一 数据库索引
数据库索引是数据库管理系统中一个排序的数据结构,以协助快速查询,更新数据库表中的数据。
1.1 索引及分类
1.1.1 索引的概念
索引是一种特殊的文件,包含着对数据库表中所有记录的引用指针,通俗的讲,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
1.1.2 索引的引用
建立索引的目的是加快对表中记录的查找和排序。为表设置索引要付出代价:一是增加了数据库的存储空间,二是在插入或修改数据时要花费更多的时间(因为索引也要随之改动),但是相比付出代价,索引的作用更为重要: 1.设置了合适的索引之后,数据库利用各种快速定位技术,可以大大加快数据的查询速度,这是创建索引最重要的原因。 2.当表很大时,或查询涉及到多个表时,使用索引可以使查询速度加快上千倍 3. 可以降低数据库的io成本,并且索引还可以降低数据库的排序成本 4. 通过创建唯一索引,可以保证数据库中每一行的数据的唯一性 5.加快表与表之间的连接 6.在使用分组和排序字句进行数据查询时,可以显著减少查询中分组和排序的时间
1.1.3 索引的分类
mysql的索引可以分为以下几类: 1.普通索引:最基本的索引类型,而且没有唯一性之类的限制 2.唯一性索引:索引列的值只能出现一次,即必须唯一。当现有数据中存在重复的键时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键的新数据。例如,若果在employee表中职员的姓上创建了唯一索引,则任何两个员工都不能同姓。 3.主键索引,是一种唯一性索引,在数据库中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每一个值都唯一。 4.全文索引,索引类型是FULLTEXT,全文索引可以在CHAR,VARCHAR或者TEXT类型的列上创建 5.单列索引与多列索引,索引可以是单列上创建的索引,也可以是多列上创建的索引。多列索引可以区分其中一列可能有相同值得行。如果经常同时搜索两列或多列或按两列或多列排序时,索引也很有帮助。例如,经常在同一查询中为姓和名两列设置查询条件,那么在这两列上创建多列索引将很有意义。
1.1.4 创建索引的原则依据
索引可以提升数据库查询的速度,但并不是任何情况下都要创建索引。因为索引本身也会消耗系统资源,更重要的是在有索引的情况下,数据库查询会先进行索引查询,然后定位到具体的数据行,如果索引使用不当,反而会增加数据库的负担,下面列出创建索引的原则依据。 1.表的主键,外键必须有索引。主键具有唯一性,索引值也是唯一的,查询可以快速定位到数据行。外键一般关联的是另一个表的主键,所以在多表查询时也可以进行快速定位。 2.数据量超过300行的表应该有索引。数据量较大时,如果没有索引,需要把表建立一遍,严重影响数据库的性能。 3.经常与其他表进行表连接的表,在连接字段上应该建立索引。 4.唯一性太差的字段不适合建立索引。如果查询字段的数据唯一性太差,是不适合创建的。比如某表有一万行某个字段是“攀少”,那么他们的索引值是相同的,如果创建索引查询,数据库需要匹配这一万行的索引值,然后在定位数据表中的数据,并不能提升查询速度,反而会将慢。 5.更新太频繁的字段不适合创建索引。在表中进行增加,删除,修改操作时,索引也有相应操作产生。字段更新得过于频繁,对于系统资源占用的也会比较多。
二 mysql事务
数据库事务是指作为单个逻辑工作单元执行的一系列操作,要么完整的执行,要么完整的不执行,最终操作成功。但是如果在这个过程中任何一个环节出了差错,数据库中所有的信息都必须保持第一步操作前的状态不变,否则数据库的信息将会是一片混乱而不可预测。
1.2.1事务的概念及特点
1.事务的概念
事务是一种机制,一个操作系列,包含了一组数据库的操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这组数据库命令要么都执行,要么都不执行。事务是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是最小的控制单元。通过事务的整体性以保证数据的一致性,事务是保证一组操作的平稳性和可预测的技术。
2.事务的ACID特性
事务具体有四个特性:原子性,一致性,隔离性,持久性 1.原子性:事务是一个完整的操作,各个元素之间是不可分的,即原子的。事务中的所有元素必须作为一个整体提交或回滚。如果事务中任何元素失败,则整个事务将失败。 2.一致性:当事务完成时,数据必须处于一致状态;在事务开启之前,数据库存储的数据处于一致状态;在正在进行的事务中,数据可能处于不一致状态;当事务完成时,数据必须再次回到已知的一致状态。 3.隔离性:对数据进行修改的所有的并发事务是彼此隔离的,这表明事务必须是独立的,不应以任何方式依赖于或影响其他事务。修改数据的事务可以在另一个使用相同数据的事务开启之前访问这些数据,或者在另一个使用相同数据的事务结束之后访问这些数据。 4.不管系统是否发生了故障,事务处理的结果都是永久的。一旦事务被提交,事务的效果会被永久的保存在数据库中。
1.2.2 事务的操作
1.mysql操作事务
默认情况下mysql的事务是自动提交的。之前我们用sql操作数据库时,一条语句执行后,系统会自动执行事务的提交。当需要把一组语句作为一个事务提交时,需要手动对事务进行控制。手动控制事务有两种方法,一种是使用事务处理命令控制,另一种是使用set设置事务的处理方式。
2.使用事务命令控制事务
mysql中使用命令控制事务需要用到三个命令:】 1.begin:表示开始一个事务,后面会有多条数据库操作语句执行 2.commit: 表示事务的提交,对应前面的begin操作,他们之间的数据库操作语句一起完成。 3.rollback:表示回滚一个事务,在begin与commit之间,如果某一个数据库操作语句出现错误,执行rollback进行回滚,数据库回到begin之前的状态,也就是操作语句并没有执行。
(1)下面演示事务命令的使用方式,假设需要往数据表IT_salary中插入两条数据,他们在一个事务中提交
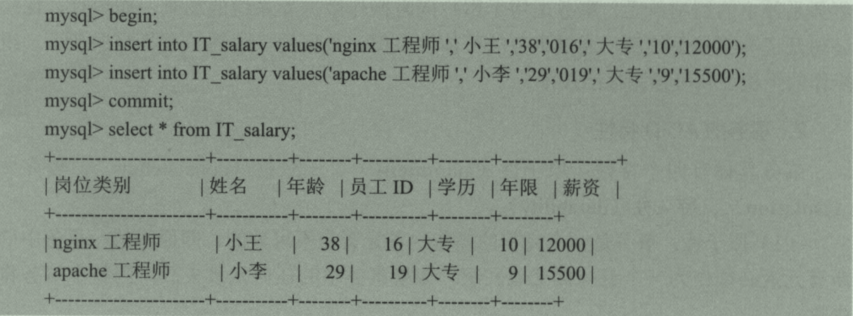
使用begin开始事务,然后执行两条插入语句,最后用commit提交事务,此时两条数据插入到了数据表中,这两条语句作为一个整体的操作
(2)上面的例子演示了事务的基本操作方式,如果用begin开始事务,但不使用commit提交会出现什么情况。

