ] }, // ... { "_index": "bank", "_type": "account", "_id": "9", "_score": null, "_source": { "account_number": 9, "balance": 24776, "firstname": "Opal", "lastname": "Meadows", "age": 39, "gender": "M", "address": "963 Neptune Avenue", "employer": "Cedward", "email": "opalmeadows@cedward.com", "city": "Olney", "state": "OH" }, "sort": [ 9, 24776 ] } ] } }
Query DSL
ES 提供了一个可以执行查询的 json 风格 的 DSL(Domain specific language,领域特定语言 ),被称为 Query DSL。
基本语法格式
一个查询语句的典型结构:
# 如果针对于某个字段,那么它的结构为:
{
QUERY_NAME:{ # 使用的功能
FIELD_NAME:{ # 功能参数
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}
查询示例:
query定义如何查询,match_all代表查询所有的索引from代表从第几条文档开始查询,size代表查询文档个数,通常组合起来完成分页功能sort代表排序,多字段排序时,会在前序字段相等时后续字段内部排序,否则以前序为准
GET http://192.168.56.56:9200/bank/_search
{
"query": { # 查询的字段
"match_all": {}
},
"from": 0, # 从第几条文档开始查
"size": 5,
"_source":["balance", "firstname"], # 要返回的字段
"sort": [
{
"account_number": { # 返回结果按哪个列排序
"order": "desc" # 降序
}
}
]
}
# 返回
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "999",
"_score": null,
"_source": {
"firstname": "Dorothy",
"balance": 6087
},
"sort": [
999
]
},
{
"_index": "bank",
"_type": "account",
"_id": "998",
"_score": null,
"_source": {
"firstname": "Letha",
"balance": 16869
},
"sort": [
998
]
},
{
"_index": "bank",
"_type": "account",
"_id": "997",
"_score": null,
"_source": {
"firstname": "Combs",
"balance": 25311
},
"sort": [
997
]
},
{
"_index": "bank",
"_type": "account",
"_id": "996",
"_score": null,
"_source": {
"firstname": "Andrews",
"balance": 17541
},
"sort": [
996
]
},
{
"_index": "bank",
"_type": "account",
"_id": "995",
"_score": null,
"_source": {
"firstname": "Phelps",
"balance": 21153
},
"sort": [
995
]
}
]
}
}
query/match 匹配查询
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索。
-
非字符串(基本类型),精确匹配
GET http://192.168.56.56:9200/bank/_search { "query": { "match": { "account_number": "20" } } } # 返回 { "took": 10, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, # 得到一条记录 "relation": "eq" }, "max_score": 1.0, # 最大得分 "hits": [ { "_index": "bank", "_type": "account", "_id": "20", "_score": 1.0, "_source": { # 文档信息 "account_number": 20, "balance": 16418, "firstname": "Elinor", "lastname": "Ratliff", "age": 36, "gender": "M", "address": "282 Kings Place", "employer": "Scentric", "email": "elinorratliff@scentric.com", "city": "Ribera", "state": "WA" } } ] } } -
字符串,全文检索,最终会按照评分进行排序,会对检索条件进行分词匹配。这是因为维护了一个倒排索引表。
GET http://192.168.56.56:9200/bank/_search { "query": { "match": { "address": "kings" } } } # 返回 { "took": 3, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, # 得到两条记录 "relation": "eq" }, "max_score": 5.990829, # 最大得分 "hits": [ { "_index": "bank", "_type": "account", "_id": "20", "_score": 5.990829, # 得分 "_source": { # 文档信息 "account_number": 20, "balance": 16418, "firstname": "Elinor", "lastname": "Ratliff", "age": 36, "gender": "M", "address": "282 Kings Place", "employer": "Scentric", "email": "elinorratliff@scentric.com", "city": "Ribera", "state": "WA" } }, { "_index": "bank", "_type": "account", "_id": "722", "_score": 5.990829, "_source": { "account_number": 722, "balance": 27256, "firstname": "Roberts", "lastname": "Beasley", "age": 34, "gender": "F", "address": "305 Kings Hwy", "employer": "Quintity", "email": "robertsbeasley@quintity.com", "city": "Hayden", "state": "PA" } } ] } }
query/match_phrase 不拆分匹配查询
将需要匹配的值当成一整个单(不进行拆分)进行检索。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。- 文本字段的匹配,使用
keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"match_phrase": {
"address": "mill road" # 不要匹配只有 mill 或只有 road 的,要匹配 mill road 一整个子串
}
}
}
