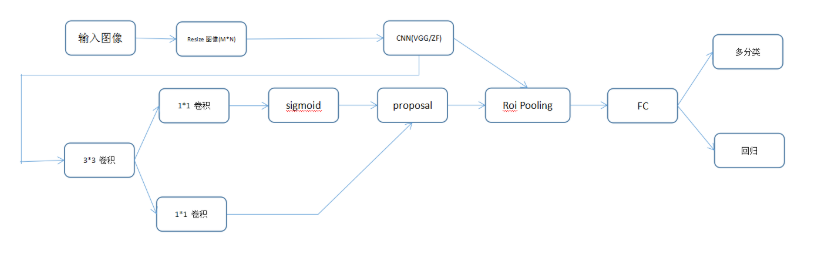

训练:
特征图是51x39x256,对该图像的每点考虑9个窗口:三种候选面积(128,256,512) x 三种尺度(1:1,1:2,2:1)。这些候选窗口称为anchors。如下图:
如果图片尺寸w*h,特征图的尺寸是w/r ×h/r(由pool5层得到的尺寸,计算后得到这个r)。r是下采样率(subsampling ratio)。如果在卷积图空间位置定义anchor,则最终的图片会是由r像素划分的anchor集。在VGG中,r=16。也就是在特征图中得到的anchor尺寸乘以这个r就是在原图中的尺寸了。

然后计算每个点(共21x39个点,每个点256个通道,即256维)的9个anchor值(在原图上的),给每个anchor分配一个二进制标签(前景,背景):
- 跟真值框的交并比最高的,标为1;
- 跟真值框的交并比大于0.7的,标为1;
然后随机采样anchors来生成batch_size=256的mini batch,尽可能保持foreground 与 background的比例平衡。RPN 对 mini-batch 内的所有 anchors 采用 binary cross entropy 来计算分类 loss。然后,只对 mini-batch 内标记为 foreground 的 anchros 计算回归 loss。为了计算回归的目标targets,根据 foreground anchor 和其最接近的 groundtruth object,计算将 anchor 变换到 object groundtruth 的偏移值correct
对于分类层,输出每个anchor属于前景和背景的概率值;
对于回归层,也可以叫边界框调整层,每个anchor输出4个预测值:
,根据这个偏移量来用anchor得到最终的proposal。
因为anchors是有重叠的overlap,同一个目标(这里不管类别,指所有类别)也有多个互相重叠的anchors。
为了解决重叠 proposals 问题,采用 NMS 算法处理,丢弃与一个score 更高的 proposal 间 IoU 大于预设阈值的 proposals。如果 IoU 值过大,可能会导致 objects 出现很多 proposals. IoU 典型值为 0.6。
NMS 处理后,根据 sore 对 topN 个 proposals 排序. 在 Faster R-CNN 论文中 N=2000,其值也可以小一点,如 50,仍然能的高好的结果.
最后通过NMS,RPN产生的输出是一系列的ROI_data,通过与ROI的相对映射关系,将conv5_3的特征存入到ROI_data中,供后面的分类网使用。
补充:
RPN 可以独立使用,不用 2-stage 模型.
当处理的问题是,单个 object 类时,objectness 概率即可作为最终的类别概率. 此时,“foreground” = “single class”,“background”=“not single class”.
可以应用于人脸检测(face detection),文字检测(text detection),等.
仅单独采用 RPN 的优点在于,训练和测试速度较快. 由于 RPN 是仅有卷积层的简单网络,其预测效率比采用分类 base 网络的效率高.
所以,综合来讲,整个RPN的作用就是替代了以前的selective-search方法,因为网络内的运算都是可GPU加速的,所以一下子提升了ROI生成的速度。可以将RPN理解为一个预测前景背景,并将前景框定的一个网络,并进行单独的训练,实际上论文里面就有一个分阶段训练的训练策略,实际上就是这个原因。