一、 Hadoop的分布式模型
Hadoop通常有三种运行模式:本地(独立)模式、伪分布式(Pseudo-distributed)模式和完全分布式(Fully distributed)模式。
安装完成后,Hadoop的默认配置即为本地模式,此时Hadoop使用本地文件系统而非分布式文件系统,而且其也不会启动任何Hadoop守护进程,Map和Reduce任务都作为同一进程的不同部分来执行。
因此,本地模式下的Hadoop仅运行于本机。此模式仅用于开发或调试MapReduce应用程序但却避免了复杂的后续操作。伪分布式模式下,Hadoop将所有进程运行于同一台主机上,但此时Hadoop将使用分布式文件系统,而且各jobs也是由JobTracker服务管理的独立进程。
同时,由于伪分布式的Hadoop集群只有一个节点,因此HDFS的块复制将限制为单个副本,其secondary-master和slave也都将运行于本地主机。此种模式除了并非真正意义的分布式之外,其程序执行逻辑完全类似于完全分布式,因此,常用于开发人员测试程序执行。要真正发挥Hadoop的威力,就得使用完全分布式模式。
由于ZooKeeper实现高可用等依赖于奇数法定数目(an odd-numbered quorum),因此,完全分布式环境需要至少三个节点
二、环境准备
1.部署环境

2.域名解析和关闭防火墙 (所有机器上)
/etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.250 master
192.168.1.249 slave1
192.168.1.248 slave2
关闭 selinux
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/sysconfig/selinux
setenforce 0
关闭 iptables
service iptables stop
chkconfig iptables off
3.同步时间,配置yum和epel源
4.配置所有机器ssh互信
三、安装jdk和配置环境变量(三台同样配置)
[root@master ~]# rpm -ivh jdk-8u25-linux-x64.rpm #安装jdk
Preparing... ########################################### [100%]
1:jdk1.8.0_25 ########################################### [100%]
Unpacking JAR files...
rt.jar...
jsse.jar...
charsets.jar...
tools.jar...
localedata.jar...
jfxrt.jar...
[root@master ~]# cat /etc/profile.d/java.sh #设置java环境变量
export JAVA_HOME=/usr/java/latest
export CLASSPATH=$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
[root@master ~]# . /etc/profile.d/java.sh
[root@master ~]# java -version #查看java变量是否配置成功
java version "1.8.0_25"
Java(TM) SE Runtime Environment (build 1.8.0_25-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.25-b02, mixed mode)
[root@master ~]# echo $JAVA_HOME
/usr/java/latest
[root@master ~]# echo $CLASSPATH
/usr/java/latest/lib/tools.jar
[root@master ~]# echo $PATH
/usr/java/latest/bin:/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
四、安装并配置hadoop
1.安装Hadoop并配置环境变量(master上)
[root@master ~]# tar xf hadoop-2.6.5.tar.gz -C /usr/local
[root@master ~]# cd /usr/local
[root@master local]# ln -sv hadoop-2.6.5 hadoop
"hadoop" -> "hadoop-2.6.5"
[root@master local]# ll
[root@master local]# cat /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@master local]# . /etc/profile.d/hadoop.sh
2.修改以下配置文件(所有文件均位于/usr/local/hadoop/etc/hadoop路径下)
hadoop-env.sh
24 # The java implementation to use.
25 export JAVA_HOME=/usr/java/latest #将JAVA_HOME改为固定路径
core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/Hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondarynamenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
<!-- 设置namenode存放的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/Hadoop/name</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置datanode存放的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/Hadoop/data</value>
</property>
</configuration>
mapred-site.xml
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
masters
slave1 #这里指定的是secondary namenode 的主机
slaves
slave1
slave2
创建相关目录
[root@master local]#mkdir -pv /Hadoop/{data,name,tmp}
3.复制Hadoop安装目录及环境配置文件到其他主机
master上:
[root@master local]# scp -r hadoop-2.6.5 slave1:/usr/local/
[root@master local]# scp -r hadoop-2.6.5 slave:/usr/local/
[root@master local]# scp -r /etc/profile.d/hadoop.sh salve1:/etc/profile.d/
[root@master local]# scp -r /etc/profile.d/hadoop.sh salve2:/etc/profile.d/
slave上(另一台相同操作)
[root@slave1 ~]# cd /usr/local
[root@slave1 local]# ln -sv hadoop-2.6.5 hadoop
"hadoop" -> "hadoop-2.6.5"
[root@slave1 local]# . /etc/profile.d/hadoop.sh
五、启动Hadoop
1.格式化名称节点(master)
[root@master local]# hdfs namenode -format
18/03/28 16:34:20 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.1.250
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.5
.............................................
