
1、关于DMA(原文)
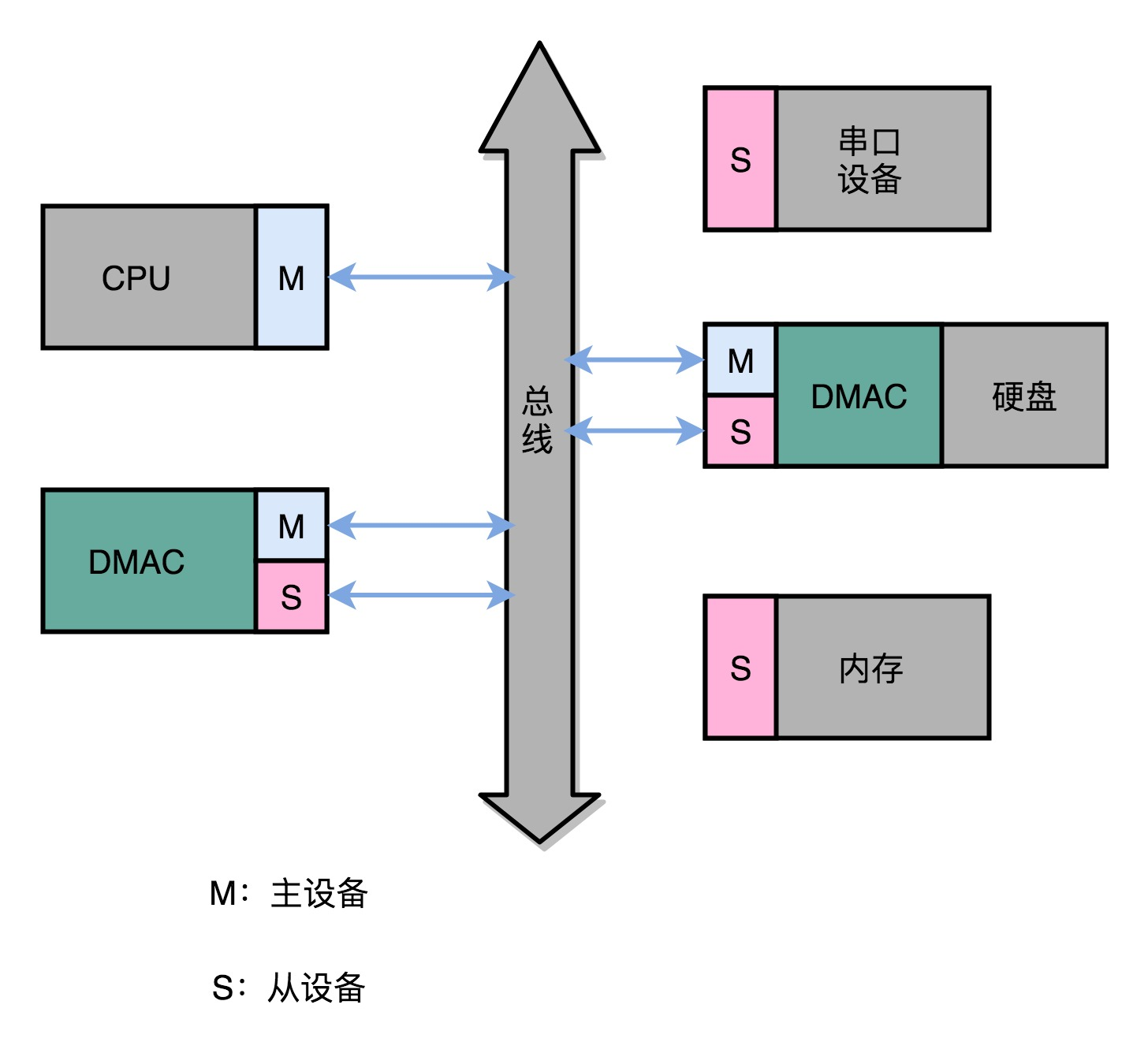
DMA 技术,也就是直接内存访问(Direct Memory Access)技术,来减少 CPU 等待的时间。无论 I/O 速度如何提升,比起 CPU,总还是太慢。SSD 硬盘的 IOPS 可以到 2 万、4 万,但是 CPU 的主频有 2GHz 以上,也就意味着每秒会有 20 亿次的操作。对于 I/O 的操作,都是由 CPU 发出对应的指令,然后等待 I/O 设备完成操作之后返回,那 CPU 有大量的时间其实都是在等待 I/O 设备完成操作。
DMA 技术就是在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,可以认为它其实就是一个协处理器(Co-Processor)。DMAC 最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
