作者|Mahbubul Alam
编译|VK
来源|Towards Data Science

单类支持向量机简介
作为机器学习方面的专家或新手,你可能听说过支持向量机(SVM)——一种经常被引用和用于分类问题的有监督的机器学习算法。
支持向量机使用多维空间中的超平面来分离一类观测值和另一类观测值。当然,支持向量机被用来解决多类分类问题。
然而,支持向量机也越来越多地应用于一类问题,即所有的数据都属于一个类。在这种情况下,算法被训练成学习什么是“正常的”,这样当一个新的数据被显示时,算法可以识别它是否应该属于正常的。如果没有,新数据将被标记为异常或异常。要了解更多关于单类支持向量机的信息,请查看Roemer Vlasveld的这篇长篇文章:http://rvlasveld.github.io/blog/2013/07/12/introduction-to-one-class-support-vector-machines/
最后要提到的是,如果你熟悉sklearn库,你会注意到有一种算法专门为所谓的“新颖性检测”而设计。它的工作方式与我刚才在使用单类支持向量机的异常检测中描述的方法类似。在我看来,只是上下文决定了是否将其称为新颖性检测或异常值检测或诸如此类的名称。
下面是Python编程语言中单类支持向量机的简单演示。请注意,我交替使用离群值和异常值。
步骤1:导入库
对于这个演示,我们需要三个核心库-用于数据争拗的python和numpy,用于模型构建sklearn和可视化matlotlib。
# 导入库
import pandas as pd
from sklearn.svm import OneClassSVM
import matplotlib.pyplot as plt
from numpy import where
步骤2:准备数据
我使用的是来自在线资源的著名的Iris数据集,因此你可以练习使用,而不必担心如何从何处获取数据。
# 导入数据
data = pd.read_csv("https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv")
# 输入数据
df = data[["sepal_length", "sepal_width"]]
步骤3:模型
与其他分类算法中的超参数调整不同,单类支持向量机使用nu作为超参数,用来定义哪些部分的数据应该被分类为异常值。nu=0.03表示算法将3%的数据指定为异常值。
# 模型参数
model = OneClassSVM(kernel = 'rbf', gamma = 0.001, nu = 0.03).fit(df)
步骤4:预测
预测的数据集将有1或-1值,其中-1值是算法检测到的异常值。
# 预测
y_pred = model.predict(df)
y_pred

步骤5:过滤异常
# 过滤异常值索引
outlier_index = where(y_pred == -1)
# 过滤异常值
outlier_values = df.iloc[outlier_index]
outlier_values

步骤6:可视化异常
# 可视化输出
plt.scatter(data["sepal_length"], df["sepal_width"])
plt.scatter(outlier_values["sepal_length"], outlier_values["sepal_width"], c = "r")
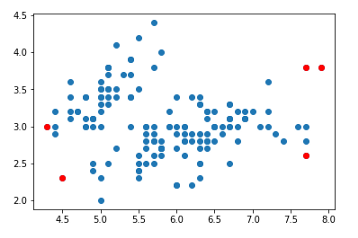
红色的数据点是离群值
总结
在本文中,我想对一类支持向量机(One-classsvm)做一个简单的介绍,这是一种用于欺诈/异常/异常检测的机器学习算法。
我展示了一些构建直觉的简单步骤,但是当然,一个真实的实现需要更多的实验来找出在特定的环境和行业中什么是有效的,什么是不起作用的。
原文链接:https://towardsdatascience.com/support-vector-machine-svm-for-anomaly-detection-73a8d676c331
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/