- ORM框架:SQLAlchemy(code first)
- 作用:
- 提供简单的规则
- 自动转换成SQL语句
- DB first:手动创建数据库以及表 --> ORM框架 --> 自动生成类
- code first:手动创建数据库和类 --> ORM框架 --> 自动创建数据表
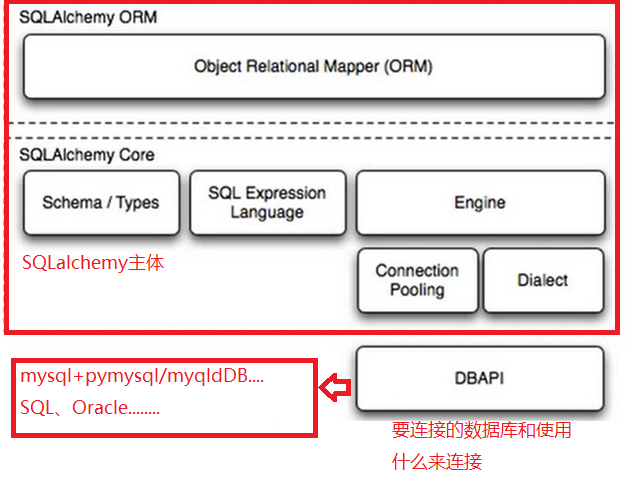
- DBAPI有许多:如:mysql+pymysqldb、mysql+pymysql、oracle+cx_oracle.........
格式:<mysql+pymysqld>://<user>:<password>@<host>:<port>/<数据库名>[?options] # []代表可选的
例子:engine = create_engine("mysql+pymysqld://root:@127.0.0.1:3306/db1?charset=utf8",max_overflow=5) # 最后一个代表最大连接数是5
- 功能:
- 创建数据库表
- 连接数据库(非SQLAlchemy执行的,是pymysql之类的能连接数据库的工具执行的)
- 把类转换成SQL语句
- 操作数据行
- 增
- 连接完后 Session = sessionmaker(bind=engine)
- session = Session() # 最大连接不是有5吗,从连接池中取一个出来
- 假设已经创建了一个类叫User,里面有一列叫name
- obj = User(name='小明')
- session.add(obj)
- 也可以一次性添加多个
objs=[User(name='小明'),User(name='小明'),User(name='小明')]
session.add_all(objs) - session.commit() # 记得增,删,改都要提交
- session.close() # 记得关闭
- 删
- user_type_list = session.query(UserTpye).filter(User.id>2).delete()
- 改
- user_type_list = session.query(UserTpye).filter(User.id>2).update({'name':'小明'})
- user_type_list = session.query(UserTpye).filter(User.id>2).update({UserTpye.name:UserTpye.name+'xx‘},synchronize_session=False)
# 这样就可以使用变量增加参数了(字符串的) - ser_type_list = session.query(UserTpye).filter(User.id>2).update({UserTpye.id:UserTpye.id+1},synchronize_session='evaluate')
# 这样就可以使用变量增加参数了(数字的)
- 查
- user_type_list = session.query(UserTpye).all()
# 如果type(user_type_list[0] ),会发现,这其实是个对象,与前面的每一个对象就是一行对应了起来 - 也能加条件 user_type_list = session.query(UserTpye).filter(User.id>2)
- for row in user_type_list:
print(row.id,row.title) - 还有分组,排序,连表,通配符,子查询,分页limit,union,where....
- ret = session.query(Users).filter(Users.id > 1 ,Users.name == '小明').all() # 默认是and
- ret = session.query(Users).filter(Users.id.between(1,3),Users.name=='小明').all()
- ret = session.query(Users).filter(~Users.id.in_([1,2,3])).all # in_要加下划线,~代表not
- ret = session.query(Users).filter_by(name='小明').all # 传的是参数,不是表达式
- 通配符 ret = session.query(Users).filter.(Users.name.like('e%'))
- 限制 ret = session.query(Users)[1:2]
- 排序 ret = session.query(Users).order_by(Users.name.desc()).all
ret = session.query(Users).order_by(Users.name.desc(),Users.id.asc()).all - 分组 ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id)>2).all() - 连表 ret = session.query(Users,UsersType) # 没有加条件的连表(笛卡尔积)
ret = session.query(Users,UsersType).filter(User.usertype_id == UserType.id) # 有条件的连表查询
ret = session.query(Users).join(UserType) # 相当于inner join
# 他会自己帮我们需找创建表时候的外键,所以后面的on usertype.id=users.user_type_id不用我们自己写 - 组合
q1=session.query(Users.name).filter(Users.id>2)
q2=session.query(Favor.caption).filter(Favor.id <2)
ret = q1.union(q2).all() # 取两组数据,上下连表,去重
ret = q1.union_all(q2).all() # 不去重 - 临时表 q1=session.query(UserType).filter(UserType.id >2).subquery() # 把q1当成子查询才能使用,不然就是SQL语句
ret = session.query(q1).all() # 相当于 select * from (select * fom UserType where UserType > 2) as A
ret = session.query(UserType.id,session.query(Users).subquery()).all() # 但是显示的是笛卡尔积
# 相当于select id,(select * from Users) from usertype
# 如果是 session.query(UserType,session.query(Users).filter(Users.id == 1).subquery) 也不行,因为相当于session.query(UserType,Users) 也是笛卡尔积
# 最后应该是这样的 session.query(UserType,session.query(Users).filter(Users.id == 1).as_scalar()) 把表变成数据
- user_type_list = session.query(UserTpye).all()
- 一点便利的方法
-
class UserType(Base): __tablename__= 'usertype' id=Column(Integer, primary_key = True, auto_increment = True) title=Column(String(32),nullable=True,index=True) class Users(Base): __tablename__= 'users' id= Column(Integer, primary_key = True, auto_increment = True) # 创建整形,是否是主键=True,是否自增=True name= Column(String(32),nullable=True,default='sf'index=True) # 创建字符,是否可以为空=True,默认值=‘sf’,是否创建索引=True email= Column(String(16),unique=True) # 是否唯一=True user_type_id = Column(Integer,ForeignKey("usertype.id")) # 创建外键 user_type = relationship("UserType",backref='xx') # 一般来说写在有外键的表中 # 创建关系,在list= session.query(Users) 时,可以直接user_type.title 把表中的title取出来,但是可以通过xx.id反向操作,把属于某个UersType ID 的所有人的ID取出来,user_type.title对应的是一行,是一个对象;而xx对应的是多行,是一个列表里有多个对象
-
- 增
- 创建数据库表
- 作用: