9章 优化方法和归一化
“Nearly all of deep learning is powered by one very important algorithm: Stochastic Gradient Descent (SGD)” – Goodfellow et al.[1]
我们之前讨论了评价函数,它根据权重W和偏置b参数,根据输入返回数据点 的预测输出。我们也讨论了两种常见的损失函数,它能度量一个给定的分类器在分类数据时有多好或多坏。
给定这些模块,我们转到机器学习、神经网络、深度学习最重要的方面——优化(optimization)。优化算法是强大的神经网络和从数据中学习模式的引擎。纵观讨论,获得高精确度的分类器依赖于找到一组正确的权重W和偏置b。
但是我们如何找到权重W和偏置b来获得高精确度分类器呢?一种方式是随机初始化它们,然后评估,再次重复这些步骤,直到在某个点上我们获得了一组参数获得较好的分类,这种方式也可以,但是考虑到现代深度学习网络的参数数目可能有数百万,这种方式将花费很久的时间才能获得一组合理参数。
代替完全随机,我们需要一种优化算法允许我们迭代的获得权重W和偏置b。本章,我们讨论用于训练神经网络和深度学习模型最常见的算法——梯度下降(gradient descent)。梯度下降有很多变种,但都具有共同思想:反复评估参数、计算损失、在降低损失的方向上移动一小步。
1 梯度下降
梯度下降有两个主要的类型:
(1) 标准的“vanilla”实现(批梯度下降);
(2) 更经常使用的、优化的“随机”(stochastic)版本(SGD)。
本节我们首先回顾基本梯度实现作为基础理解,然后转到随机梯度版本理解。我们还将回顾几种附加功能,即动量(momentum)和Nesterov加速。
1.1 损失景观和优化曲面
梯度下降方法是一个工作在损失景观(或称为优化曲面)上的迭代优化算法。经典梯度下降可视化例子是沿着x轴权重变化,y轴对应权重的损失曲线,见图1左侧所示。
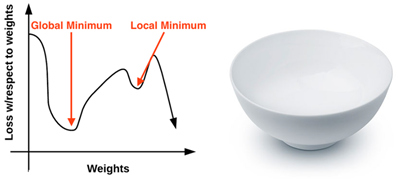
图1 左:二维可视化例子;右:多维的可视化例子
由图1左图可以看到,基于参数值,损失取不同的峰值和低谷。每个峰值是一个局部最大值表示非常大的损失区域,类似的低谷表示具有比较小的损失区域。具有最小值的局部最小值为全局最小值。理想下,我们希望找到全局最小,确保我们的参数可以取到最理想的值。
那么,既然我们想达到全局最小,为什么不一下子就到达这个地点呢?问题是这个损失景观对我们来说是不可见的,我们实际上不知道它是什么样子的。如果我们有一个优化算法,我们可以从一个地方开始,但是我们不知道损失景观是什么样子的,我们希望到达损失最小点而不是到达一个局部最大值的地方。
作者个人非常不喜欢这种可视化损失景观的方式,因为它太简单了而且它使得读者认为梯度下降(极其变种)最终就是找到局部最小或全局最小。作者会在后续章节中进行讨论。作者认为更好地描述这个问题的可视化例子是如图1右侧所示的碗的例子,碗的表面就是损失景观,即损失函数曲线。而损失景观和实际碗的差别是:实际的碗是三维的,而损失景观可能存在于很多维度,可能十维、百维、甚至上千维。
沿着这个碗表面的一个位置对应一个给定参数W和b的特定的损失值。我们的目标就是尝试不同的W和b,评估损失,之后向着更优值(理想上具有最低损失)的方向移动一小步。
1.2 梯度下降中的“梯度”

图2 梯度下降示例
为了直观上理解梯度下降,如图2所示,我们有一个机器人,现在将他随机放置在损失景观的一个位置上,所有的机器人要做的就是找到一条到达损失最低的路线到达最低损失处。这个机器人只能依靠W和b计算一个损失值L,但是它计算出的仅仅是在损失景观上的相对位置,它不知道往哪个方向移动,做法就是计算梯度下降,即跟随梯度的斜率方向,使用下述公式计算所有维度下的梯度:
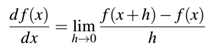
如果时多维,则梯度将是一个偏导数的向量。这里的问题就是它是一个近似计算,而且速度比较慢。实际上,可以使用分析梯度计算,分析梯度精确且快速,但是对于高纬计算很难实现。
我们这里对梯度下降主要需要记住的就是:尝试通过一个朝着最小损失的方向迈出一步的迭代的过程,优化我们的参数以获得低损失和高分类精度。