整个数据传输的过程中,不是通过 CPU 来搬运数据,而是由 DMAC 这个芯片来搬运数据。但是 CPU 在这个过程中也是必不可少的。因为传输什么数据,从哪里传输到哪里,其实还是由 CPU 来设置的。这也是为什么,DMAC 被叫作“协处理器”。
2、Kafka 的实现原理
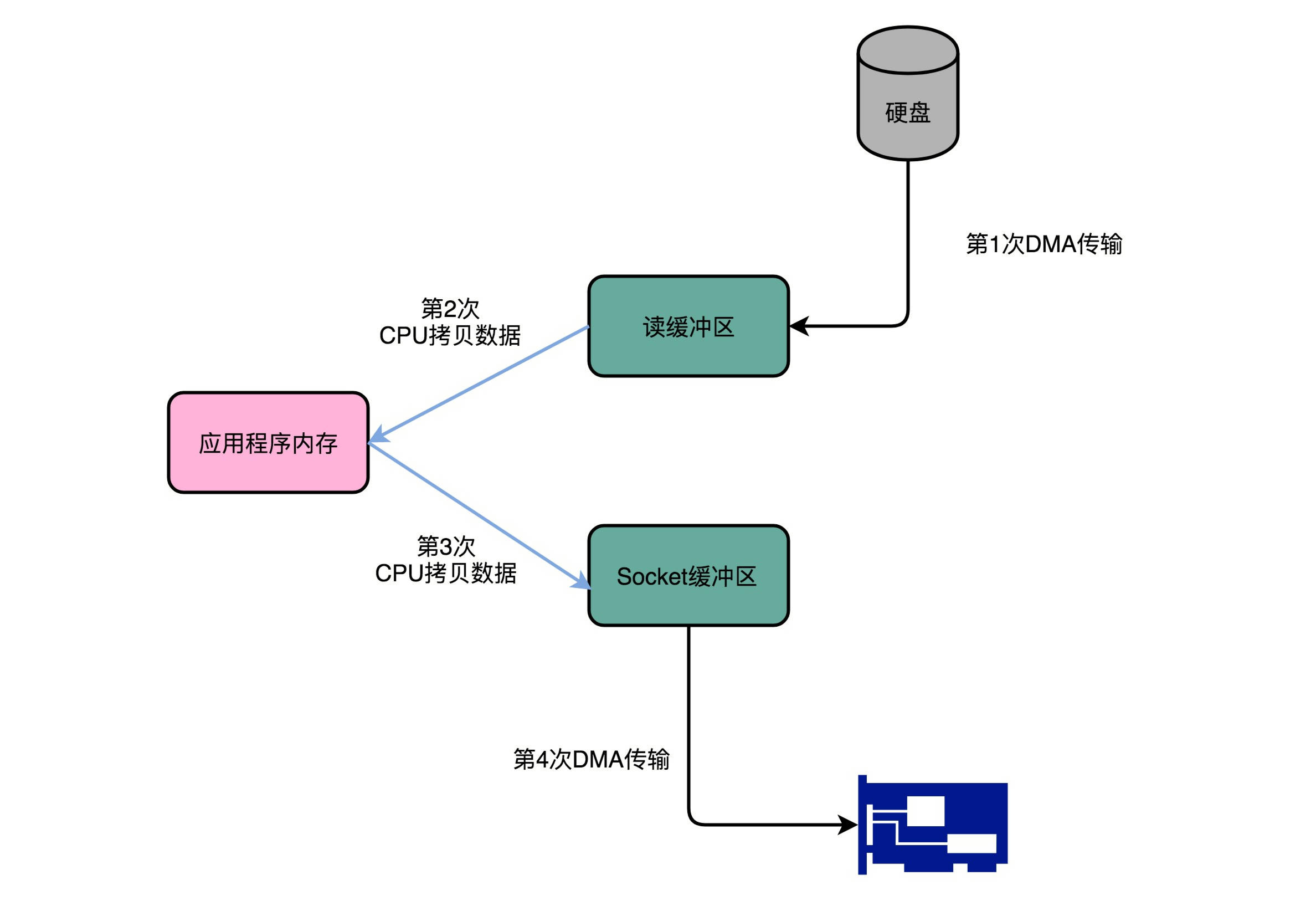
Kafka 是一个用来处理实时数据的管道,常常用它来做一个消息队列,或者用来收集和落地海量的日志。作为一个处理实时数据和日志的管道,瓶颈自然也在 I/O 层面。Kafka 里面会有两种常见的海量数据传输的情况。一种是从网络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失。另一种情况呢,则是从本地磁盘上读取出来,通过网络发送出去。从磁盘读数据发送到网络上去。如果我们自己写一个简单的程序,最直观的办法,自然是用一个文件读操作,从磁盘上把数据读到内存里面来,然后再用一个 Socket,把这些数据发送到网络上去。
3、关于数据完整性(原文)
