MapReduce这种并行编程模式思想最早是在1995年提出的。
MapReduce的特点:
与传统的分布式程序设计相比,MapReduce封装了并行处理、容错处理、本地化计算、负载均衡等细节,还提供了一个简单而强大的接口。
MapReduce把对数据集的大规模操作,分发给一个主节点管理下的各分节点共同完成,通过这种方式实现任务的可靠执行与容错机制。
MapReduce的编程模型:
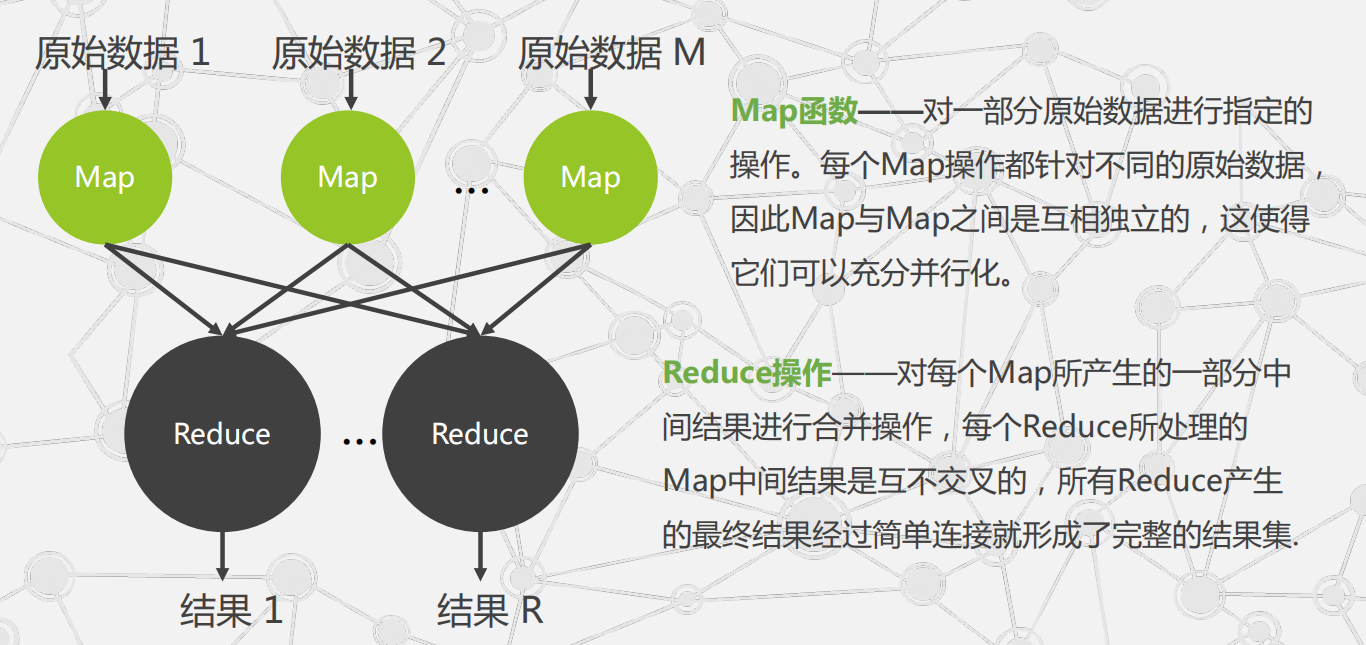

MapReduce的实现机制:
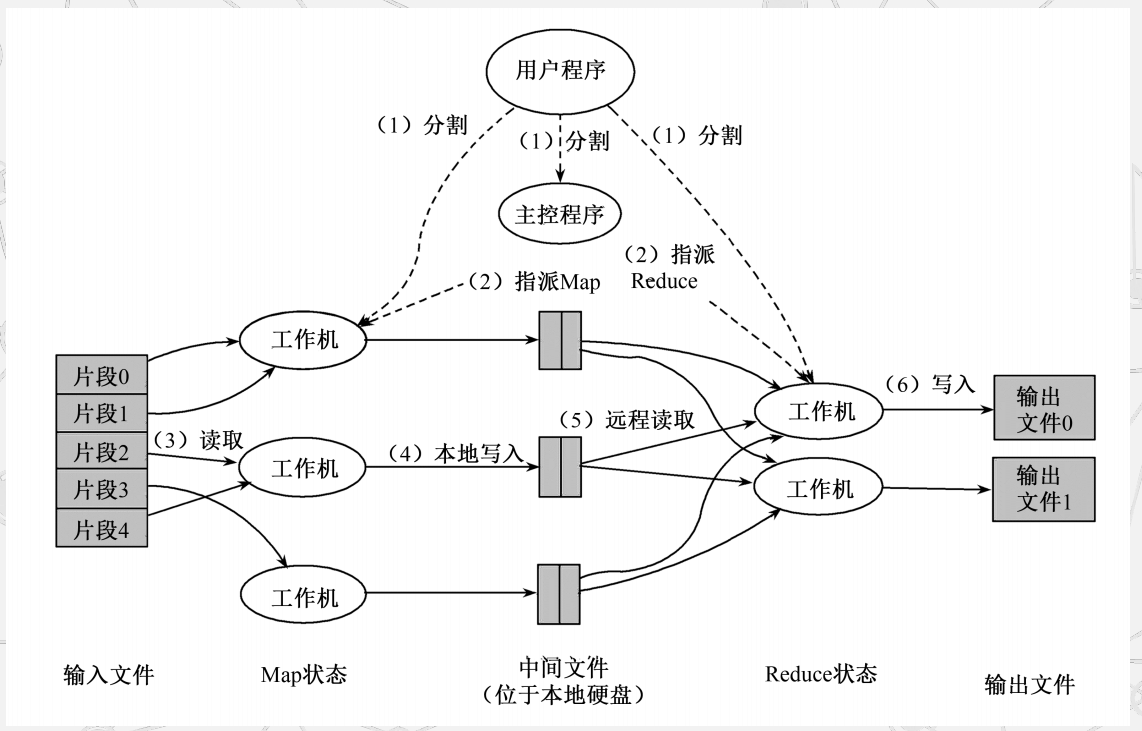
(1)MapReduce函数首先把输入文件分成M块
(2)分派的执行程序中有一个主控程序Master
(3)一个被分配了Map任务的Worker读取并处理相关的输入块
(4)这些缓冲到内存的中间结果将被定时写到本地硬盘,这些数据通过分区函数分成R个区
(5)当Master通知执行Reduce的Worker关于中间<key,value>对的位置时,它调用远程过程,从Map Worker的本地硬盘上读取缓冲的中间数据
(6)Reduce Worker根据每一个唯一中间key来遍历所有的排序后的中间数据,并且把key和相关的中间结果值集合传递给用户定义的Reduce函数
(7)当所有的Map任务和Reduce任务都完成的时候,Master激活用户程序
MapReduce的容错机制:
由于MapReduce在成百上千台机器上处理海量数据,所以容错机制是不可或缺的。总的来说,MapReduce通过重新执行失效的地方来实现容错。
1.Master失效:
Master会周期性地设置检查点(checkpoint),并导出Master的数据。一旦某个任务失效,系统就从最近的一个检查点恢复并重新执行。
由于只有一个Master在运行,如果Master失效了,则只能终止整个MapReduce程序的运行并重新开始。
2.Worker失效:
Master会周期性地给Worker发送ping命令,如果没有Worker的应答,则Master认为Worker失效,终止对这个Worker的任务调度,
把失效Worker的任务调度到其他Worker上重新执行。