1.3 当做凸优化问题
如图1右侧所示的损失景观的例子,使我们得出一个现代神经网络重要的结论——将损失景观当做一个凸优化问题对待,即使它不是。如果函数F是凸的,那么所有的局部最小值也是全局最小值。
但是问题是,在应用神经网络和深度学习的几乎所有问题都不是整洁的凸函数。相反,在这个损失景观碗里,我们会发现像螺旋状的山峰,山谷,这更像是峡谷、陡峭的悬崖,甚至是亏损急剧下降,但又急剧上升的槽。
考虑到数据集的非凸特性,为什么还要使用梯度下降呢?原因是梯度下降工作确实足够好。当我们训练一个深度学习网络时,我们可以对找到一个局部/全局最低要求设定很高的期望,但是这种期望很少与现实相符。相反,我们最终发现了一个低损失区域——这个区域可能甚至不是局部最低,但实际上,这已经足够了。
1.4 偏置技巧(bias trick)
在应用梯度下降之前,我们讨论一个偏置技巧问题,即这是一种将权重矩阵W和偏置向量b结合到单个参数的方法。我们之前定义的评分函数为:
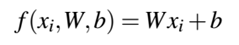
在解释和执行方面,保持两个独立参数很讨厌。这里为了将W和b组合到一起,将输入X增加一个值为1的额外维度(列)。我们可以在每一个 的开始或结束位置插入该额外维度,这都没有影响。这样,我们可以用单一矩阵相乘表示评分函数:
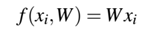
这样,我们就可以忽略偏置b,使得它插入到权值矩阵W中。
以我们之前的Animals数据集为例,工作在32*32*3的图像共3072像素。每个 可表示为[3072*1]的向量。添加一个维度变为[3073*1]向量,类似的,添加了偏置b的权值矩阵W将是[3*3073]而不是[3*3072]了。以这种方式,我们将偏置b作为在权值矩阵W中的一个学习参数而不是一个单独的变量了。以图3为例:

图3 左:正常分开表示参数 右:组合参数表示
采用这种偏置技巧,我们仅需要学习单个的权重矩阵参数即可。在将来的本书介绍中,在谈到权重W的I维度时,都假定偏置b是隐含在偏置矩阵中了。
1.5 梯度下降的伪随机码
下面是标准的、批处理梯度下降算法的类python伪随机代码:

这个伪随机代码是所有梯度下降的变种算法所依据的。第一行中的循环持续优化,知道退出条件满足,通常是下面三种的一种:
(1) 特定的批次数目(epoch)满足。(意味着我们的学习算法“看到”每一个训练点N次)
(2) 我们的损失足够低或训练精确度足够高;
(3) 损失在M此epoch后不再提高了。
第二行中调用名为evaluate_gradient()的函数,该函数需要三个参数:
(1) loss:一个在在当前参数W和输入数据上计算损失的函数;
(2) data:训练数据,这里的每个训练样例都表示一副图像(或特征向量);
(3) W:我们要优化的实际的权重矩阵。我们的目标是应用梯度下降找到一个最小化损失的W。
这个evaluate_gradient()函数返回一个K维的向量,这里K是图像/特征向量的维度。这个Wgradient是实际的梯度。
我们在第三行应用梯度下降。将Wgtradient乘以一个参数alpha(α),这是学习率,它控制每一步的大小。
实际上,你将花费大量时间来找到一个最佳的α值,这是目前为止你的模型中最终要的参数值。如果α太大,则将可能会错过最低值,而在损失景观上来回震荡,而不能降低到“碗”的底部;而如果α太小,则会花费太久的迭代步骤到达底部。因此,找到最优的α值,将会花费大量的时间。
1.6 用python应用梯度下降
下面我们使用python来简单应用梯度下降,打开文件gradient_descent.py,键入代码,运行即可。这里见
https://github.com/shengqishi8787/Starter_Bundle.git 的chapter8目录,然后python gradient_descent.py即可显示这里的示例结果。
这里我们简单使用激活函数>0.5时为1,<0.5时为0,其它激活函数将在Startle Bundle的第10章和Practitioner Bundle的第7章讨论。
其中参数,我们设定了周期epoch和学习率α,其中学习率通常设定为0.1、0.01、0.0001,这个参数是一个超参数需要在模型中调整。