.............................................
.............................................
18/03/28 16:34:23 INFO common.Storage: Storage directory /Hadoop/name has been successfully formatted. #这行信息表明对应的存储已经格式化成功。
18/03/28 16:34:23 INFO namenode.FSImageFormatProtobuf: Saving image file /Hadoop/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/03/28 16:34:24 INFO namenode.FSImageFormatProtobuf: Image file /Hadoop/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
18/03/28 16:34:24 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/03/28 16:34:24 INFO util.ExitUtil: Exiting with status 0
18/03/28 16:34:24 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.1.250
************************************************************/
2.启动dfs及yarn
[root@master local]# cd hadoop/sbin/
[root@master sbin]# start-dfs.sh
[root@master sbin]# start-yarn.sh
注:其余主机操作相同
查看结果
master上
[root@master sbin]# jps|grep -v Jps
3746 ResourceManager
3496 NameNode
slave1上
[root@slave1 ~]# jps|grep -v Jps
3906 DataNode
4060 NodeManager
3996 SecondaryNameNode
slave2上
[root@slave2 ~]# jps|grep -v Jps
3446 NodeManager
3351 DataNode
六、测试
1.查看集群状态
[root@master sbin]# hdfs dfsadmin -report
18/03/28 21:28:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: 30694719488 (28.59 GB)
