一、介绍:
HashMap是java集合框架中常用的数据结构,其本质是一个Entry结构的数组和链表组成,即主体是长度为2的幂的数组,里面的元素为链表结构。接下来,我们来分析他的源码组成。
二、源码分析:

在阅读源码之前,我们先看看,再集合框架中,HashMap的继承关系。HashMap根据 key 的 hashCode 值l来定位存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度(数组的查找操作是线性的)。HashMap 非线程安全,举例子来说,当在查找hashcode时,若对某一线程返回true,如果此时恰好有一删除操作,会造成死锁。如果需要满足线程安全,可以用 Collections的synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用ConcurrentHashMap 。
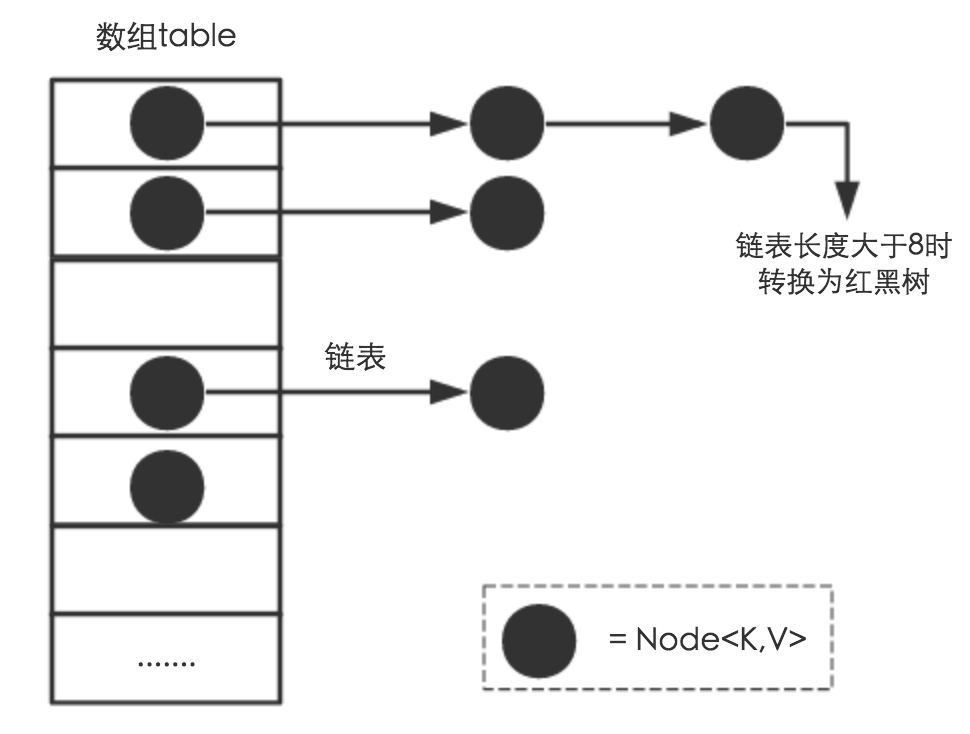
HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,为了方便分析这里依然采用JDK1.6。实现HashMap,首先定义一个Map类的接口,再集合框架中,HashMap引用Map接口。
1 interface DIYMap<K, V>{ 2 public V put(K k,V v) ; 3 public V get(K k,V v) ; 4 5 6 public interface Entry<K,V>{ 7 Entry<?, ?> next = null; 8 public K getKey() ; 9 public V getValue() ; 10 } 11 }
接下来正式自定义HashMap实现类:
1 public class DIYHashMap<K,V> implements DIYMap<K,V> { 2 public DIYHashMap(int defalutLength, double defalutAddSizeFactor){ 3 if(defalutLength < 0){ 4 throw new IllegalAccessError("数组长度为负数") ; 5 } 6 7 if(defalutAddSizeFactor<=0 || Double.isNaN(defalutAddSizeFactor)){ 8 throw new IllegalAccessError("扩容长度不能为非正数字"); 9 } 10 11 this.defalutAddSizeFactor = defalutAddSizeFactor ; 12 this.defalutLength = tableSizeFor(defalutLength) ; 13 14 } 15 16 }
这里是自定义HashMap的构造函数,在jdk源码中,总共有四个构造函数方便调用。里面的参数代表含义如下:
//定义初始化默认数组长度 ; private int defalutLength = 16 ; //定义默认负载因子 ; private double defalutAddSizeFactor = 0.75 ; //使用数组位置的总数 private int useSize ; //定义骨架Entry数组 ; private Entry<K,V>[] table ;
tableSize()函数是为了保证数组长度为2的幂(即定义new DIYHashMap(5),得到的数组长度是8),为什么长度一定要是2的次幂?下文会总结一下,主要是为了hash散列的时候保持分布均匀,提高空间的利用效率。
1 public int tableSizeFor(int n ){ 2 int num = n-1 ; 3 num |= num>>>1; 4 num |= num>>>2; 5 num |= num>>>4; 6 num |= num>>>8; 7 num |= num>>>16; 8 9 return (num<0) ? 1:((num>= 1<<30)? 1<<30 : num+1) ; 10 }
在实现Map接口的同时,要实现内部接口Entry,即定义数组的存储类型。
1 private class Entry<K,V> implements DIYMap.Entry<K,V>{ 2 Entry<K,V> next = null; 3 K k; 4 V v; 5 public Entry(K k,V v,Entry<K,V> next){ 6 this.k = k; 7 this.v = v; 8 this.next = next ; 9 } 10 @Override 11 public K getKey() { 12 // TODO Auto-generated method stub 13 return k; 14 } 15 16 @Override 17 public V getValue() { 18 // TODO Auto-generated method stub 19 return v; 20 } 21 22 23 }