你也可以看到0和1的权重初始化,但正如我们将在本书后面发现的,良好的初始化对于在合理的时间内训练神经网络是至关重要的,所以随机的初始化和简单的启发式在绝大多数情况下都是成功的。
1.7 简单梯度下降运行结果分析
当第一次运行时,可看到结果分类1为100%,而分类0为0%,这是因为在每一次周期epoch内,都只更新一次权重。对于简单的梯度下降,我们可以通过多次epoch或设置不同的学习率来更好地训练网络模型。但是,就像在下一节介绍的,一种梯度下降的变种形式随机梯度下降(Stochastic Gradient Descent)在训练数据的每一批次都更新一次权重,暗含在每一周期epoch内都更新多次权重。这种方法可以获得更快、更稳定的收敛。
2 随机梯度下降(SGD)
前一节介绍了简单的基础梯度下降方法,但是它在大数据集上计算缓慢。取而代之的是,应用随机梯度下降(Stochastic Gradient Descent (SGD)),这是对标准梯度下降做的简单修改,即在训练数据集的小批次(batch)上而不是在整个数据集上计算权重且更新权重W。
当开始训练深度神经网络时,SGD是可论证的最重要的算法。
2.1 Mini-batch SGD
在标准梯度下降算法中,在大数据集上的运行很慢。我们的改进是批量更新。我们由标准梯度算法的改进得来SGD的伪代码:

在标准梯度下降和SGD之间的唯一差别是添加了next_training_batch()函数,代替在整个训练集上计算梯度,我们采样batch大小来计算。在SGD计算中,我们加入一个超参数:batch size。通常,我们的batch size大于1,一般是32、64、128或256。一般来说,这个参数不是我们太担心的超参数。
2.2 实现mini-batch SGD
该实现文件见git中的sgd.py。
3 SGD扩展
在实际中常见到两种SGD的扩展,一种是动量(momentum),它用于加速SGD,它通过关注梯度指向相同方向的维度来加速;另一种是Nesterov动量,它是第一种标准动量的改进。
3.1 Momentum
想象一下你小时候从山上跑下山的情况,在跑下山过程中,你越跑越快,即动量越来越大,这将使你更快的到达山下。应用于SGD的动量具有相同作用,我们的目标是在标准权重基础上加上一个动量项来更新,即允许模型在更少的epoch上获得更低的损失(即更高的准确率。)因此,动量项应该增加梯度指向同一方向的维度的更新强度,然后减少梯度转换方向的维度的更新强度。
我们之前的更新权重仅仅是通过学习率缩放梯度:
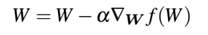
我们现在引入一个动量项V,由γ缩放:

一种常见的动量项γ取0.9,另一种方法是γ设置为0.5,随时间增加到0.9,对于动量项γ设置成小于0.5的值是很少见的。
3.2 Nesterov momentum
再次考虑往山下跑的情况,你建立动量一路快速跑下山,但是如果山下正好是一堵墙,这时候你应当避免全速冲撞。这种思想也可以应用到SGD中,如果动量太大,我们可能会错过最低点,因此我们需要一种聪明的动量方式,它能够知道什么时候加速,什么时候减速,这就是Nesterov momentum。
Nesterov momentum可以被概念化为对动量的修正更新,这使我们在更新后大致了解我们的参数将在哪里,回顾Hinton的Overview of mini-batch gradient descent slides,见图4,我们更好地可视化Nesterov momentum。
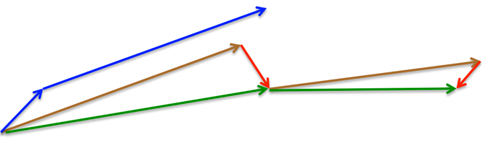
图4 Nesterov momentum概念示例
基于标准动量,我们计算梯度(小的蓝向量)且在梯度方向上(大的蓝向量)进行一次跳跃。在Nesterov加速下,我们在之前的梯度方向上(褐色向量)做出一次大的跳跃,测量梯度,然后做出纠正(红色向量),绿色向量是最终纠正后由Nesterov加速后更新的向量。
3.3 作者建议
动量是增加模型收敛的重要参数,但是与学习率和正则化惩罚(regularization penalty)相比,我们不需要太关注动量的选择。作者准则是无论什么时候使用SGD时,都加上动量项,你可以设置它的值或随着时间增加到0.9。
