原文: https://www.cnblogs.com/motadou/p/12667166.html
_________________________________________
云风版协程库源代码分析
我们知道一个程序可以包含多个进程,每个进程中可以创建多个线程,在线程中又可以创建成千上万甚至更多个协程。进程和线程的创建以及调度需要在内核态和用户态之间切换;而协程的创建和调度都在用户态,不需要和内核态进行交互。所以这就注定创建和维持协程运行所牺牲的性能,要远小于进程和线程。另外,协程都是以一组的形态存在于一个特定的线程内,那么对于数据的共享,不必使用互斥锁或者条件变量,来保证互斥和同步,应用程序性能上也有了很大的提升。这就是我们使用协程的原因。
协程适用于IO密集型,而不适用于计算密集型的程序。对于IO密集型程序,无论是读取socket还是硬盘,这些操作基本上都是阻塞式调用,当协程遇到阻塞时,当前协程显式或者隐式主动放弃控制权,保存当前协程的硬件上下文和栈,然后调度器切换到其他就绪的协程继续执行,而当阻塞IO完成后,调度器获得通知,恢复原来协程的硬件上下文以及栈,再切换回来运行。而对于计算密集型的程序,当前协程除非显式切换协程或者设置定时器,由定时器主动引起切换,否则通常不会主动放弃控制权,其他协程可能会一直等待调度,得不到运行。
一组协程运行在一个线程内,它们是串行运行的,而非并行,即是运行在一个CPU核上,那么协程就无法利用多核CPU资源。如果我们既想使用协程,又想利用多核CPU,一般我们就采用”多进程+协程“的方式。
目前网上有很多协程的实现例子,本文主要分析云风的协程库,来探究协程的实现原理。源码之前了无秘密,大家也可以直接看协程库的注释版。
第一种:利用ucontext函数族来切换运行时上下文。比如云风的协程库。
第二种:利用汇编语言来切换运行时上下文。比如微信的libco。
第三种:利用C语言语法switch-case来实现切换运行时上下文。比如Protothreads;
第四种:利用C语言的setjmp和longjmp。
云风版协程库简单来说,核心就是使用ucontext函数族不停的切换当前线程的运行时上下文,导致切换到不同的协程函数中去,以达到在同一个线程内切换协程的目的。无论协程怎么切换,不会引起所属线程的切换。
该函数获取当前运行时上下文,将其保存到ucp中。
设置当前运行时上下文为ucp。
该函数的作用是修改一个用getcontext()获取的ucontext_t实例,也就是说ucp是在调用makecontext之前由getcontext初始化过的值。如果从字面上理解,觉得makecontext可以新建一个ucontext_t,但实际它仅做修改,所以它叫updatecontext显然更加合适。makecontext用参数func指针和argc,以及后续的可变参数,来修改ucp。当这个ucp被setcontext或者swapcontext之后,执行流跳转到func指向的新函数中去。
该函数将当前的运行时上下文保存到oucp中,然后切换到ucp所指向的上下文。
这4个函数都用到了ucontext_t结构体,它用来保存运行时上下文,包括运行时各个寄存器的值、运行时栈、信号等等数据。它大致的结构为:
其中:
uc_link :当前上下文运行结束时,系统恢复到uc_link指向的上下文;如果该值为NULL,则线程退出;
uc_stack :当前上下文中使用的栈;
uc_sigmask :当前上下文中的阻塞信号集;
uc_mcontext:保存的上下文的特定机器数据,包括调用线程的特定寄存器等;
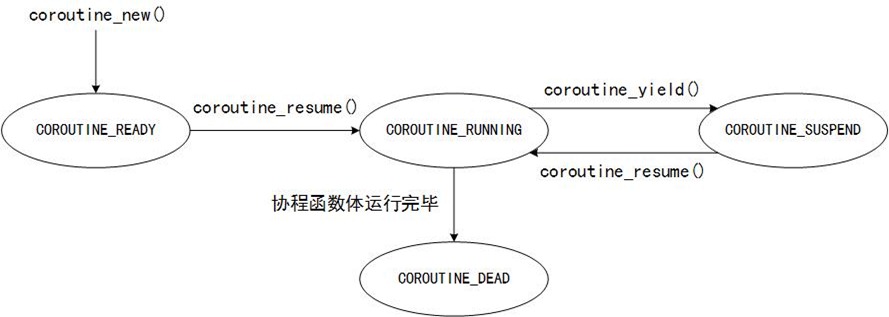 由上述状态图,我们可以知道云风版协程库的使用方法:
由上述状态图,我们可以知道云风版协程库的使用方法:
struct schedule协程调度器
其中ucontext_t main用来保存主协程的上下文,看全部源代码,它在两个地方被保存。
其中char stack[STACK_SIZE]用来做所有子协程的运行时栈,看全部代码,它在一个地方被保存,一个地方被恢复。
struct coroutine协程结构体
其中coroutine_func func是子协程真实运行的函数体,在此函数中完成业务主逻辑。实际上子协程先进入mainfunc这个函数,在这个函数再调用func进入真实函数。参考源代码corontine.c中第166行。
其中ucontext_t ctx是当前子协程的运行时上下文,看全部源代码它在一个地方被保存,在两个地方被恢复。
协程的恢复coroutine_resume