ECC 内存的全称是 Error-Correcting Code memory,中文名字叫作纠错内存。顾名思义,就是在内存里面出现错误的时候,能够自己纠正过来。
最知名的纠错码就是海明码。海明码(Hamming Code)是以他的发明人 Richard Hamming(理查德·海明)的名字命名的。
4、分布式计算(原文)
关于升级服务器选择的概念:
垂直拓展:提升单台服务器性能,例如,服务器的硬件由1 个 CPU 核心、3.75G 内存以及一块 10G 的 SSD 系统盘,变成 2 个 CPU 核心、7.5G 内存
水平拓展:增加一台一样配置的服务器
垂直扩展背后的逻辑和优势都很简单。一般来说,垂直扩展通常不需要我们去改造程序,也就是说,没有研发成本。但是随着流量不断增长。到最后,只会变成一个选择。那就是既会垂直扩展,又会水平扩展,并且最终依靠水平扩展,来支撑 Google、Facebook、阿里、腾讯这样体量的互联网服务。
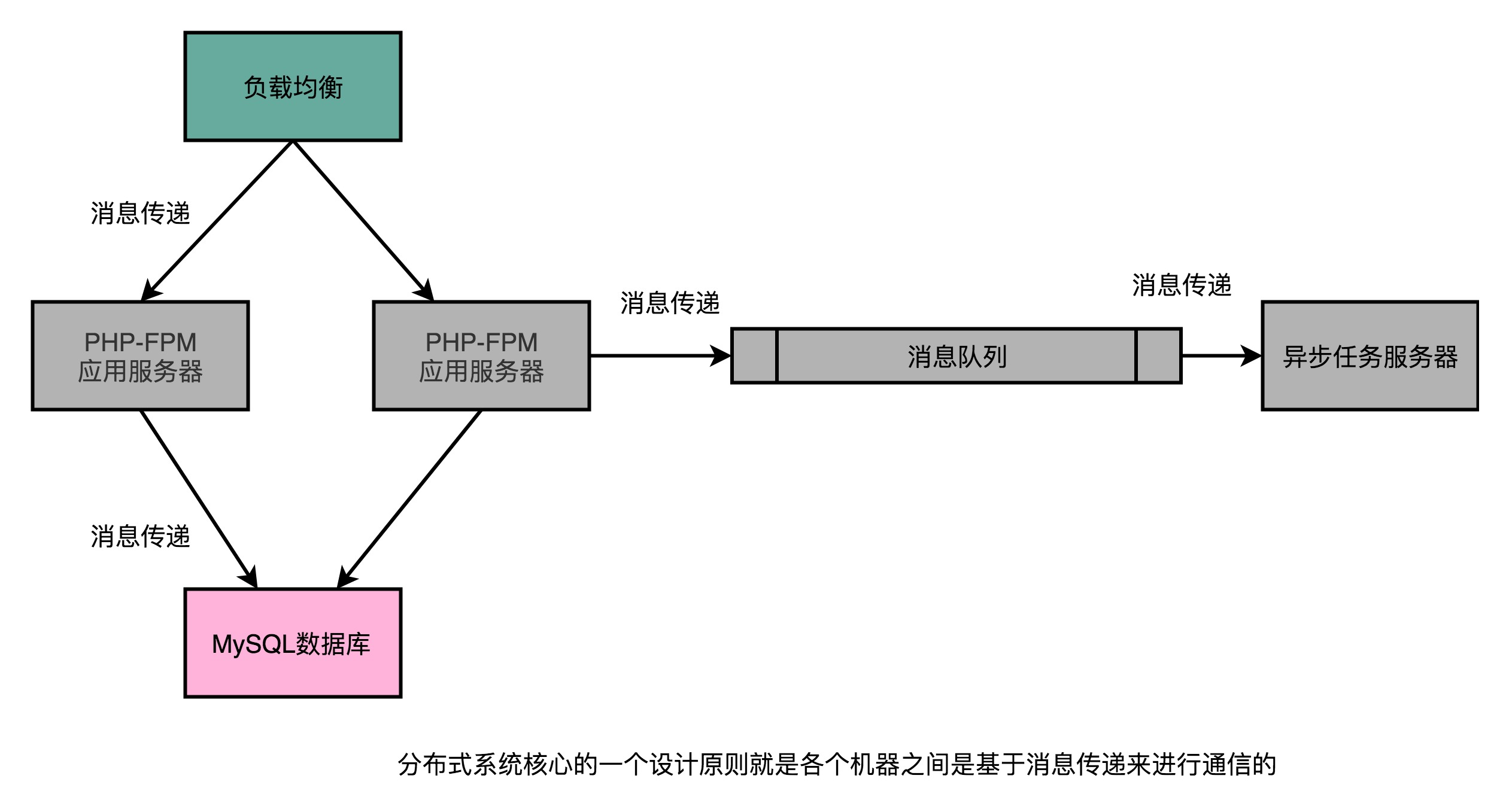