Present Capacity: 22252130304 (20.72 GB)
DFS Remaining: 22251991040 (20.72 GB)
DFS Used: 139264 (136 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.1.249:50010 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 15347359744 (14.29 GB)
DFS Used: 69632 (68 KB)
Non DFS Used: 4247437312 (3.96 GB)
DFS Remaining: 11099852800 (10.34 GB)
DFS Used%: 0.00%
DFS Remaining%: 72.32%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Mar 28 21:28:02 CST 2018
Name: 192.168.1.248:50010 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 15347359744 (14.29 GB)
DFS Used: 69632 (68 KB)
Non DFS Used: 4195151872 (3.91 GB)
DFS Remaining: 11152138240 (10.39 GB)
DFS Used%: 0.00%
DFS Remaining%: 72.66%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Mar 28 21:28:02 CST 2018
2.测试YARN
可以访问YARN的管理界面,验证YARN,如下图所示:
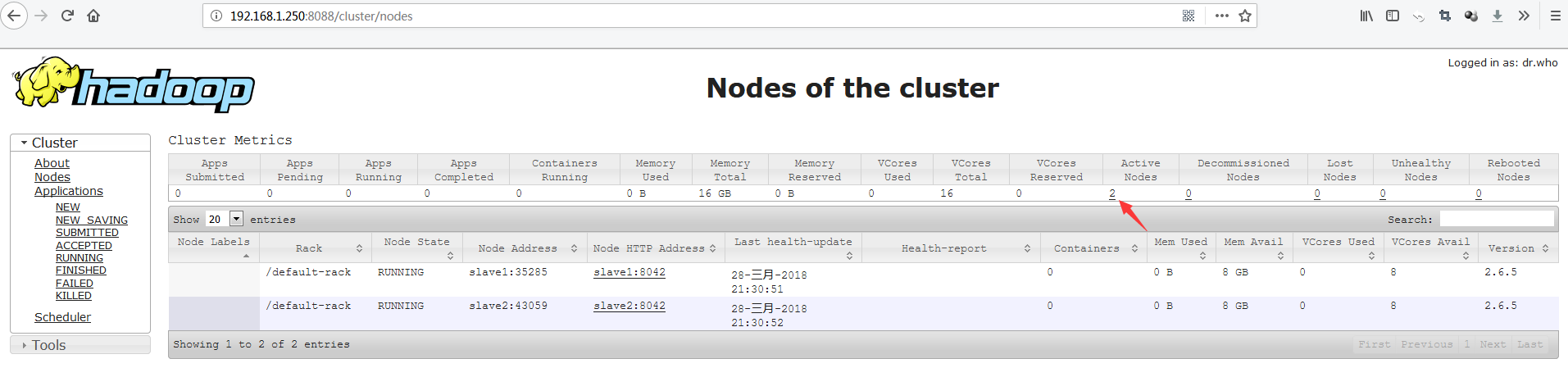
3. 测试查看HDFS
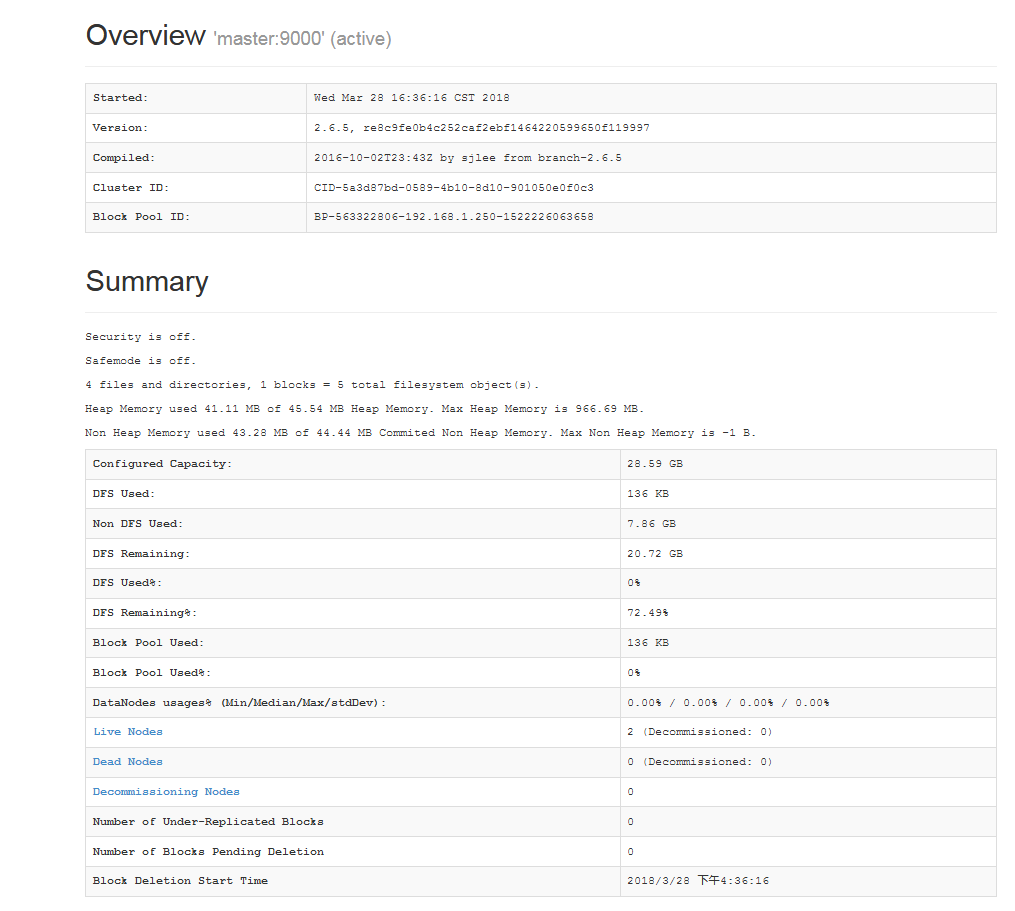
4.测试向hadoop集群系统提交一个mapreduce任务
[root@master sbin]# hdfs dfs -mkdir -p /Hadoop/test
[root@master ~]# hdfs dfs -put install.log /Hadoop/test
[root@master ~]# hdfs dfs -ls /Hadoop/test
Found 1 items
-rw-r--r-- 2 root supergroup 28207 2018-03-28 16:48 /Hadoop/test/install.log
可以看到一切正常,至此我们的三台hadoop集群搭建完毕。
其他问题:

原因及解决办法见此链接:https://blog.csdn.net/l1028386804/article/details/51538611