CS231n
2 K-Nearest Neighbors note ---by Orangestar
1. codes:
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
"""X is N × D where each row is an example.
Y is l-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
"""X is N × D where each row is an example we wish to predict label for"""
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Tpred = np.zeros(num.test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances)
# get the index with smallest distance
Ypred[i] = self.ytr[min_index]
# predict the label of the nearest example
return Ypred
2.
缺点:训练的时间复杂度是O(1),而预测的时间复杂度是O(N)
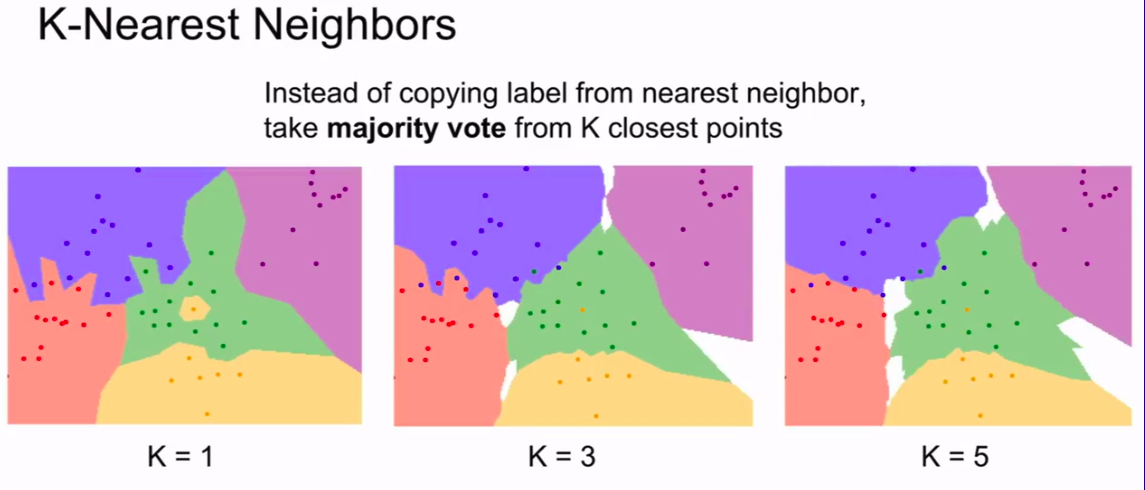
当然,这个算法还可以选择选取K个最近的点,然后加权投票
http://vision.stanford.edu/teaching/cs231n-demos/knn/
这个网站给出了一个直观的K与图形的关系
这也是其中一个decision boundary
当然,除了用L1(Manhattan)distance
$d_1(I_1,I_2) = sum_p|I_1^p - I_2^p| $
还可以用L2(Euclidean)distance
(d_2(I_1,I_2) = sqrt{sum_p(I_1^p - I_2^p)^2})
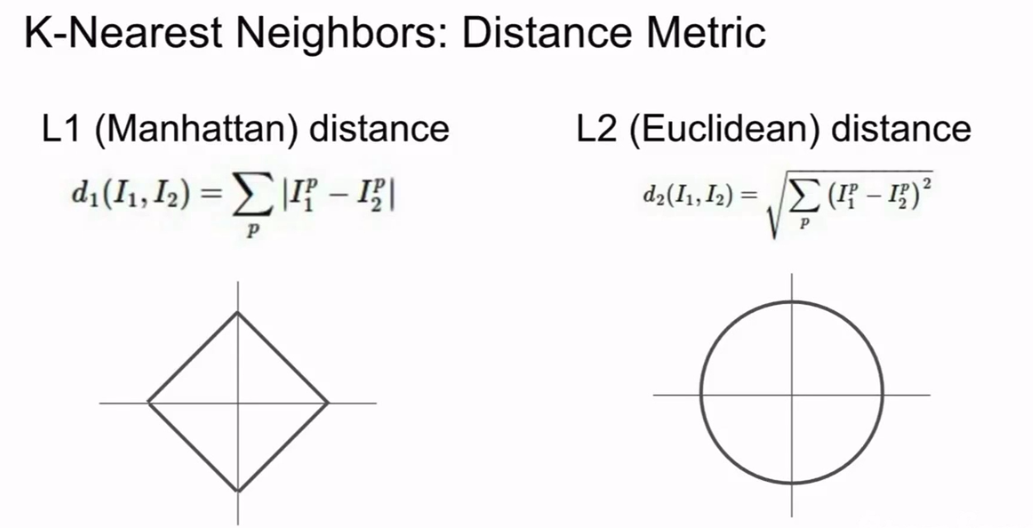
--曼哈顿距离和欧氏距离
注意:Manhattan distance 容易受到坐标轴的影响
总而言之,这些要人为决定的参数叫做超参数Hyperparameters

还有就是,如何选择L1还是L2呢?
这很难回答。但是如果与坐标轴有关的话,可能是L2更好,因为L1有坐标依赖。
但是没有坐标依赖的话可能是L1更加好一点。
当然,最佳方法是两个都尝试一下。看一下哪个更好。
下面总结一下如何选择超参数:
-
不要盲目选择在训练集中表现最佳的超参数。因为这样可能会过拟合。导致低方差高偏差。
-
可以将训练集划分。像机器学习上的一样。但是不要划分仅仅2个,训练集和测试集。这样看起来合理,其实很容易对测试集产生依赖性。
-
更好的方法是,把测试集(training),测试集(test),验证集(validation)
总结一下,我们通常的做法是:
在训练集上用不同超参数来训练算法,然后在验证集上进行评估,然后选择表现最好的超参数。最后的最后,我们在测试集上跑一下,当然,这也是我们要写到报告的数据,这样可以保证你的数据并没有造假。