一旦开始采用水平扩展,就会面临在软件层面改造的问题了。也就是需要开始进行分布式计算了。需要引入负载均衡(Load Balancer)这样的组件,来进行流量分配。需要拆分应用服务器和数据库服务器,来进行垂直功能的切分。也需要不同的应用之间通过消息队列,来进行异步任务的执行。
5、高可用性和单点故障
垂直扩展的方式,扩展完之后,还是只有 1 台服务器。如果这台服务器出现了一点硬件故障,比如,CPU 坏了,那整个系统就坏了,就不可用了。
如果采用了水平扩展,即便有一台服务器的 CPU 坏了,还有另外一台服务器仍然能够提供服务。负载均衡能够通过健康检测(Health Check)发现坏掉的服务器没有响应了,就可以自动把所有的流量切换到第 2 台服务器上,这个操作就叫作故障转移(Failover),系统仍然是可用的。
单点故障问题:在这个场景下,任何一台服务器出错了,整个系统就没法用了。
6、关于DMP:数据管理平台(原文)
DMP 系统的全称叫作数据管理平台(Data Management Platform),目前广泛应用在互联网的广告定向(Ad Targeting)、个性化推荐(Recommendation)这些领域。
通常来说,DMP 系统会通过处理海量的互联网访问数据以及机器学习算法,给一个用户标注上各种各样的标签。然后,在我们做个性化推荐和广告投放的时候,再利用这些这些标签,去做实际的广告排序、推荐等工作。无论是 Google 的搜索广告、淘宝里千人千面的商品信息,还是抖音里面的信息流推荐,背后都会有一个 DMP 系统。
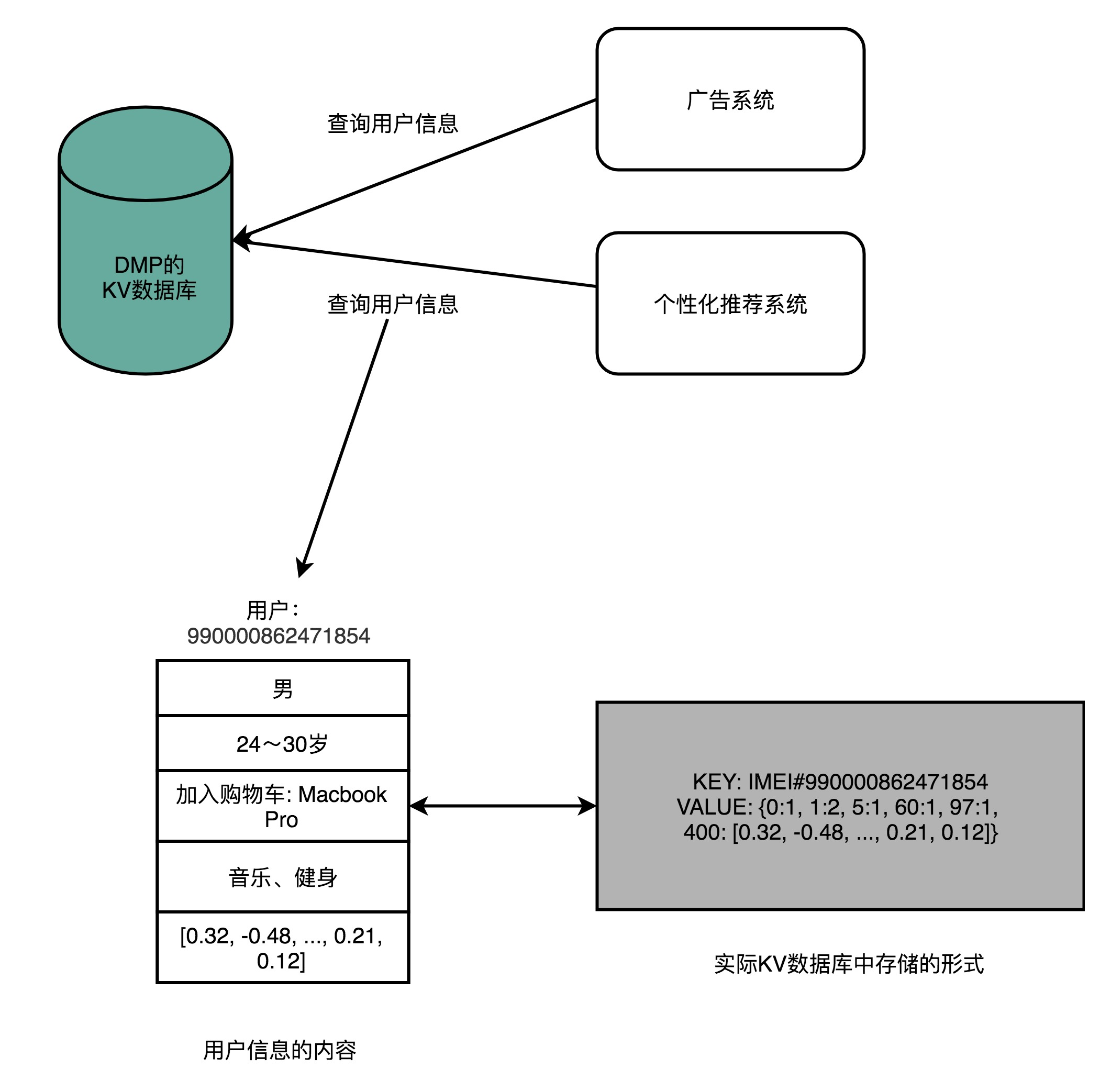
对于外部使用 DMP 的系统或者用户来说,可以简单地把 DMP 看成是一个键 - 值对(Key-Value)数据库。广告系统或者推荐系统,可以通过一个客户端输入用户的唯一标识(ID),然后拿到这个用户的各种信息。这些信息中,有些是用户的人口属性信息(Demographic),比如性别、年龄;有些是非常具体的行为(Behavior),比如用户最近看过的商品是什么,用户的手机型号是什么;有一些是我们通过算法系统计算出来的兴趣(Interests),比如用户喜欢健身、听音乐;还有一些则是完全通过机器学习算法得出的用户向量,给后面的推荐算法或者广告算法作为数据输入。