协程的切出coroutine_yield
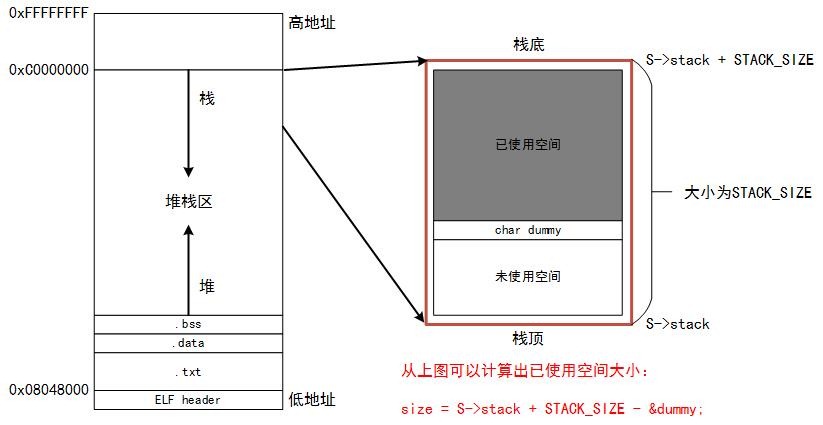
显而易见,在coroutine_yield函数中有个关键步骤就是保存当前运行时栈,它调用_save_stack来完成。接下来我们看下_save_stack的实现原理。要保存下当前运行时栈,我们首先需要知道当前子协程用了多少栈空间。然后根据栈空间来开辟当前子协程中的私有栈缓存,也就是struct coroutine结构体中char * stack数据域。我们知道栈空间是由高地址向下使用的,在makecontext设置栈信息时,我们将最大栈顶设置为S->stack,那么其栈底为S->Stack+ STACK_SIZE。在_save_stack中,我们先在栈中申明一个char类型的dummy,则dummy表示当前已使用栈空间的栈顶为(char *)&dummy。由此我们可以得出已使用栈空间大小,既可以精确的分配空间,而不至于在每个协程结构体中开辟一个STACK_SIZE大小的缓存区,从而节省了空间。
2.https://github.com/zfengzhen/Blog/blob/master/article/ucontext簇函数学习.md
3.http://www.ilovecpp.com/2018/12/19/coroutine/
协程适用于IO密集型,而不适用于计算密集型的程序。对于IO密集型程序,无论是读取socket还是硬盘,这些操作基本上都是阻塞式调用,当协程遇到阻塞时,当前协程显式或者隐式主动放弃控制权,保存当前协程的硬件上下文和栈,然后调度器切换到其他就绪的协程继续执行,而当阻塞IO完成后,调度器获得通知,恢复原来协程的硬件上下文以及栈,再切换回来运行。而对于计算密集型的程序,当前协程除非显式切换协程或者设置定时器,由定时器主动引起切换,否则通常不会主动放弃控制权,其他协程可能会一直等待调度,得不到运行。
一组协程运行在一个线程内,它们是串行运行的,而非并行,即是运行在一个CPU核上,那么协程就无法利用多核CPU资源。如果我们既想使用协程,又想利用多核CPU,一般我们就采用”多进程+协程“的方式。
目前网上有很多协程的实现例子,本文主要分析云风的协程库,来探究协程的实现原理。源码之前了无秘密,大家也可以直接看协程库的注释版。
协程库的实现方式
总体来说,目前有如下几种方式来实现协程库。第一种:利用ucontext函数族来切换运行时上下文。比如云风的协程库。
第二种:利用汇编语言来切换运行时上下文。比如微信的libco。
第三种:利用C语言语法switch-case来实现切换运行时上下文。比如Protothreads;
第四种:利用C语言的setjmp和longjmp。
云风版协程库简单来说,核心就是使用ucontext函数族不停的切换当前线程的运行时上下文,导致切换到不同的协程函数中去,以达到在同一个线程内切换协程的目的。无论协程怎么切换,不会引起所属线程的切换。
ucontext函数族说明
|
0001
0002
0003
0004
0005
0006
0007
0008
0009
|
#include <ucontext.h> int getcontext(ucontext_t *ucp); int setcontext(const ucontext_t *ucp); void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...); int swapcontext(ucontext_t *oucp, ucontext_t *ucp); |
int getcontext(ucontext_t *ucp);
int setcontext(const ucontext_t *ucp);
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
这4个函数都用到了ucontext_t结构体,它用来保存运行时上下文,包括运行时各个寄存器的值、运行时栈、信号等等数据。它大致的结构为:
|
0001
0002
0003
0004
0005
0006
0007
|
typedef struct ucontext { struct ucontext *uc_link; sigset_t uc_sigmask; stack_t uc_stack; mcontext_t uc_mcontext; ...} ucontext_t; |
uc_link :当前上下文运行结束时,系统恢复到uc_link指向的上下文;如果该值为NULL,则线程退出;
