原文:
https://rsbeoriginal.medium.com/partitioning-with-postgresql-v11-6fe5388c6e98
- What — Partitioning is splitting one table into multiple smaller tables.
- When — It is useful when we have a large table and some columns are frequently occurring in
WHEREclause when we the table is queried. Let’s supposeBooktable in library management system, so here inventory of books can be huge and will always be increasing. But, the general queries over theBooktable will basically be about the book status (borrowed/not borrowed or available/not available). Here, we observe that most queries on book table would be on attributestatus. So, it would be better to split theBooktable based on attributestatus.
It’s not necessary that in every use case, we can find the field on which we want to split,
Partition Key.
- Why — One most obvious benefit that we can get from partitioning is query performance, if we are able to identify partition key which is being frequently used in most queries. Other benefits could be efficient usage of memory. For example, if data is partitioned based on time or usage, then older or less used data can be migrated to cheaper or slower storage media.
Partitioning won’t help much if the partitions are highly skewed
- How — That’s what the article is all about !
Types
- Range Partition — It can be used when we want to create partition on range of values of attribute. For example, like employee data can be partitioned based on age like 20–30, 30–40, 40–50 etc. or like medium can partition the articles based on month of publishing an article.
- List Partition — It can be used when we want to create partition on a list of values, for example,
statusattribute in the book table can have 2 values (borrowed /not borrowed), so book table can be partitioned for each status. - Hash Partition — It can be used to distribute the data among the partitions when we aren’t sure whether range or list partition would give us uniform distribution among partitions but we have growing data to be distributed evenly in partitions. It is done by specifying modulus and remainder for each partition. It is compatible with all data typesIn this article, we’ll be using PostgreSQL 11.
Most of the systems which are built are guided by some process or flows. Each process can have multiple stages/statuses, like when we initiate a process then status might be START and then it move to IN_PROGRESS and multiple intermediary status and then finally to DONE / COMPLETE status. So for general purpose here we’ll take table name as process .
Note: Never keep table name as
processas it’s a verb
We’ll start with creating 2 tables:
process— Normal tableprocess_partition— Partition table with partition key asstatus
Both these process tables will contain
id— Auto-incremented idnamestatus— possible values for statusOPEN,IN_PROGRESSandDONE
Let’s start by creating process table first
CREATE TABLE process
(
id bigserial,
name character varying(255) ,
status character varying(255) ,
CONSTRAINT process_pk_id PRIMARY KEY (id)
);
Now, we’ll create process_partition table

CREATE TABLE process_partition
(
id bigserial,
name character varying(255) ,
status character varying(255) NOT NULL,
CONSTRAINT process_partition_pk_id PRIMARY KEY (id, status)
) PARTITION BY LIST (status);
-- Partitions SQL
CREATE TABLE process_partition_done PARTITION OF process_partition
FOR VALUES IN ('DONE');
CREATE TABLE process_partition_in_progress PARTITION OF process_partition
FOR VALUES IN ('IN_PROGRESS');
CREATE TABLE process_partition_open PARTITION OF process_partition
FOR VALUES IN ('OPEN');
Here we have created a master table process_partition and perform a list partition on it with partition key as status . We have created 3 partition of the master table based on each status, process_partition_open for OPEN , process_partition_in_progress for IN_PROGRESS and process_partition_done for DONE status.
If we want to use status as partition key, then we are forced to add it in primary key also. Similarly if we have any Unique key constraint, then we’ll need to add the partition key there also. If we don’t, then we’ll get error while creating table.


Now, we’ll add around 10000 rows first in each status of the 3 status.
DO $$
BEGIN
FOR i in 1..10000 LOOP
INSERT INTO process(name, status) VALUES ('Process Name', 'OPEN');
INSERT INTO process(name, status) VALUES ('Process Name', 'IN_PROGRESS');
INSERT INTO process(name, status) VALUES ('Process Name', 'DONE');
END LOOP;
END; $$

Similarly we’ll add in process_partition table also.
DO $$
BEGIN
FOR i in 1..10000 LOOP
INSERT INTO process_partition(name, status) VALUES ('Process Name', 'OPEN');
INSERT INTO process_partition(name, status) VALUES ('Process Name', 'IN_PROGRESS');
INSERT INTO process_partition(name, status) VALUES ('Process Name', 'DONE');
END LOOP;
END; $$