可以看出依然能查询出插入的数据,但这只是在当前开启的事务中可以看到,因为没有提交,他们并不是真正的插入到了数据库中。现在退出mysql的连接,重新进入mysql再进行查询。

此时数据库中并没有之前插入的数据,说明使用begin开始事务,执行操作语句后,必须使用commit进行提交,否则数据是不可能自动提交的,也就是多条数据语句操作语句作为一个整体需要使用commit进行整体的事务提交。
(3)rollback回滚的使用,假设插入一条数据后,需要恢复到插入前数据库的状态,使用rollback执行事务的回滚

可以看到,使用begin开始事务,然后执行了插入命令,查询表数据可以看到插入的数据,但是执行rollback回滚命令之后,再查看表数据,先前插入的数据已经没有了,rollback使数据表回滚到begin开始之前的状态。
(4)很多时候一个事务会包含多条语句,而出现问题需要回滚时,并不一定要回滚到begin之前的状态,有可能是某条语句执行后的状态,这时候要使用savepoint定义回滚点,rollback决定回滚到的位置。

执行第一条插入语句之后,定义了回滚点S1,执行第二条插入语句后,定义了回滚点S2,如果后面直接使用rollback命令,这两条插入语句都将失效,现在使用回滚点进行回滚。

回滚到了S1,第一条插入的数据可以查询出来,但是并没有提交,如果需要保存到数据库,使用commit进行提交。
3. 使用set设置控制事务
前面已经提到mysql默认是自动提交事务,也可以修改为不提交,使用set命令进行操作:
set autocommit = 0;禁止自动提交
set autocommit = 1;开启自动提交
(1)实际上mysql启动时autocommit的值默认是1,修改为0,则需要手动提交,也就是前面所说的commit命令,回滚使用rollback命令。
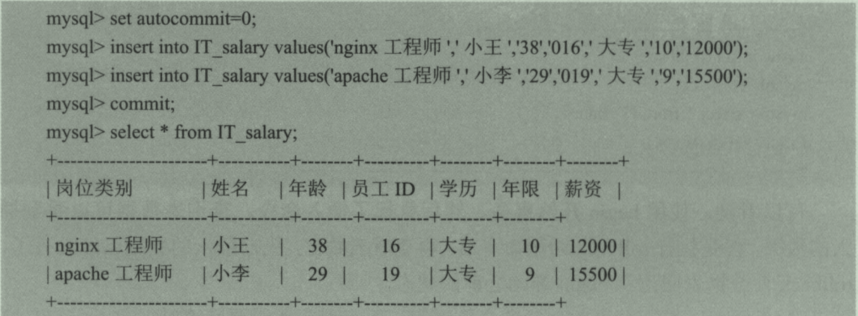
使用set autocommit = 0 设置禁止自动提交,最后用commit自动提交事务。
(2)set autocommit = 0 设置禁止自动提交,不使用commit提交的操作语句,和使用begin的情况相同,执行的语句都会失效。可以看到如果不使用commit提交事务,退出mysql重新进入后,插入的数据不存在。