以上就是HashMap的初始化,在jdk源码中,依然是按照这样的流程进行初始化构造。在一开始数组是没有分配长度的,在put的时候才会初始化数组长度。
1 @Override 2 public V put(K k, V v) { 3 if(table.length==0 || useSize > defalutLength * defalutAddSizeFactor){ 4 up2Size() ; 5 } 6 7 int index=getIndex(k,table.length) ; 8 Entry<K,V> entry =table[index] ; 9 Entry<K,V> newEntry =new Entry<K, V>(k, v, null) ; 10 11 if(entry == null){ 12 table[index] = newEntry ; 13 useSize++ ; 14 }else{ 15 Entry<K,V> tmp; 16 while((tmp=table[index])!=null){ 17 tmp=tmp.next ; 18 } 19 tmp.next = newEntry ; 20 } 21 return newEntry.getValue() ; 22 }
首先,在put一个元素之前,进行检查,看当前已经使用的容量useSize 是否超过了当前的负载因子,或者是不是没有进行数组分配。如果是,会先进行扩容方法,将数组进行初始化,或者进行2倍扩展。up2Size()逻辑下面会解释。接下来会求出需要put的元素被放置的索引getIndex(),这里面就是主要的hash散列算法。如果求出来的索引所在的table[index]==null,就可以将put的(k,v)赋值给它,useSize++;如果不为空,证明发生了hash冲突,需要将新值放在table[index].next位置。
1 //扩展数组长度 ; 2 public void up2Size(){ 3 Entry<K,V>[] newTable = new Entry[defalutLength*2] ; 4 5 ArrayList<Entry<K,V>> entryList = new ArrayList<Entry<K,V>>() ; 6 for(int i=0;i<table.length;i++){ 7 if(table[i] == null){ 8 continue ; 9 } 10 //查找是否形成链表 11 findEntryByNext(table[i], entryList) ; 12 } 13 if(entryList.size() >0){ 14 useSize =0; 15 defalutLength = defalutLength*2 ; 16 table=newTable ; 17 for(Entry<K,V> entry : entryList){ 18 if(entry.next != null){ 19 entry.next = null ; 20 } 21 put(entry.getKey(), entry.getValue()) ; 22 } 23 }else{ 24 table = new Entry[defalutLength] ; 25 } 26 27 }
在up2Size()函数中,重点在于已经形成链表的数据如何进行重新划分。这里采用ArrayList将旧的所有的元素导出来,重新进行hash计算新的index进行导入到新的数组中。其中重点就是找到已经形成链表的数据。
1 public void findEntryByNext(Entry<K, V> entry, ArrayList<Entry<K, V>> entryList){ 2 if(entry!= null && entry.next != null){ 3 entryList.add(entry) ; 4 findEntryByNext(entry.next, entryList) ; 5 }else 6 entryList.add(entry) ; 7 }
写到这里,一个put函数其实已经差不多了,这里面的重点在于hash算法,如何保证分布的均匀性。
1 private int getIndex(K k,int length ){ 2 int m=length-1 ; 3 int hashCode = k.hashCode() ; 4 hashCode = hashCode^((hashCode>>>7)^(hashCode>>>12)) ; 5 hashCode = hashCode^(hashCode>>>7)^(hashCode>>>4) ; 6 7 int index = hashCode & m ; 8 9 return index >=0 ?index :-index ; 10 }
(分析待续。。。)
get方法比put要简单一些,本质上也是计算key的hashcode,并且得到index是否有值。希望下来自己再写一下。