对于Nesterov加速,作者倾向于在小数据集上使用,不建议在大数据集如ImageNet上使用。在ImageNet的数据集上的所有主要的发表物(如AlexNet, VGGNet, ResNet, Inception等)都使用了具有动量的SGD,但没有一个使用Nesterov加速。
注意:这只是作者的观点。
4 正则化(regularization)
“Many strategies used in machine learning are explicitly designed to reduce the test error, possibly at the expense of increased training error. These strategies are collectively known as regularization.” – Goodfellow et al.[1]
机器学习中使用的许多策略都被明确地设计来减少测试误差,可能以牺牲增加的训练误差为代价,这些策略被统称为正则化。
虽然我们的损失函数允许我们确定我们的一组参数在给定的分类任务中有多好(或差),但损失函数本身并没有考虑权重矩阵看起来如何。看起来意味着什么?注意我们工作在实数值空间,在数据集上有无限的参数集合能够获得合理的分类精确度。那么,我们如何选择一组参数来保证我们的模型泛化足够好呢?或者,至少减轻过拟合的影响,答案就是正则化。仅次于学习率,正则化是要学习的模型中最终要的调整参数。
存在各种类型的正则化技术,例如L1正则、L2正则和弹性网络(Elastic Net),用于更新损失函数本身,增加额外参数以约束模型的容量。
还有几种明确的加入到网络架构中的正则化类型:dropout(丢弃)是这种正则化的典型例子。我们也有明确的应用到训练过程的正则化形式,包括数据增加(data augmentation)和早停(early stopping)。
在本节我们主要关注通过修改损失和更新函数获得的参数化正则方法。在Startle Bundle的第11章,我们学习dropout且在第17章更深入的讨论过拟合(overfitting),以及如何使用早停。在Practitionner Bundle中,你将看到数据增加作为正则化的例子。
4.1 正则化是什么?我们为什么需要它?
正则化能够帮助我们控制模型容量,确保模型在还没有训练过的数据点上做出更正确的预测,即具有更好地泛化能力。如果我们不实施正则化,则分类器将很容易变得很复杂从而在训练数据上过拟合,那么模型将失去在测试数据上泛化的能力。
但是,太过的正则化也是一件坏事情,这样将有欠拟合(underfitting)的风险,欠拟合使得模型在训练数据集上执行很差,从而不能模拟输入数据和输出类别标签的对应关系。如图5所示的示意图:
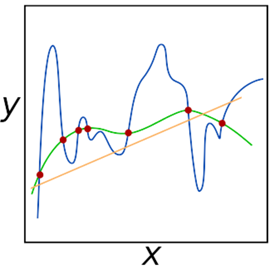
图5 拟合能力示意图
橘色线为欠拟合,不能获得数据之间的关系;蓝色线为过拟合,模型中存在太多参数而不平滑。正则化的目标就是很好地获得这些拟合训练数据的“绿色”曲线,而避免过拟合训练数据(“蓝色线”)或不能模拟潜在的数据关系(“橘色线”)。我们将在第17章讨论怎样监视训练和发现过拟合与欠拟合。但是在这时,只需要知道正则化是机器学习的至关重要的方面、我们将使用正则化来控制模型泛化性能即可。下一节中将讨论如何理解正则化和它是怎样影响损失函数和更新权重的。
4.2 更新损失和更新权重包含正则化
让我们以交叉熵损失函数开始:
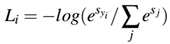
整个训练集上的损失可表示为:

现在,我们说我们获得了一个权重矩阵W使得训练集中的每一个数据点都分类正确,也就意味着对于所有的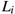 ,我们的损失
,我们的损失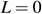 。
。
了不起!我们获得了100%的正确率,但是这个权重是唯一的吗?或者换句话说,存在能够提高模型的泛化和减少过拟合的能力的权重W更好的选择吗?