uc_stack :当前上下文中使用的栈;
uc_sigmask :当前上下文中的阻塞信号集;
uc_mcontext:保存的上下文的特定机器数据,包括调用线程的特定寄存器等;
云风版协程库的实现原理
首先我们看下该协程协程库中的协程的状态切换图,图中表明了几个重要的函数:由上述状态图,我们可以知道云风版协程库的使用方法:- 第一:用户在主协程中调用coroutine_new来创建一个子协程,新建协程的状态为COROUTINE_READY,表示协程就绪,等待调度。
- 第二:在合适的时机,用户在主协程中显式调用coroutine_resume(),将某个新建协程投入运行。
此时的coroutine_resume将协程状态由COROUTINE_READY转为COROUTINE_RUNNING,函数会相继调用getcontext、makecontext、swapcontext,分别完成获取当前上下文、制作新上下文、从主协程切换到子协程这三个动作。调用swapcontext之后,当前线程的控制权交给子协程。
任一时刻,在一个线程内只有一个协程在运行,其他协程要么是就绪态,要么是挂起态。 - 第三:在子协程中,用户显式调用coroutine_yeild()放弃控制权。
此时的coroutine_yeild将协程状态由COROUTINE_RUNNING转为COROUTINE_SUSPEND状态,函数会保存当前子协程的上下文和运行时栈,然后调用swapcontext从子协程切换回主协程。调用swapcontext之后,当前线程的控制权又回到主协程。 - 第四:控制权切回主协程之后,如果有新建的子协程,根据“第二”步的描述将其投入运行;
- 第五:控制权切回主协程之后,如果有COROUTINE_SUSPEND状态的协程,主协程根据调度算法再次调用coroutine_resume()将其投入运行。
此时的coroutine_resume将协程状态由COROUTINE_SUSPEND转为COROUTINE_RUNNING,函数会先恢复子协程的运行时栈,然后调用swapcontext从主协程切换到子协程。当前线程的控制权移交给子协程。 - 第六:如果子协程的函数体运行完毕退出,再次切回主协程。恢复主协程的硬件上下文和运行时栈,执行调度子程序,或者在所有子程序都结束的情况下,主协程也退出。
|
0001
0002
0003
0004
0005
0006
0007
0008
0009
0010
0011
0012
0013
0014
0015
0016
0017
0018
0019
0020
0021
0022
0023
0024
0025
0026
0027
0028
0029
0030
0031
0032
0033
0034
0035
0036
0037
0038
0039
0040
0041
0042
0043
0044
0045
0046
0047
0048
0049
|
#include "coroutine.h"#include <stdio.h>struct args { int n;};static void foo(struct schedule * S, void *ud) { struct args * arg = ud; int start = arg->n; int i; for (i = 0; i < 5; i++) { printf("coroutine %d : %d
",coroutine_running(S) , start + i); coroutine_yield(S); // 切出当前协程 }}static void test(struct schedule *S) { struct args arg1 = { 0 }; struct args arg2 = { 100 }; int co1 = coroutine_new(S, foo, &arg1); // 创建协程 int co2 = coroutine_new(S, foo, &arg2); // 创建协程 printf("main start
"); while (coroutine_status(S,co1) && coroutine_status(S,co2)) { coroutine_resume(S, co1); // 恢复协程1的运行 coroutine_resume(S, co2); // 恢复协程2的运行 } printf("main end
