Andrew Ng 机器学习笔记 ---By Orangestar
Week_9(推荐系统)
1. Problem Formulation
这节就仅仅简单地介绍了一下 推荐系统的应用和实例。完全可以略。只需要清楚如何表示 评分还有未评分
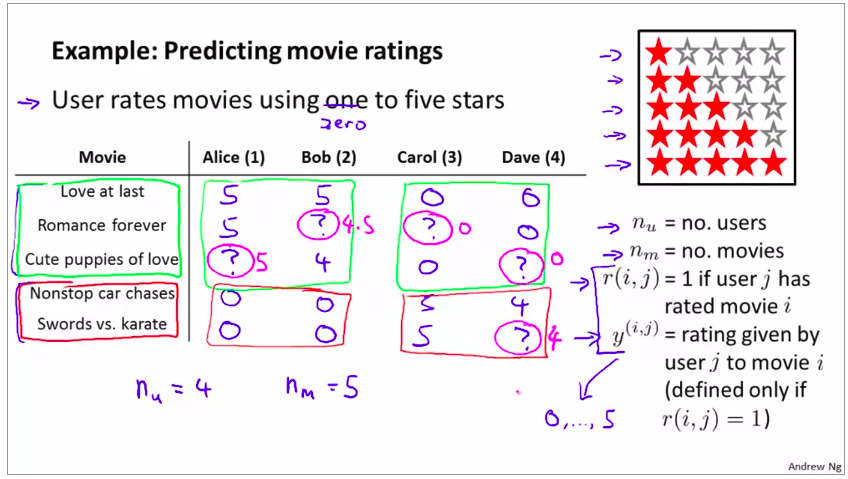
2. Content Based Recommendations
上节课谈到的电影评分推荐机制是
由用户已评分过的电影来预测用户未评分过的电影
这节课我们来学习 “基于内容的推荐”
我们首先用x_1,x_2来表示一部电影是属于爱情电影还是动作电影的比率,也就是成分
然后,每部电影我们都可以用一个特征向量来表示
所以,我们可以把对每个观众打分的预测,当成一个独立的线性回归问题,具体来说,比如对每一个用户j,我们都学习出一个参数( heta^{(j)}) ,在这里是一个三维向量。 当然,普遍来说是n+1维向量
如图所示:
总结:

那么,问题来了,如何来计算 ( heta)?
计算( heta)本质上就是一个基本的最小二乘回归或者线性回归

在这里可以把前面的常数项去掉
再重复一下: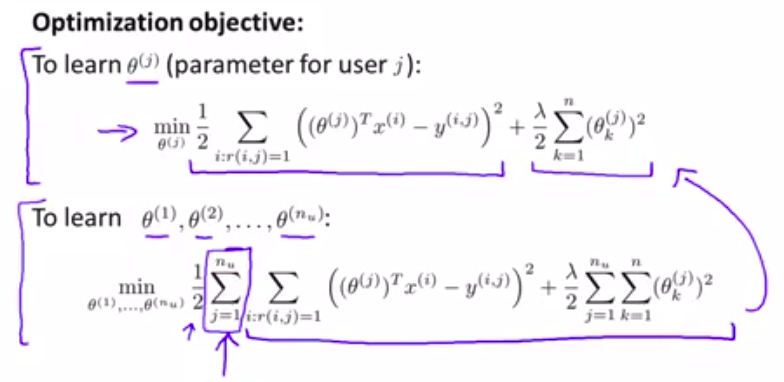
所以,可以采取和线性回归一样的优化方法:(梯度下降)

与线性回归的唯一区别就是 : 没有1m项!
好了,这就是基于推荐内容的推荐系统
下一次,我们讲了解没有推荐内容的推荐系统
注:
在这里摘抄一下别人的笔记:

3. Collaborative Filtering(协同过滤)
也就是 相似推荐? 例如你买了一本书,然后买完后,会显示:买了这本书的用户也买了其他书。
现在我们的情况:

然后通过用户对不同种类的电影的评价得到:
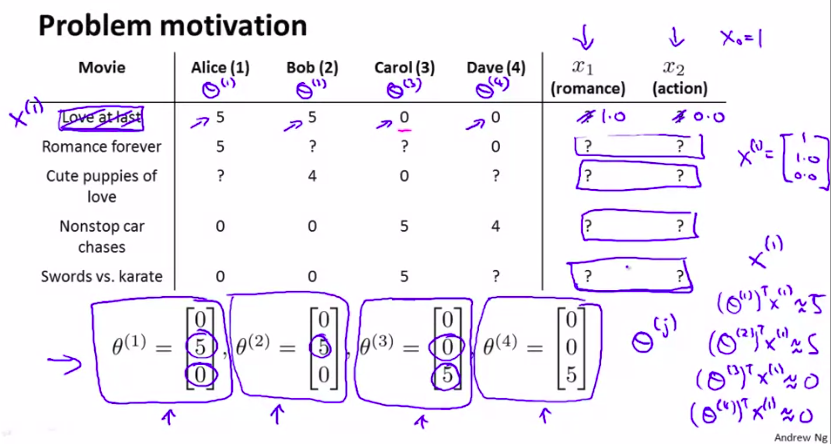
让我们写正式一点:
对于一个的时候:

当然,我们面对多个的时候:

这时候,我们需要的梯度下降规则就是:
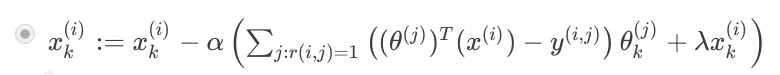
总结:这相当于从theta推导x,
上次我们是从x来推导theta

4. Collaborative Filtering Algorithm 协同过滤算法的改进
在上一节中,我们介绍了2种算法:

那么,如何同时计算出theta和x呢?
我们可以发现,这两项本质上是一样的:

所以,要同时计算theta和x就可以优化这个函数:

以前是鸡生蛋蛋生鸡,现在是一起生。
不过要注意的是,在新的算法中,
我们要去掉x_0 = 1 这个前提,因为
X和 heta此时变成n维
总结:“

注意,使用新算法的时候,开始的时候由于2个参数都没有计算出来,也没有得到,所以要随机初始化!!!


5. Vectorization: Low Rank Matrix Factorization(算法的向量化及其实例)
先看一个实例:

所以这时候Y就包含了这些数据了

然后,如图所示,可以将这个矩阵分解:
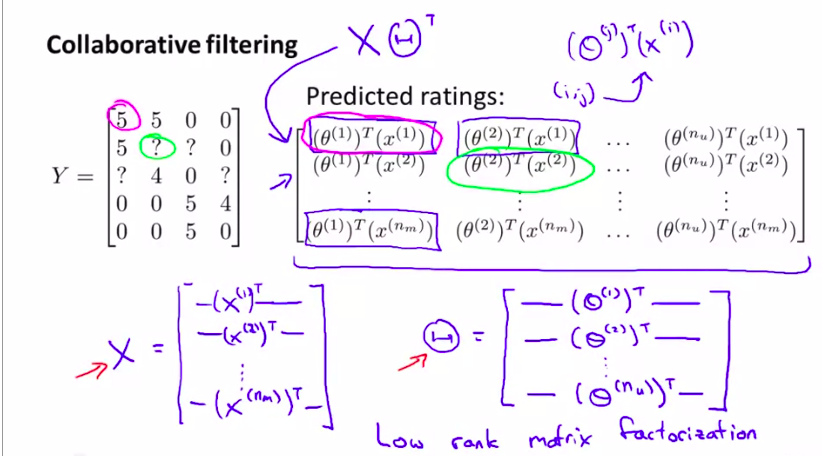
这种方法也叫:low rank matrix factorization
低秩矩阵分解
如何应用?

6. Implementational Detail: Mean Normalization
细节介绍:均值归一化
例子:有一个用户没有给任何一个电影评分
这样我们就要采用均值归一化了

然后。使用均值归一化:
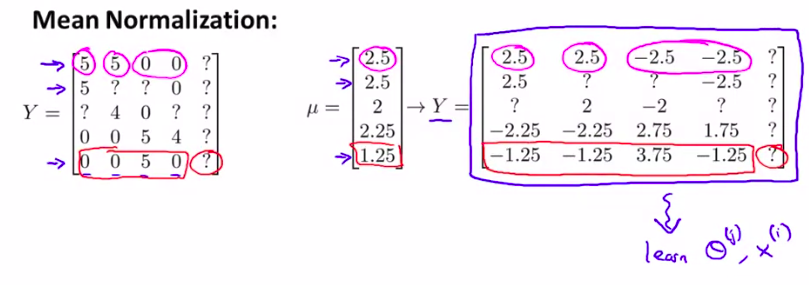
然后,使用过均值归一化后,我们要对这个矩阵进行操作,像之前一样用协同过滤算法
如图:
最后,感觉这一周学得不是很好,特别是推荐算法这一节,概念还是很模糊,可能是由于前面的下线性回归算法没有搞清楚吧。
做编程作业的时候一定要搞清楚!!!