# 返回
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 8.926605,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 8.926605,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road", # Mill Road
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}
]
}
}
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"match": {
"address.keyword": "mill road" # 精准全部匹配
}
}
}
# 返回
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"match": {
"address.keyword": "990 Mill Road" # 精准全部匹配,而且区分大小写
}
}
}
# 返回
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 6.5032897,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 6.5032897,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}
]
}
}
query/multi_match 多字段匹配查询
state 或者 address 中包含 mill,并且在查询过程中,会对于查询条件进行分词。
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"multi_match": { # 指定多个字段
"query": "mill",
"fields": [ # state 和 address 有 mill 子串,但不要求都有
"state",
"address"
]
}
}
}
# 返回
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
},
{
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 5.4032025,
"_source": {
"account_number": 136,
"balance": 45801,
"firstname": "Winnie",
"lastname": "Holland",
"age": 38,
"gender": "M",
"address": "198 Mill Lane",
"employer": "Neteria",
"email": "winnieholland@neteria.com",
"city": "Urie",
"state": "IL"
}
},
{
"_index": "bank",
"_type": "account",
"_id": "345",
"_score": 5.4032025,
"_source": {
"account_number": 345,
"balance": 9812,
"firstname": "Parker",
"lastname": "Hines",
"age": 38,
"gender": "M",
"address": "715 Mill Avenue",
"employer": "Baluba",
"email": "parkerhines@baluba.com",
"city": "Blackgum",
"state": "KY"
}
},
{
"_index": "bank",
"_type": "account",
"_id": "472",
"_score": 5.4032025,
"_source": {
"account_number": 472,
"balance": 25571,
"firstname": "Lee",
"lastname": "Long",
"age": 32,
"gender": "F",
"address": "288 Mill Street",
"employer": "Comverges",
"email": "leelong@comverges.com",
"city": "Movico",
"state": "MT"
}
}
]
}
}
query/bool/must 复合匹配查询
复合语句必须合并,任何其他查询语句,包括符号语句。这也意味着,复合语句之间可以相互嵌套,可以表达非常复杂的逻辑。
must必须匹配的条件must_not必须不匹配的条件should应该匹配的条件,满足最好,不满足也可以,满足了得分更高- 注意:should 列举的条件,如果到达会增加相关文档的评分,并不会改变查询的结果。如果 query 中有且只有 should 一种匹配规则,那么 should 的条件就会被作为默认匹配条件去改变查询结果。
# 查询 gender=m,并且 address=mill 的数据
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
},
{
"match": {
"gender": "M"
}
}
]
}
}
}
# 查询 gender=m,并且 address=mill,但是 age!=38 的数据
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age": "38"
}
}
]
}
}
}
# 查询 gender=m,并且 address=mill,但是 age!=18,lastName 应该等于 Wallace 的数据
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age": "18"
}
}
],
"should": [
{
"match": {
"lastname": "Wallace"
}
}
]
}
}
}
query/filter 查询结果过滤
并不是所有的查询都需要产生分数,特别是哪些仅用于过滤的文档。为了不计算分数,ES 会自动检查场景并且优化查询的执行。must_not 也是一种 filter,所以也不会贡献得分。显然这样查询速度会更快。总结为:
- must 贡献得分
- should 贡献得分
- must_not 不贡献得分
- filter 不贡献得分
# 查询所有匹配 address=mill 的文档,然后再根据 10000<=balance<=20000 进行过滤查询结果
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"filter": {
"range": {
"balance": {
"gte": "10000",
"lte": "20000"
}
}
}
}
}
}
# 返回
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "forbeswallace@pheast.com",
"city": "Lopezo",
"state": "AK"
}
}
]
}
}
# 单纯的过滤
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"balance": {
"gte": "10000",
"lte": "20000"
}
}
}
}
}
}
# 返回
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 213,
"relation": "eq"
},
"max_score": 0.0,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "20",
"_score": 0.0, # 不得分
"_source": {
"account_number": 20,
"balance": 16418,
"firstname": "Elinor",
"lastname": "Ratliff",
"age": 36,
"gender": "M",
"address": "282 Kings Place",
"employer": "Scentric",
"email": "elinorratliff@scentric.com",
"city": "Ribera",
"state": "WA"
}
},
// ...
