目前大数据存储有两种方案可供选择:行存储和列存储。业界对两种存储方案有很多争持,集中焦点是:谁能够更有效地处理海量数据,且兼顾安全、可靠、完整性。从目前发展情况看,关系数据库已经不适应这种巨大的存储量和计算要求,基本是淘汰出局。在已知的几种大数据处理软件中,Hadoop的HBase采用列存储,MongoDB是文档型的行存储,Lexst是二进制型的行存储。在这里,我不讨论这些软件的技术和优缺点,只围绕机械磁盘的物理特质,分析行存储和列存储的存储特点,以及由此产生的一些问题和解决办法。
一。结构布局
行存储数据排列
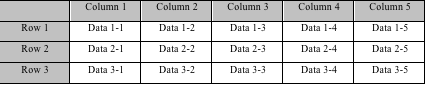
列存储数据排列

表格的灰色背景部分表示行列结构,白色背景部分表示数据的物理分布,两种存储的数据都是从上至下,从左向右的排列。行是列的组合,行存储以一行记录为单位,列存储以列数据集合单位,或称列族(column family)。行存储的读写过程是一致的,都是从第一列开始,到最后一列结束。列存储的读取是列数据集中的一段或者全部数据,写入时,一行记录被拆分为多列,每一列数据追加到对应列的末尾处。
二. 对比
从上面表格可以看出,行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多,再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。 数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。列存储每次读取的数据是集合的一段或者全部,如果读取多列时,就需要移动磁头,再次定位到下一列的位置继续读取。 再谈两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。