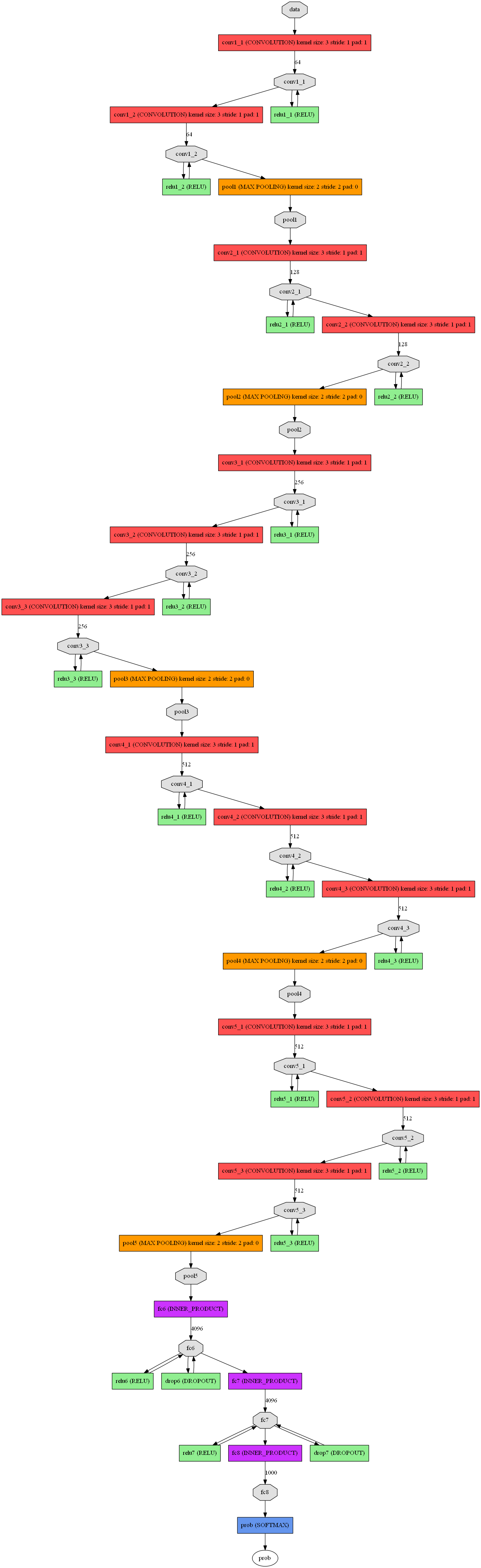
介绍
VGGNet探索了CNN的深度与其性能之间的关系,反复堆叠3*3卷积核(pad=1,stride=1)和2*2最大池化核(pad=0,stride=2),16~19层深的卷积神经网络。
VGGNet常被用来提取图像特征。

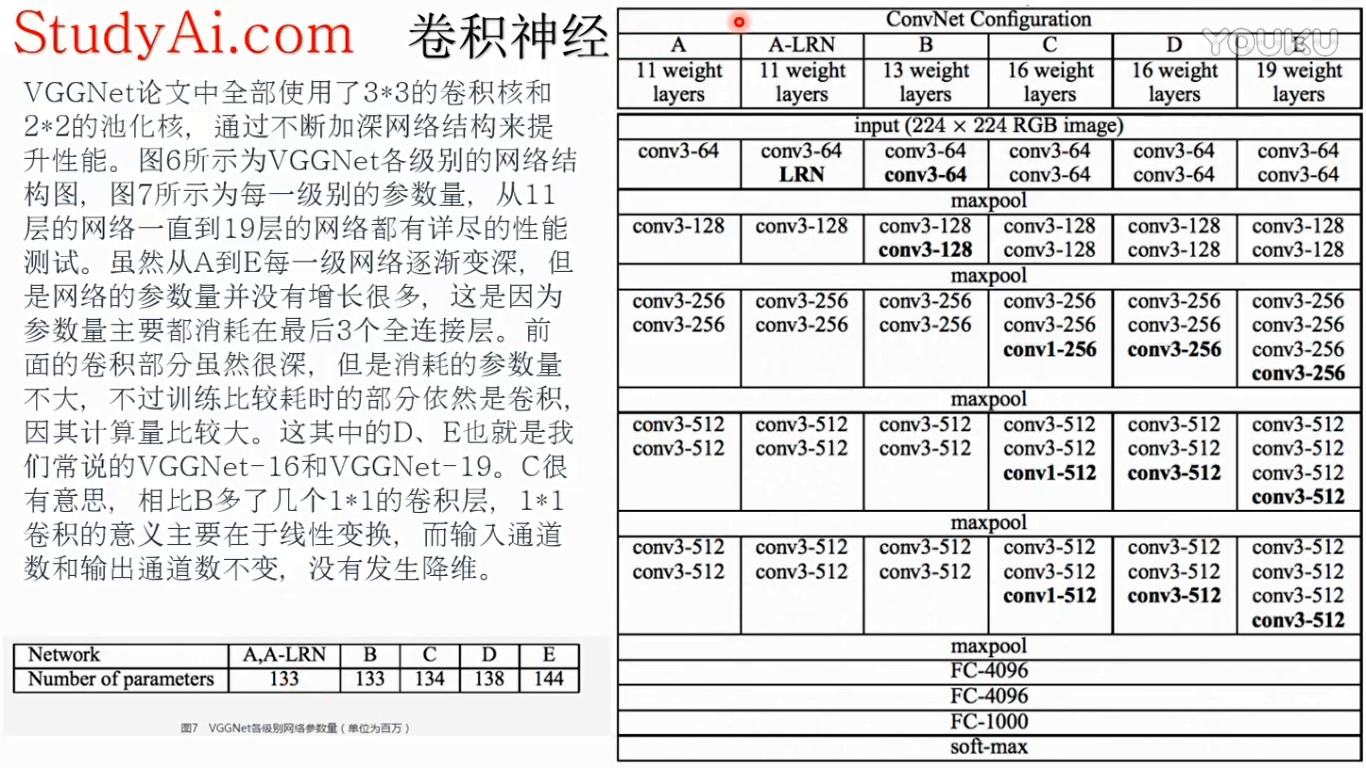
主要是VGG16,19
特征提取器层是不一样的,主要每一行卷积的深度不一样,
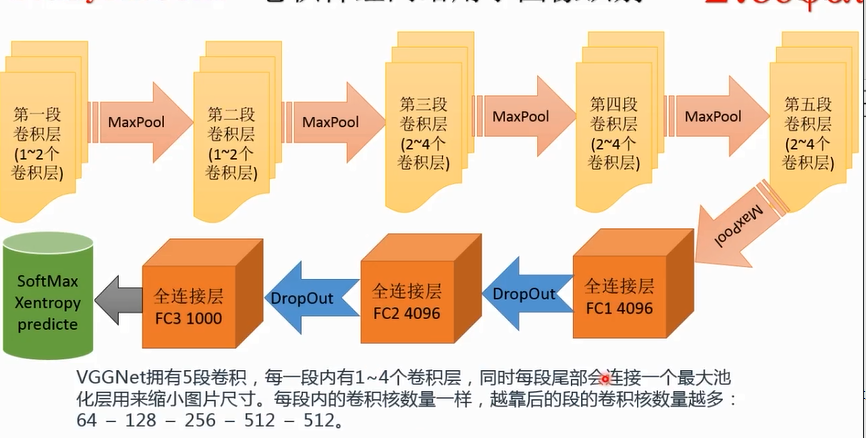
总共划分为五段卷积层
全连接层有4096个神经元