Here we see that, when we count only process_partition table then there are 0 rows. This is because all the rows which we inserted are split into 3 partition tables process_partition_open, process_partition_in_progress and process_partition_done .
So here we saw that we executed insert statement on the master table process_partition , but based on the value of the status column each row is added to respective partition and total rows of master table are the aggregation of all partition tables.
So now let’s insert a new row and then try to change status and observe the behaviour.
INSERT INTO process_partition(name, status) VALUES ('Moving process', 'OPEN')
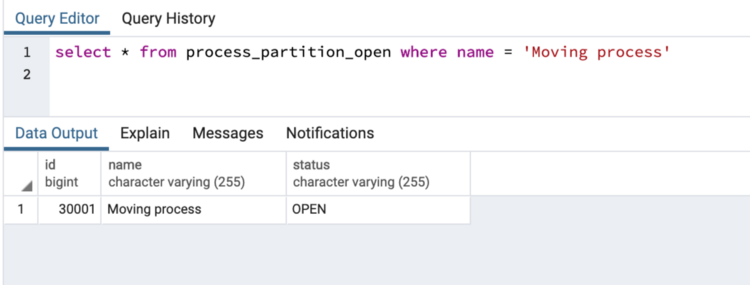
process_partition_open with id 30001
We add this row to master table which has id : 30001 and as it’s in OPEN status, so it automatically moves to process_partition_open .
Now, we’ll update this row to IN_PROGRESS status.
UPDATE process_partition SET status = 'IN_PROGRESS' WHERE name = 'Moving process' AND status = 'OPEN';
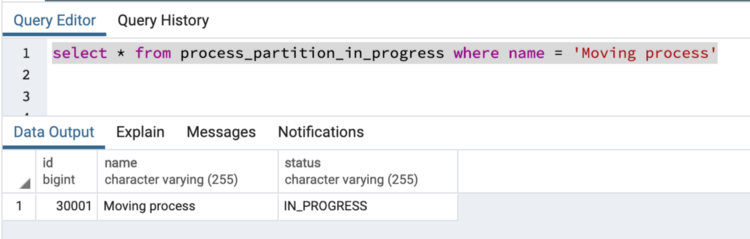
process_partition_in_progress
Now, if we query the process_partition_open table that row is not there instead that row has moved to process_partition_in_progress table. So, we observe that there is movement of rows from one partition to other when there is change in status, i.e partition key.
Below are the results for 30000 rows and when data is increased 10x times to 300000 rows.




Let’s try to understand above results and how and why there is improvement in query cost when we are doing partition. In unpartitioned table we have whole data dump which is very large, so it takes time to do a sequential scan. But when we partition the table and also add partition key in the WHERE clause then there’s significant improvement in performance as there’s significant difference in the amount of data which the query has to scan. So, here we specify status to filter out the data. In partitioned table we see that sequential scan is only on process_partition_open table.

In above image, in the query we didn’t add partition key, i.e., status in the WHERE clause so postgres doesn’t know which partition to scan, so it scans all the partitions. This case becomes similar to unpartitioned table because in query we are not using partition key.
You can also check the difference on partition table by switching enable_partition_pruning ON and OFF. You can use below statement to check the value for enable_partition_pruning
SHOW enable_partition_pruning;
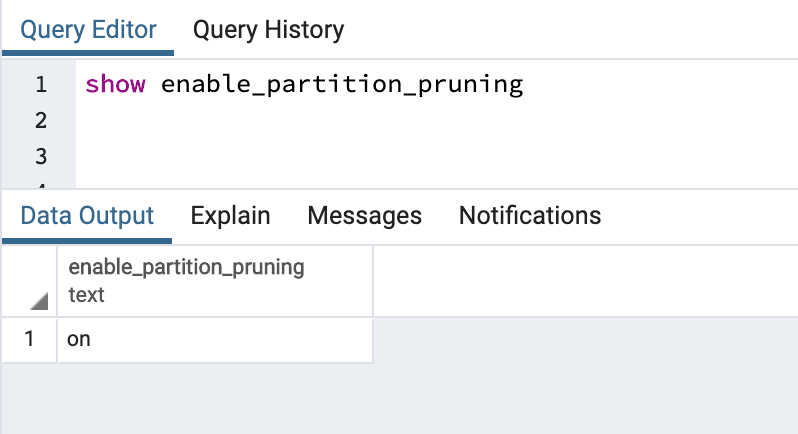

enable_partition_pruning = on
When partition pruning is enabled, then partition key is used to identify which partition(s) the query should scan. When status = OPEN is provided in WHERE clause then query only scans process_partition_open table because it contains all rows whose status is OPEN.
We can disable enable_partition_pruning , using below statement.
SET enable_partition_pruning = off

enable_partition_pruning = off
After disabling partition pruning we see that even if we provide partition key, i.e., status, in WHERE clause, all the partitions of process_partition table are scanned.
That’s it, Folks !
For further reading on partition, next article in series is Sub-Partitioning and Attach/Dettach partitions
References
https://www.postgresql.org/docs/11/ddl-partitioning.html
Best Practices — https://www.postgresql.org/docs/11/ddl-partitioning.html#DDL-PARTITIONING-DECLARATIVE-BEST-PRACTICES