{
"_index": "bank",
"_type": "account",
"_id": "272",
"_score": 0.0, # 不得分
"_source": {
"account_number": 272,
"balance": 19253,
"firstname": "Lilly",
"lastname": "Morgan",
"age": 25,
"gender": "F",
"address": "689 Fleet Street",
"employer": "Biolive",
"email": "lillymorgan@biolive.com",
"city": "Sunbury",
"state": "OH"
}
}
]
}
}
query/term 非 text 字段匹配查询
它和 query/match 一样,能匹配某个属性的值,但是 全文检索字段时用 match,其他非 text 字段时用 term。因为 ES 默认存储 text 值时用分词分析。
aggs/aggName 聚合
聚合提供了从数据中分组和提取数据的能力,最简单的聚合方法类似于 SQL 的 group by 和 聚合函数 等。
在 ES 中,执行搜索返回 hits(命中结果),并且同时返回聚合结果。把已响应的所有命中结果分隔开的能力是非常实用的。可以执行查询和多个聚合,并且在一次使用中得到各自的返回结果,使用一次简洁和简化的 API 可以避免网络往返。
聚合基本语法格式:
"aggs":{ # 聚合
"aggs_name":{ # 聚合的名字,方便展示在结果集中
"AGG_TYPE":{} # 聚合的类型(avg,term,terms)
}
}
# terms 看值的可能性分布,会合并锁查字段,给出计数即可
# avg 看值的分布平均
搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情:
GET http://192.168.56.56:9200/bank/_search
{
"query": { # 查询出包含 mill 的
"match": {
"address": "Mill"
}
},
"aggs": { # 基于查询聚合
"ageAgg": { # 第一个聚合,聚合的名字,可以随便起
"terms": { # 看值的可能性分布
"field": "age",
"size": 10
}
},
"ageAvg": { # 第二个聚合
"avg": { # 看 age 值的平均
"field": "age"
}
},
"balanceAvg": { # 第三个聚合
"avg": { # 看 balance 的平均
"field": "balance"
}
}
},
"size": 0 # 不看详情
}
# 返回
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4, # 命中 4 条记录
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"ageAgg": { # ageAgg 聚合结果
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 38, # age=38 有 2 条记录
"doc_count": 2
},
{
"key": 28,
"doc_count": 1
},
{
"key": 32,
"doc_count": 1
}
]
},
"ageAvg": {
"value": 34.0
},
"balanceAvg": {
"value": 25208.0
}
}
}
aggs/aggName/aggs/aggName 子聚合
按照年龄聚合,求这些年龄段的这些人的平均薪资:
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": { # 看值的可能性分布
"field": "age",
"size": 100
},
"aggs": { # 与 terms 并列
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
# 返回
{
"took": 60,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 31,
"doc_count": 61,
"ageAvg": {
"value": 28312.918032786885
}
},
// ...
{
"key": 29,
"doc_count": 35,
"ageAvg": {
"value": 29483.14285714286
}
}
]
}
}
}
查出所有年龄分布,并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄段的总体平均薪资:
GET http://192.168.56.56:9200/bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": { # age 的分布
"field": "age",
"size": 100
},
"aggs": { # 子聚合
"genderAgg": { #
"terms": { # gender 的分布
"field": "gender.keyword" # 使用 .keyword
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"ageBalanceAvg": { #
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
# 返回
{
"took": 82,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"ageAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 31,
"doc_count": 61,
"genderAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "M",
"doc_count": 35,
"balanceAvg": {
"value": 29565.628571428573
}
},
{
"key": "F",
"doc_count": 26,
"balanceAvg": {
"value": 26626.576923076922
}
}
]
},
"ageBalanceAvg": {
"value": 28312.918032786885
}
},
// ...