fc3有1000个神经元,线性输出层
每个conv出来之后自带一个relu
drop主要是为了防止分类器的过拟合,如果参数特别多,特征空间就划分的很凌乱,容易过拟合。加了个dropout加入了正则化约束,表现得像一层一样,我这个通道以一定的概率保持通状态,一定的概率保持闭状态。

参数更少;卷积层越多,非线性变换就可以越多,学习能力越强

先训练a
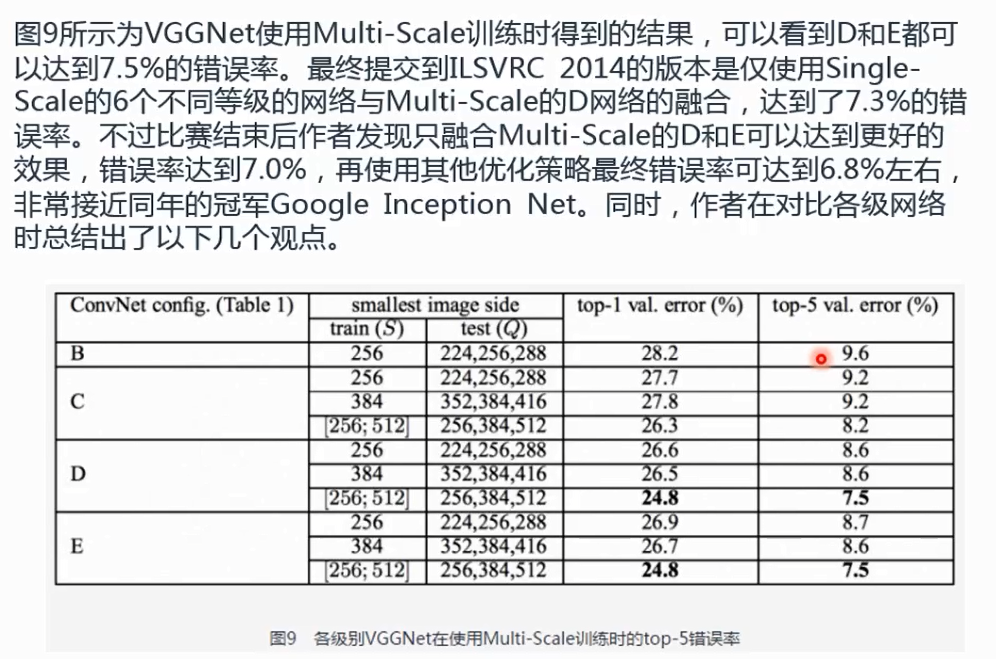
scal是尺度,图像分析里面有个叫多尺度分析的的方法,例如小波变换。
multi_scale多尺度变换,归一化到一个尺寸q
