第七章 复用类(下)
7.6 protected关键字
现在我们介绍完了继承,关键词protected最终有了意义,在理想世界中,仅靠关键字private就已经足够了,但在实际项目中,经常会想要将某些事物尽可能的对这个世界隐藏起来,但仍然允许导出类的成员访问它们。关键字protected就是起这个作用的。它指明,就类用户而言,这是private的,但对于继承这个类的导出类或其他任何位于同一个包内的类来说,它却是可以访问的。
package com.example.demo; class Villain { private String name; protected void setName(String name) { this.name = name; } public Villain(String name) { this.name = name; } public String toString() { return "My name is " + name; } } public class Orc extends Villain{ private int orcNumber; public Orc(String name, int orcNumber) { super(name); this.orcNumber = orcNumber; } public void change(String name, int orcNumber) { setName(name); this.orcNumber = orcNumber; } public String toString() { return "Orc" + orcNumber + ": " + super.toString(); } public static void main(String[] args) { Orc orc = new Orc("Limburger", 12); System.out.println(orc); orc.change("Bob", 19); System.out.println(orc); } }
输出结果为:
Orc12: My name is Limburger
Orc19: My name is Bob
可以发现change()可以访问set(),这是因为它是protected的。
7.7 向上转型
“为新类提供方法”并不是继承技术中最重要的方面,其最重要的方面是用来表现新类和基类之间的关系,这种关系可以用“新类是现有类的一种类型”来概括。
假设有一个Instrument的代表乐器的基类和一个Wind的导出类,由于继承可以确保基类中所有的方法在导出类中也同样有效,所以能够向基类发送的所有信息同样也可以向导出类发送。如果Instrument类具有一个play()方法,那么Wind乐器也将同样具备,这意味着我们可以说Wind对象也是一种类型的instrument,可以将Wind转换为Instrument引用,我们称之为向上转型。
7.7.1 为什么称向上转型
该术语以传统的类继承图绘制为基础,将根置于页面的顶端,然后逐渐向下,刚才的例子的继承图就如下图所示:
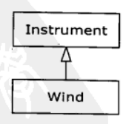
由于导出类转型成基类,在继承图上是向上移动的,因此一般称为向上转型。向上转型是从一个相较比较专用的类型向比较通用的类型转换,所以总是安全的。也就是说,导出类是基类的一个超集,它可以比基类含有更多的方法,但它必须至少具备基类中所有的方法。
7.7.2 再论组合与继承
在面向对象中,生成和使用程序代码最有可能采用的方法就是直接将数据和方法包装进一个类中,并使用该对象,也可以运用组合技术使用现有类来开发新的类,而继承技术其实是不太常用的。我们并不是要尽可能使用继承,继承的使用场合仅限于你确信使用该技术确实有效的情况。
到底是使用组合还是继承,一个最清晰的判断方法就是是否需要从新类向基类进行向上转型,如果必须向上转型,那么继承是必要的,但如果不必要,那么应当好好考虑自己是否需要继承。
7.8 final关键字
根据上下文环境,Java关键字final的含义存在细微的区别,但通常它指的是“这是无法改变的”,不想做改变可能是出于:设计或效率。
7.8.1 final数据
许多编程语言都有某种方法,向编译器告知一块数据时恒定不变的,有时数据的恒定不变是很有用的,比如:
1、一个永不改变的编译时常量
2、一个在运行时被初始化的值,而你不希望它被改变
对于编译器常量这种情况,编译器可以将该常量值带入任何可能用到它的计算式中,也就是说可以在编译时执行计算式,这可以减轻一些运行时的负担。在Java中这类常量必须是基本数据类型,并且以关键字final表示,在对这个常量进行定义的时候必须对其进行赋值。
一个既是static又是final的域值占据一段不能改变的存储空间。
空白final