如果有这样的一个W,我们如何知道?我们如何将这种惩罚加入到我们的损失函数中?答案就是定义一个正则化惩罚(regularization penalty),这是一个定义在权重矩阵上的函数。正则化惩罚常写作R(W)的函数形式,下式是最常见的正则化惩罚:L2正则化(又称为权重衰减weight delay):
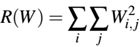
依据python代码,我们可以写作下述形式:

这里做的就是在整个矩阵上循环求平方和。在L2正则化惩罚中不鼓励大的权重值,倾向于小的权重值。通过惩罚大的权重值,我们可以提高泛化能力,即降低过拟合。这样想象一下,权重值越大,它对预测结果影响越大。具有很大的权重值几乎独自就可决定分类器的预测结果,这确定是产生了过拟合。
为了减少对分类器结果的各种影响,我们采用正则化方法,从而寻求考虑到所有维度而不是少数大值的W值。在实际中,可能会发现正则化轻微的影响了训练精确度,但是它会增加测试精确度。
此时,我们的损失函数有了一个基本形式,仅需要加上正则化项:
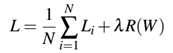
第一项为在整个训练集上的平均损失;
第二项就是我们的正则化惩罚项,λ变量为超参数用于控制正则化的大小或强度。在实际中,学习率α和正则化项λ都是需要花费大量时间进行调整的超参数。
包含L2正则化项的扩展交叉熵形式为:
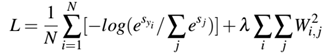
我们也可扩展多类别SVM损失形式为:
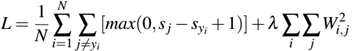
现在,我们看下标准的权重更新规则:
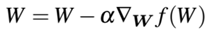
这种方法基于梯度乘以学习率α来更新权重。考虑正则化项,权重更新规则变为:
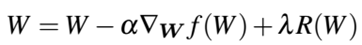
4.3 正则化技术的类型
一般来说,你可以见到三种直接应用到损失函数中的常见正则化类型。第一种就是L2正则化(也叫权重衰减):

第二种是L1正则化,它考虑权重绝对值:
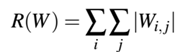
第三种弹性网络(elastic net)正则化,同时考虑L1和L2正则化:
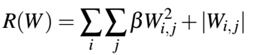
还有其他类型的正则化方法,如直接修改网络的体系结构以及网络的实际训练方式,我们将在后续章节中讨论三种方法。
在你应该使用哪种正则化方法(或完全不包括任何正则化方法)方面,你应该将此选择视为一个超参数,你需要对其进行优化并进行实验,以确定是否应该应用正则化方法,如果应用,则应使用哪种正则化方法,λ的正确值是多少?
4.4 正则化应用到图像分类
为了实践正则化,我们用python代码应用到Animals数据集上。
代码为regularization.py,见git仓库,在导入代码中,新导入from sklearn.linear_model import SGDClassifier,其中SGDClassifier封装了本章中所有概念,包括损失函数、epoch数目、学习率、正则化项,因此它能让我们完美的演示这些概念。
其中,在测试代码中,我将elasticnet也加入到测试中,现实中,这个例子太小而不能很好的表现正则化对于性能的影响,在后面训练CNNs时就可看到。然而,在此期间,只要我们能够正确调整超参数,就可以简单地认识到正则化可以提高我们的测试精度并减少过拟合。
5 总结:
学习到这里,我们有一个良好、基础的机器学习,但我们还没有研究神经网络或从头开始训练一个定制的神经网络。在下一章中,我们将讨论神经网络、反传播算法以及如何在自定义数据集上训练自己的神经网络。
6 附录
[1] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. http://www.deeplearningbook.org. MIT Press, 2016 (cited on pages 22, 24, 27, 42, 54, 56, 82, 95, 98, 113, 117, 169, 194, 252).