多尺度预测的过程,给了原始图像之后,训练样本的尺寸有可能是非常小的,也有可能是非常大的,怎么办呢,一方面是再训练的过程中,对不通图像做不同尺度的调整。这样模型就能识别不同尺度的图像,测试的时候也做不同尺度的调整
数据增强的意思是:比如说输入的图像时32*32,可以缩放到16*16/128*128/64*64.。。这样添加多个不同尺度的版本数据,然后来训练这个网络
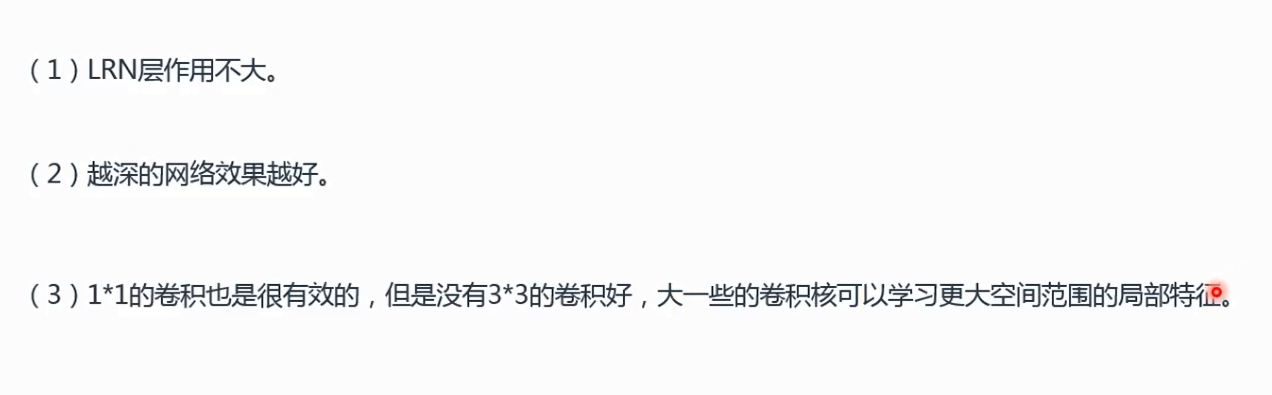
补充VGG16
conv: kernel=3x3 , pad=1 , stride=1
maxpool: kernel=2x2 , pad=0 , stride=2