Java允许生成空白final,所谓空白final是指声明为final但又没有给定初值的域,无论什么情况,编译器都确保空白final在使用前必须被初始化,但空白final在关键字final的使用上提供了更大的灵活性,为此,一个类中的final域就业已做到根据对象而有所不同,却又保持其恒定不变的特性。必须在域的定义处或每个构造器中用表达式对final进行赋值,这正是final域在使用前总是被初始化的原因。
final参数
Java允许在参数列表中以声明的方式将参数指明为final,这意味着你无法在方法中更改参数引用所指向的对象。这一特性主要用来向匿名内部类传递数据。
7.8.2 final方法
使用final方法的原因有两个,第一个是把方法锁定,以防任何继承类修改它的含义,这是出于设计的考虑,想要确保在继承中使方法行为保持不变,并且不会被覆盖。
第二个原因是效率,在最近的Java版本中,虚拟机可以探测到这些情况,并优化去掉这些效率反而降低的额外内嵌调用,因此不再需要使用final方法来进行优化了。事实上这种做法正在逐渐受到劝阻,只有在想要明确禁止覆盖时,才将方法设置为final。
final和private关键字
类中所有的private方法都隐式地指定为是final的,由于无法取用private方法,所以也就无法覆盖它,可以对private方法添加final修饰词,但这并不能给该方法增加任何额外的意义。
“覆盖”只有在某方法是基类的接口的一部分时才会出现,即必须能将一个对象向上转型为它的基本类型并调用相同的方法。如果某个方法为private那它就不是基类的接口的一部分,它仅是一些隐藏于类中的程序代码,只不过是具有相同的名称而已。但如果导出类中以相同的名称生成一个public、protected或者包访问权限方法的话,该方法就不会产生在基类中出现的仅具有想同名称的情况。此时你并没有覆盖该方法,仅仅是生成了一个新的方法。
7.8.3 final类
当将某个类的整体定义为final时就表明你不打算继承该类,而且也不允许别人这样做,换句话说,出于某种考虑,你对该类的设计永不需要做任何变动,或者出于安全的考虑,你不希望它有子类。
final类的域可以根据个人的医院选择是或不是final,不论类是否被定义为final,相同的规则都适用于定义为final类,然而,由于final类禁止继承,所以final类中所有的方法都隐式指定为是final的,因为无法覆盖它们。在final类中可以给方法添加final修饰词,但这不会增添任何意义。
7.9 初始化及类的加载
在许多传统语言中,程序时作为启动过程的一部分立刻被加载的,然后是初始化,紧接着程序开始运行。Java中的所有事物都是对象,每个类的编译代码都存在它自己的独立文件中,该文件只有在需要使用程序代码时才会被加载,加载发生于创建类的第一个对象的时候,但是当访问static域或者static方法时也会发生加载。
7.9.1 继承与初始化
例如:
class Insect { private int i = 9; protected int j; Insect() { System.out.println("i = " + i + ". j = " + j); j = 39; } private static int x1 = printInit("static Insect.x1 initialized"); static int printInit(String s) { System.out.println(s); return 47; } } public class Beetle extends Insect{ private int k = printInit("Beetle.k initialized"); public Beetle() { System.out.println("k = " + k); System.out.println("j = " + j); } private static int x2 = printInit("static Beetle.x2 initialized"); public static void main(String[] args) { System.out.println("Beetle constructor"); Beetle b = new Beetle(); } }
输出结果如下:
static Insect.x1 initialized
static Beetle.x2 initialized
Beetle constructor
i = 9. j = 0
Beetle.k initialized
k = 47
j = 39
在Beetle上运行Java时,发生的第一件事就是访问Beetl.main(),于是加载器开始启动并找出Beetle类的编译代码,在对它进行加载的过程中,编译器注意到他有一个基类,于是继续进行加载,不管你是否打算产生一个该基类的对象,这都会发生。如果基类还有其自身的基类,那么第二个基类就会被加载,以此类推。