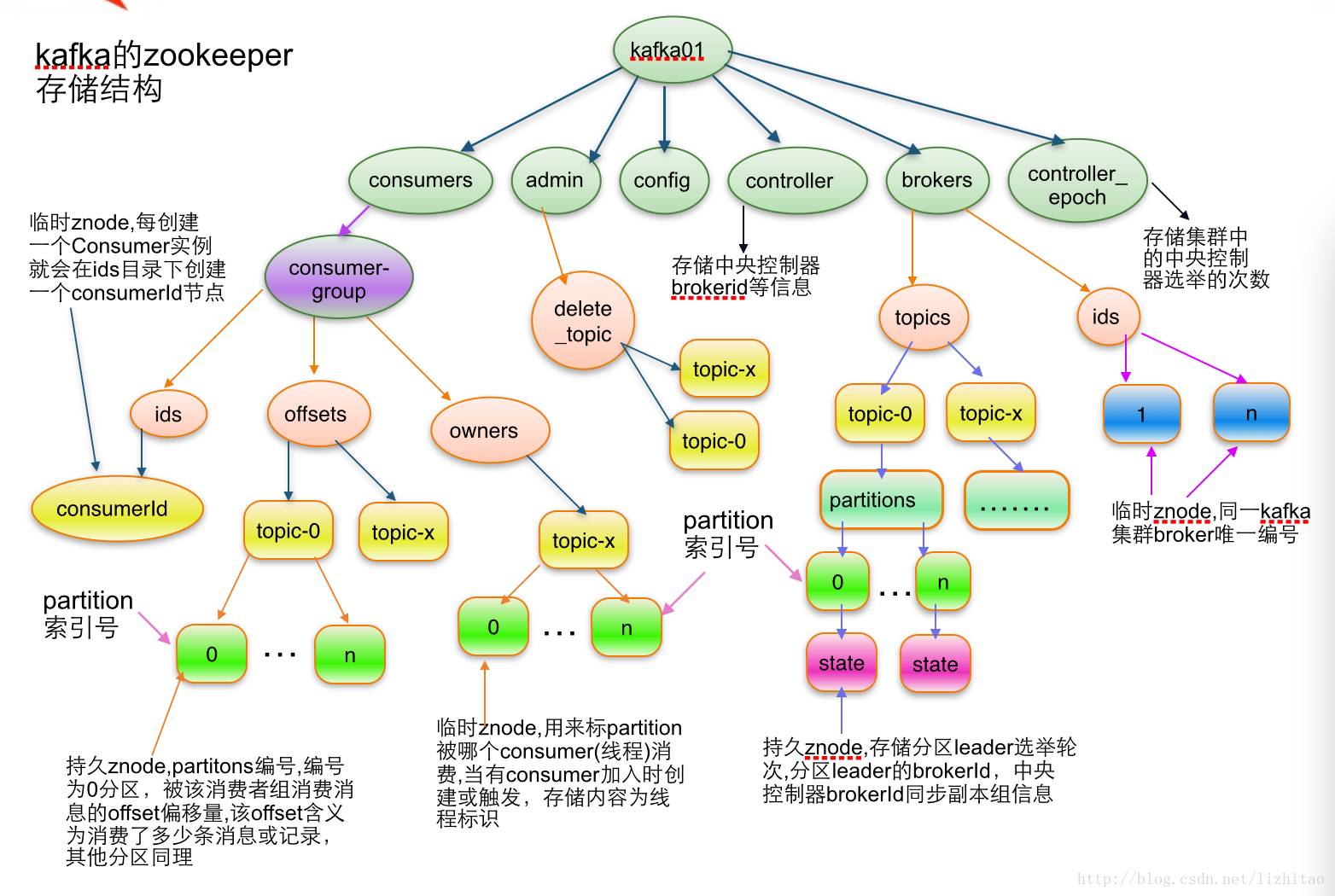
Kafka与Zookeeper
Zookeeper存储了什么
kafka架构中角色:
1.producer:
消息生产者,发布消息到 kafka 集群的终端或服务。
2.broker:
kafka 集群中包含的服务器。
3.topic:
每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。
4.partition:
partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
5.consumer:
从 kafka 集群中消费消息的终端或服务。
6.Consumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
7.replica:
partition 的副本,保障 partition 的高可用。
8.leader:
replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
9.follower:
replica 中的一个角色,从 leader 中复制数据。
10.controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
12.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。
zookeeper与kafka之间的联系
1.每个broker在启动之后会在zookeeper中注册也给临时的broker registry,包括了broker的IP地址和端口好,所存储的topic和partitions信息。
2.每个consumer启动之后会在zookeeper上注册一个临时的consumer registry;包含了consumer所属的consumer group以及订阅的topics
3.每个consumer group关联一个临时的owner registry和一个持久化的offset registry,对于被订阅的每个partition包含一个owner registry,内容为订阅了这个partition的consumer ID;同时也包含了一个offset registry,内容是上一次订阅的offset,即消费的进度。
kafka中使用到zookeeper的步骤
1、producer向zookeeper询问要存储partition的leader
2、新增topic:controller会在zookeeper的broker/topics节点下注册watch,用来检测topic的变化,如果一个新的topic创建,那么controller就会检测到该topic下的partiton的Leader和replication的变化,并将该更改存储到zookeeper对应的节点下。
3、Leader选举:controller从zookeeper下的broker/ids读取所有可用的broker列表,并且对于每个set_p中的partition,都会在其所有的replication中任选一个broker作为Leader,并将该选举信息存到zookeeper中。
4、删除topic:controller会在zookeeper的broker/topics节点下注册watch,用来检测topic的变化,如果一个新的topic被删除,那么controller就会检测到该topic下的partiton的Leader和replication的变化,并将该更改存储到zookeeper对应的节点下。如果被删除的是leader则需要进行重新选举。