");}int main() { struct schedule * S = coroutine_open(); // 创建一个调度器,用来管理所有子协程 test(S); coroutine_close(S); // 关闭调度器 return 0;} |
struct schedule协程调度器
|
0001
0002
0003
0004
0005
0006
0007
0008
0009
0010
0011
0012
0013
0014
|
#define STACK_SIZE (1024*1024) // 默认的协程运行时栈大小struct coroutine;// 调度器结构体struct schedule { char stack[STACK_SIZE]; // 协程运行时栈(被所有协程共享) ucontext_t main; // 主协程的上下文 int nco; // 当前存活的协程数量 int cap; // 调度器中的协程容器的最大容量。后期可以根据需要进行扩容。 int running; // 当前正在运行的协程ID struct coroutine **co; // 调度器中的协程容器}; |
- 第一次是在coroutine_resume函数中,将协程从COROUTINE_READY转为COROUTINE_RUNNING。参考源代码corontine.c中第167行。
- 第二次也是在coroutine_resume函数中,将状态从COROUTINE_SUSPEND转为COROUTINE_RUNNING。参考源代码corontine.c中第174行。
其中char stack[STACK_SIZE]用来做所有子协程的运行时栈,看全部代码,它在一个地方被保存,一个地方被恢复。
- 被保存的地方是在coroutine_yield函数中,在从子协程切换到主协程之前,再次调用_save_stack将当前的运行时栈保存到协程结构体中的栈缓存中。参考源代码corontine.c中第204行。
- 被恢复的地方是在coroutine_resume函数中,将状态从COROUTINE_SUSPEND转为COROUTINE_RUNNING时。他将栈内容从协程结构体中的栈缓存,拷贝到S->stack中,我们知道S->stack被所有子协程用作运行时栈。参考源代码corontine.c中第171行。
struct coroutine协程结构体
|
0001
0002
0003
0004
0005
0006
0007
0008
0009
0010
0011
0012
|
// 协程结构体struct coroutine { coroutine_func func; // 协程所运行的函数 void * ud; // 协程参数 ucontext_t ctx; // 当前协程的上下文 struct schedule * sch; // 当前协程所属的调度器 ptrdiff_t cap; // 当前栈缓存的最大容量 ptrdiff_t size; // 当前栈缓存的大小 int status; // 当前协程的运行状态(即:COROUTINE_{DEAD,READY,RUNNING,SUSPEND}这四种状态其一) char * stack; // 当前协程切出时保存下来的运行时栈}; |
其中ucontext_t ctx是当前子协程的运行时上下文,看全部源代码它在一个地方被保存,在两个地方被恢复。
- 被保存的地方是在coroutine_yield函数中,保存完当前子协程的栈后,调用swapcontext保存当前子协程的运行时上下文到ctx中,然后恢复主协程的上下文。参考源代码roroutine.c中第207行。
- 被恢复的地方都是在coroutine_resume函数中,参考源代码coroutine.c中的第167、174行。
协程的恢复coroutine_resume
|
0143
0144
0145
0146
0147
0148
0149
0150
0151
0152
0153
0154
0155
0156
0157
0158
0159
0160
0161
0162
0163
0164
0165
0166
0167
0168
0169
0170
0171
0172
0173
0174
0175
0176
0177
0178
0179
|