{
"key": 29,
"doc_count": 35,
"genderAgg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "M",
"doc_count": 23,
"balanceAvg": {
"value": 29943.17391304348
}
},
{
"key": "F",
"doc_count": 12,
"balanceAvg": {
"value": 28601.416666666668
}
}
]
},
"ageBalanceAvg": {
"value": 29483.14285714286
}
}
]
}
}
}
nested 对象聚合
参考:Elasticsearch 中使用 nested 类型的内嵌对象
Mapping 字段映射
映射是定义文档及其包含的字段的存储和索引方式的过程。每个文档都是字段的集合,每个字段都有自己的 数据类型。映射数据时,将创建一个映射定义,其中包含与文档相关的字段列表。
字段类型
核心类型:
- 字符串
text用于全文索引,搜索时会自动使用分词器进行分词再匹配keyword部分此,搜索时精确完整匹配
- 数字类型
- 整型:byte,short,integer,long
- 浮点型:float, half_float, scaled_float,double
- 日期类型
- 布尔类型
- 二进制类型
复杂类型:
- 数组类型
- 对象类型
- 嵌套类型
地理类型:
- 地理坐标
- 地理图标
查看映射
使用 mapping 来定义:
- 哪些字符串属性应该被看做 全文本属性(full text fields);
- 哪些属性包含数字,日期或地理位置;
- 文档中的所有属性是否都嫩被索引(all 配置);
- 日期的格式;
- 自定义映射规则来执行动态添加属性;
# 查看索引
GET /bank/_mapping
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long" # long 类型
},
"address" : {
"type" : "text", # text 类型,会进行全文检索,进行分词匹配
"fields" : {
"keyword" : {
"type" : "keyword", # 精确匹配
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
创建映射
# 创建映射
PUT /my_index
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
},
"name": {
"type": "text"
}
}
}
}
# 输出
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_index"
}
# 查看映射
GET /my_index
# 输出
{
"my_index" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"name" : {
"type" : "text"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1617960990447",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "KgYd5GOPR0uc5kEbUCeBDg",
"version" : {
"created" : "7080099"
},
"provided_name" : "my_index"
}
}
}
}
# 添加新的字段映射
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false # 表示字段不能被检索
}
}
}
更新映射
对于已经存在的字段映射,我们不能更新,因为更改现有字段可能会使已经建立索引的数据无效。要更新必须创建新的索引,进行数据迁移。具体操作为:
# 先创建新的索引,然后进行数据迁移
# 6.0 之后的写法
POST reindex
{
"source":{
"index":"old_index"
},
"dest":{
"index":"new_index"
}
}
# 老版本写法
POST reindex
{
"source":{
"index":"old_index",
"type":"old_type"
},
"dest":{
"index":"new_index"
}
}
案例: 原来 bank 索引的类型为 account,新版本没有类型了,所以我们把它去掉。
GET /bank/_search
# 输出
{
"took" : 19,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "bank",
"_type" : "account", # 有类型
"_id" : "1",
"_score" : 1.0,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "amberduke@pyrami.com",
"city" : "Brogan",
"state" : "IL"
}
},
// ...
]
}
}
# 先建立新的索引
PUT /newbank
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"employer": {
"type": "keyword"
},
"firstname": {
"type": "text"
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "keyword"
}
}
}
}
# 查看新的映射
GET /newbank/_mapping
# 返回
{
"newbank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer" # 改为了 integer
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "keyword"
},
"email" : {
"type" : "keyword"
},
"employer" : {
"type" : "keyword"
},
"firstname" : {
"type" : "text"
},
"gender" : {
"type" : "keyword"
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "keyword"
}
}
}
}
# 进行迁移
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
# 输出
#! Deprecation: [types removal] Specifying types in reindex requests is deprecated.
{
"took" : 918,
"timed_out" : false,
"total" : 1000,
"updated" : 0,
"created" : 1000,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
# 查看 newbank
GET /newbank/_search
{
"took" : 511,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "newbank",
"_type" : "_doc", # 没有了类型
"_id" : "1",
"_score" : 1.0,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "amberduke@pyrami.com",
"city" : "Brogan",
"state" : "IL"
}
},
// ...
]
}
}
分词
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出 tokens 流。
例如:whitespace tokenizer 遇到空白字符时分割文本。它会将文本"Quick brown fox!"分割为[Quick,brown,fox!]。
该 tokenizer(分词器)还负责记录各个 terms(词条) 的顺序或 position 位置(用于 phrase 短语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start(起始)和 end(结束)的 character offsets(字符串偏移量)(用于高亮显示搜索的内容)。
elasticsearch提供了很多内置的分词器(标准分词器),可以用来构建 custom analyzers(自定义分词器)。更多可参考
标准分词器的使用:
POST _analyze
{
"analyzer": "standard",
"text": "The 2 Brown-Foxes bone."