当然。我们还可以用交叉验证集。cross-validation: split data into folds
这一般在小数据集上用的多,在深度学习不是很常用。
它的基本理念是:我们取出测试集数据,我们将整个数据和往常一样,保留部分数据作为最后使用的测试集,对于剩余的数据集,我们不是把它们分成一个训练集和一个验证集,而是分成很多(folds)份。在这种情况下,我们轮流将每一份都当做一个验证集,然后对每一份进行循环。这样你就会更有信心知道那组超参数的表现更加稳定。
但事实上,我们在深度学习的时候,因为计算量十分大,所以一般不采用!

经过交叉验证方法。会得到这样一组图:
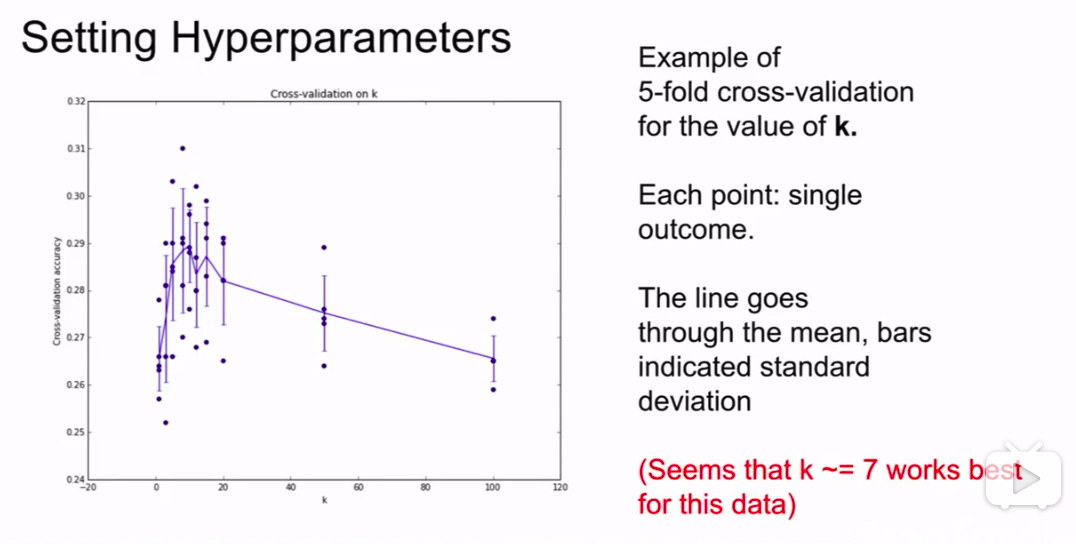
我们可以观察不同的情况下的方差来判别哪一种情况对我们更好。
(一般情况下机器学习都要这样做,画出一个超参数和误差的图)
但是!!KNN基本上不会用到上面提到的问题。
原因是
- 它测试时的运算时间很长!
- 用欧几里得距离或者L1这样的衡量标准在用在比较图像上很不合适!
如图:
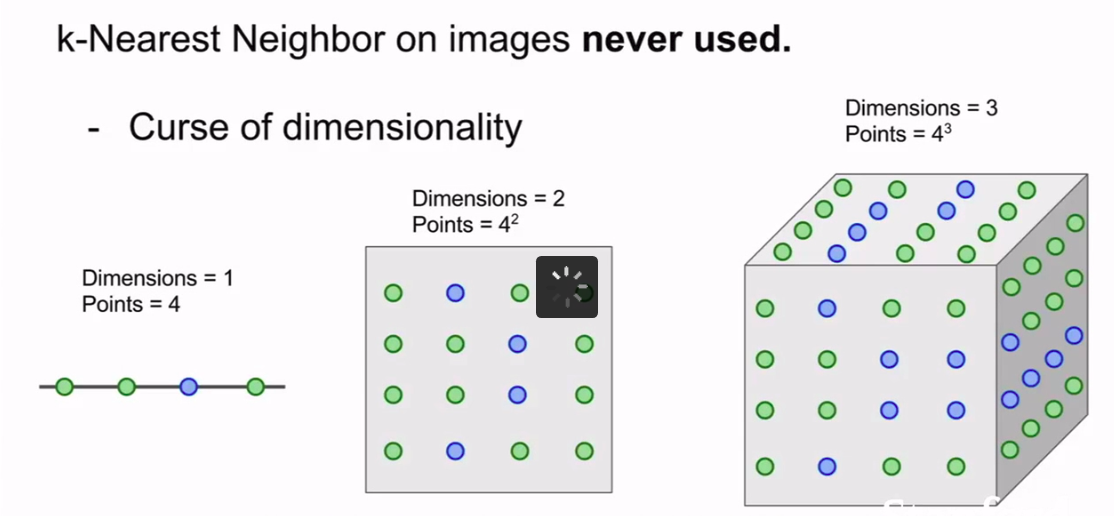
never used!太惨了
KNN算法还有一个问题:
称之为 :---维度灾难
因为可能样本之间相距很远,所以可能需要用大量的数据和高维度。