void coroutine_resume(struct schedule * S, int id) { assert(S->running == -1); assert(id >=0 && id < S->cap); struct coroutine *C = S->co[id]; if (C == NULL) return; int status = C->status; switch(status) { case COROUTINE_READY: getcontext(&C->ctx); // 初始化结构体,将当前的上下文放到C->ctx中 C->ctx.uc_stack.ss_sp = S->stack; // 设置当前协程的运行时栈顶,每个协程都共享S->stack C->ctx.uc_stack.ss_size = STACK_SIZE; // 设置当前协程的运行时栈大小 C->ctx.uc_link = &S->main; // 设置后继上下文,协程运行完毕后,切换到S->main指向的上下文中运行 // 如果该值设置为NULL,那么协程运行完毕后,整个程序退出 C->status = COROUTINE_RUNNING; // 设置当前协程状态为运行中 S->running = id; // 设置当前运行协程的ID uintptr_t ptr = (uintptr_t)S; // 设置当待运行协程的运行函数体,以及所需参数 makecontext(&C->ctx, (void (*)(void))mainfunc, 2, (uint32_t)ptr, (uint32_t)(ptr>>32)); swapcontext(&S->main, &C->ctx); // 将当前上下文放到S->main中,再将C->ctx设置为当前的上下文 break; case COROUTINE_SUSPEND: // 将原来保存的栈数据,拷贝到当前运行时栈中,恢复原运行时栈 memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size); S->running = id; C->status = COROUTINE_RUNNING; swapcontext(&S->main, &C->ctx); break; default: assert(0); }} |
协程的切出coroutine_yield
|
0181
0182
0183
0184
0185
0186
0187
0188
0189
0190
0191
0192
0193
0194
0195
0196
0197
0198
0199
0200
0201
0202
0203
0204
0205
0206
0207
0208
|
static void _save_stack(struct coroutine *C, char *top) { char dummy = 0; assert(top - &dummy <= STACK_SIZE); // top - &dummy表示当前协程所用的运行时栈的大小 if (C->cap < top - &dummy) // 如果协程结构体中栈空间小于所需空间大小,则重新分配内存空间 { free(C->stack); // 释放老的栈缓存区 C->cap = top - &dummy; // 设置新的栈缓存区最大容量 C->stack = malloc(C->cap); // 重新分配栈缓存区 } C->size = top - &dummy; // 设置新的栈缓存区大小 memcpy(C->stack, &dummy, C->size); // 将当前的运行时栈的数据,保存到协程中的数据缓存区中}void coroutine_yield(struct schedule * S) { int id = S->running; // 获得当前运行协程的id assert(id >= 0); struct coroutine * C = S->co[id]; assert((char *)&C > S->stack); _save_stack(C, S->stack + STACK_SIZE); // 保存当前子协程的运行时栈,到协程私有栈缓存中 C->status = COROUTINE_SUSPEND; // 设置为挂起状态 S->running = -1; swapcontext(&C->ctx , &S->main); // 将当前运行时栈保存到ctx中,并且切换到S->main所指向的上下文中} |
参考
1.https://blog.csdn.net/qq910894904/article/details/419111752.https://github.com/zfengzhen/Blog/blob/master/article/ucontext簇函数学习.md
3.http://www.ilovecpp.com/2018/12/19/coroutine/