}
# 输出
{
"tokens" : [
{
"token" : "the",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "2",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<NUM>",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 12,
"end_offset" : 17,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "bone",
"start_offset" : 18,
"end_offset" : 22,
"type" : "<ALPHANUM>",
"position" : 4
}
]
}
所有的语言分词,默认使用的都是 “Standard Analyzer”,但是这些分词器针对于中文的分词,并不友好。为此需要安装中文的分词器。推荐使用 elasticsearch-analysis-ik。
安装 ik 分词器
-
查看 ES 版本
http://192.168.56.56:9200/ { "name": "0f6d6c60bc96", "cluster_name": "elasticsearch", "cluster_uuid": "sDTdW7KnQayVrFC5ioijiQ", "version": { "number": "7.8.0", # 7.8.0 "build_flavor": "default", "build_type": "docker", "build_hash": "757314695644ea9a1dc2fecd26d1a43856725e65", "build_date": "2020-06-14T19:35:50.234439Z", "build_snapshot": false, "lucene_version": "8.5.1", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search" } -
由于使用 Docker 安装 ES 时,进行了路径映射,所以直接进入 ES 的 plugins 目录
cd docker/elasticsearch7.8.0/plugins # 安装 waget yum install wget # 安装 unzip yum install unzip # 下载 ik 压缩包 wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip # 解压 ik unzip elasticsearch-analysis-ik-7.8.0.zip -d ik # 更改权限 chmod -R 777 ik # 删除 ik 压缩包 rm -rf elasticsearch-analysis-ik-7.8.0.zip # 重启 ES docker restart elasticsearch7.8.0
测试分词器
# 使用默认分词器
GET _analyze
{
"text":"我是中国人"
}
# 输出
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "中",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "国",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "人",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
# 使用 ik
GET _analyze
{
"analyzer": "ik_smart",
"text":"我是中国人"
}
# 输出
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
GET _analyze
{
"analyzer": "ik_max_word",
"text":"我是中国人"
}
# 输出
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
自定义词库
-
在 Nginx 的映射文件夹的 html 文件夹下创建 es 文件夹,用于保存 es相关数据
mkdir es -
创建 fenci.txt 文件,将分词数据存放在此文件中
cd es/ # 加入 高富帅 刘德华子 等自定义词 vi fenci.txt 访问 http://192.168.56.56/es/fenci.txt -
修改 plugins/ik/config 中的 IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://192.168.56.56/es/fenci.txt</entry> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> # 重启 ES docker restart elasticsearch7.8.0
注意:更新完成后,ES 只会对于新增的数据用更新分词。历史数据是不会重新分词的。如果想要历史数据重新分词,需要执行 POST my_index/_update_by_query?conflicts=proceed
测试:
GET _analyze
{
"analyzer": "ik_smart",
"text":"我是高富帅刘德华子"
}
# 输出
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "高富帅",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "刘德华子",
"start_offset" : 5,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 3
}
]
}
ES REST CLIENT
Java 操作 ES 有两种方式:
- 通过 9300 端口,以 TCP 方式
- 使用 spring-data-elasticsearch:transport-api.jar
- springboot 版本不同,ransport-api.jar 不同,不能适配 ES 版本
- 7.x 已经不建议使用,8 以后就要废弃
- 具体可参考:Java API (deprecated)
- 通过 9200 端口,以 HTTP 方式
- jestClient: 非官方,更新慢
- HttpClient、RestTemplate:模拟 HTTP 请求,ES 很多操作需要自己封装,麻烦
Elasticsearch-Rest-Client:官方 RestClient,封装了 ES 操作,API 层次分明,上手简单,推荐使用- Elasticsearch-Rest-Client 具体可参考:Java REST Client,并且使用 Java High Level REST Client,它与 Java Low Level REST Client 的区别类似于 MyBatis 和 JDBC。
SpringBoot 整合 ES
-
创建 SpringBoot 项目,选择 Web 依赖,但是不要选择 ES 依赖
-
导入依赖
<!-- ES Rest API--> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.8.0</version> </dependency> # 在 spring-boot-dependencies 中所依赖的ES版本位 6.8.5,要改掉 <properties> <java.version>1.8</java.version> <spring-cloud.version>Hoxton.SR8</spring-cloud.version> <elasticsearch.version>7.8.0</elasticsearch.version> </properties> -
编写 Elasticsearch 配置类
package cn.parzulpan.shopping.search.config; import org.apache.http.HttpHost; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @author parzulpan * @version 1.0 * @date 2021-04 * @project shopping * @package cn.parzulpan.shopping.search.config * @desc Elasticsearch 配置类 */ @Configuration public class ShoppingElasticsearchConfig { // 请求测试项,比如 es 添加了安全访问规则,访问 es 需要添加一个安全头,就可以通过 requestOptions 设置 // 官方建议把 requestOptions 创建成单实例 public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); COMMON_OPTIONS = builder.build(); } @Bean public RestHighLevelClient restHighLevelClient() { RestClientBuilder builder = null; // 可以指定多个 ES builder = RestClient.builder(new HttpHost("192.168.56.56", 9200, "http")); return new RestHighLevelClient(builder); } } -
实例测试
package cn.parzulpan.shopping.search; import org.elasticsearch.client.RestHighLevelClient; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest class ShoppingSearchApplicationTests { @Autowired RestHighLevelClient client; @Test void contextLoads() { } @Test void testRestClient() { System.out.println(client); } } -
保存数据
@Data class User { private String userName; private Integer age; private String gender; } /** * https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-create-index.html * 保存方式分为同步和异步 */ @Test void indexData() throws IOException { // 设置索引 IndexRequest users = new IndexRequest("users"); users.id("1"); //设置要保存的内容,指定数据和类型 // 方式一 // users.source("userName", "zhang", "age", 18, "gender", "男"); // 方式二 User user = new User(); user.setUserName("wang"); user.setAge(20); user.setGender("女"); Gson gson = new Gson(); String userJson = gson.toJson(user); users.source(userJson, XContentType.JSON); // 执行创建索引和保存数据 IndexResponse index = client.index(users, ShoppingElasticsearchConfig.COMMON_OPTIONS); System.out.println(index); } -
获取数据
/** * ES 获取数据 * https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-search.html * 搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄 * GET /bank/_search * { * "query": { # 查询出包含 mill 的 * "match": { * "address": "Mill" * } * }, * "aggs": { # 基于查询聚合 * "ageAgg": { # 第一个聚合,聚合的名字,可以随便起 * "terms": { # 看值的可能性分布 * "field": "age", * "size": 10 * } * }, * "ageAvg": { # 第二个聚合 * "avg": { # 看 age 值的平均 * "field": "age" * } * }, * "balanceAvg": { # 第三个聚合 * "avg": { # 看 balance 的平均 * "field": "balance" * } * } * }, * "size": 0 # 不看详情 * } */ @Test void find() throws IOException { // 1. 创建检索请求 SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("bank"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); // 构造检索条件 // searchSourceBuilder.query(); // searchSourceBuilder.from(); // searchSourceBuilder.size(); // searchSourceBuilder.aggregation(); searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill")); // 构建第一个聚合条件:看值的可能性分布 TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10); searchSourceBuilder.aggregation(ageAgg); // 构建第二个聚合条件:看 age 值的平均 AvgAggregationBuilder ageAvg = AggregationBuilders.avg("ageAvg").field("age"); searchSourceBuilder.aggregation(ageAvg); // 构建第三个聚合条件:看 balance 的平均 AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance"); searchSourceBuilder.aggregation(balanceAvg); // 不看详情 // searchSourceBuilder.size(0); System.out.println("searchSourceBuilder " + searchSourceBuilder.toString()); searchRequest.source(searchSourceBuilder); // 2. 执行检索 SearchResponse response = client.search(searchRequest, ShoppingElasticsearchConfig.COMMON_OPTIONS); // 3. 分析响应结果 System.out.println("response " + response.toString()); // 3.1 将响应结果转换为 Bean SearchHits hits = response.getHits(); SearchHit[] hits1 = hits.getHits(); Gson gson = new Gson(); for (SearchHit hit: hits1) { System.out.println("id: " + hit.getId()); System.out.println("index: " + hit.getIndex()); String sourceAsString = hit.getSourceAsString(); System.out.println("sourceAsString: " + sourceAsString); System.out.println("Account: " + gson.fromJson(sourceAsString, Account.class)); } // 3.2 获取检索到的分析信息 Aggregations aggregations = response.getAggregations(); Terms ageAgg1 = aggregations.get("ageAgg"); for (Terms.Bucket bucket : ageAgg1.getBuckets()) { System.out.println("ageAgg: " + bucket.getKeyAsString() + " => " + bucket.getDocCount()); } Avg ageAvg1 = aggregations.get("ageAvg"); System.out.println("ageAvg: " + ageAvg1.getValue()); Avg balanceAvg1 = aggregations.get("balanceAvg"); System.out.println("balanceAvg: " + balanceAvg1.getValue()); }