类与函数的关系
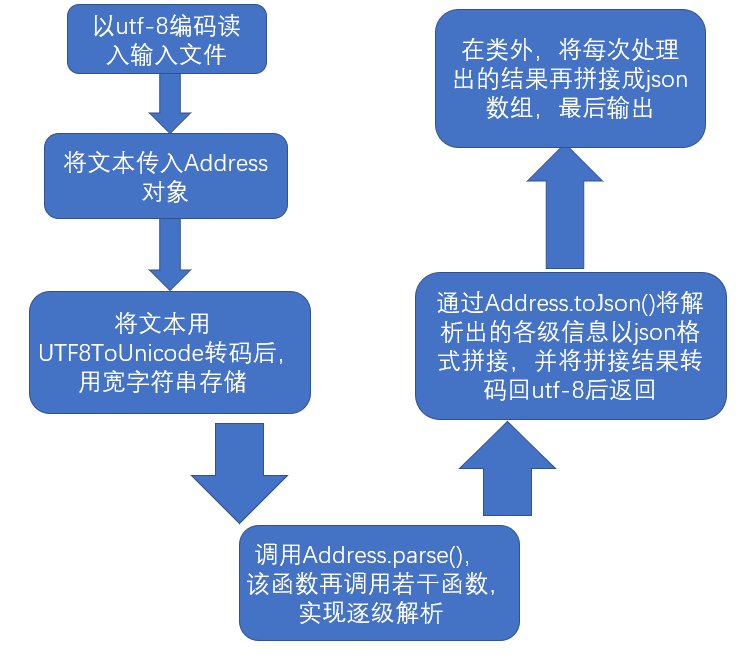
以流程图的形式大致描述处理思路
有关算法
* 文本匹配:说实话,对于这样小量的文本匹配工作,朴素的匹配算法已经足够(KMP之类的高效匹配算法由于其需要额外的空间开销和预处理时间,并不能体现出效率优势,徒增编程复杂度),因此我选择直接调用string中的find函数进行匹配。 * 地名检索并提取:由于文本匹配可优化的幅度极其有限,因此我主要在地名的检索上做一些工作。我将我国所有省、市两级的信息爬下来,以文本文件的形式存在本地。在类初始化时将其读入,用哈希表```unordered_map```储存,```key```为省份,```value```为该省份下所有市组成的```vector```。通过枚举所有省份来匹配地址中的省份,匹配完省份后,就可以枚举该省份下的市行政区,继续匹配市级。 * 独到之处:并没有什么独到之处,硬要说的话,大概就是我是少数用C++写这个项目的,踩了无数中文编码上的坑。还有我是用本地存表的形式来辅助地址解析的,核心逻辑也都是手写的,没有调用现成的一些接口,因此对于一些奇怪的情况难以正确解析。性能改进
- 原先对于省市的检索,是通过遍历整个文本文件,对于文本中的每个省(或市)都去查找能否匹配上输入地址,因此是省市数量*文本匹配的复杂度。
- 考虑用哈希表
unordered_map来存储省市信息,提高检索效率,对于确定省份的情况,从键值为该省份的vector中寻找市级行政区,而不需要全部枚举 - 性能分析图如下:
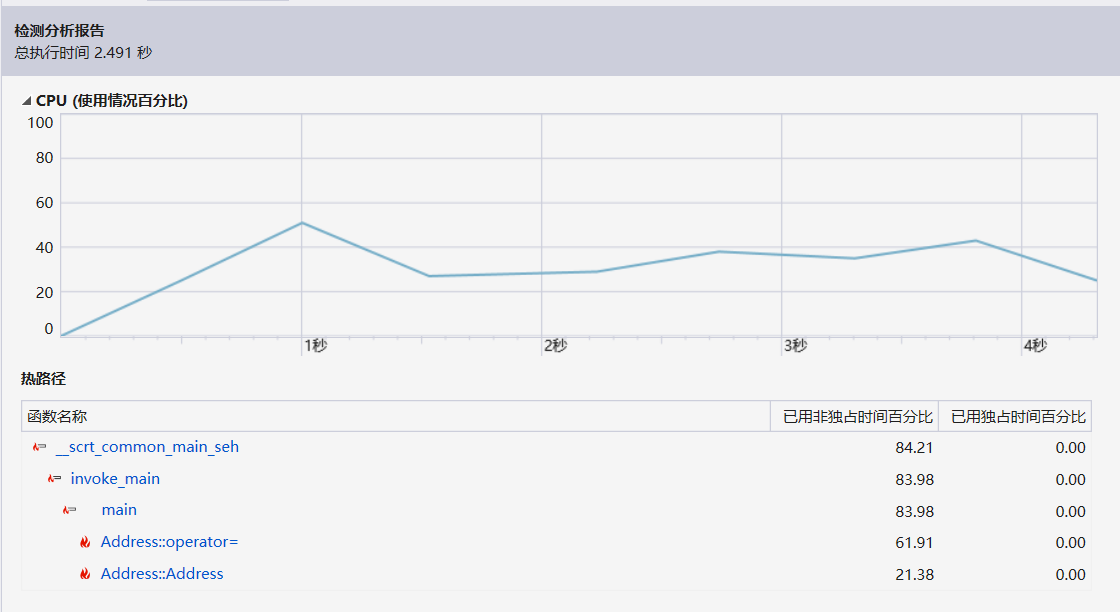
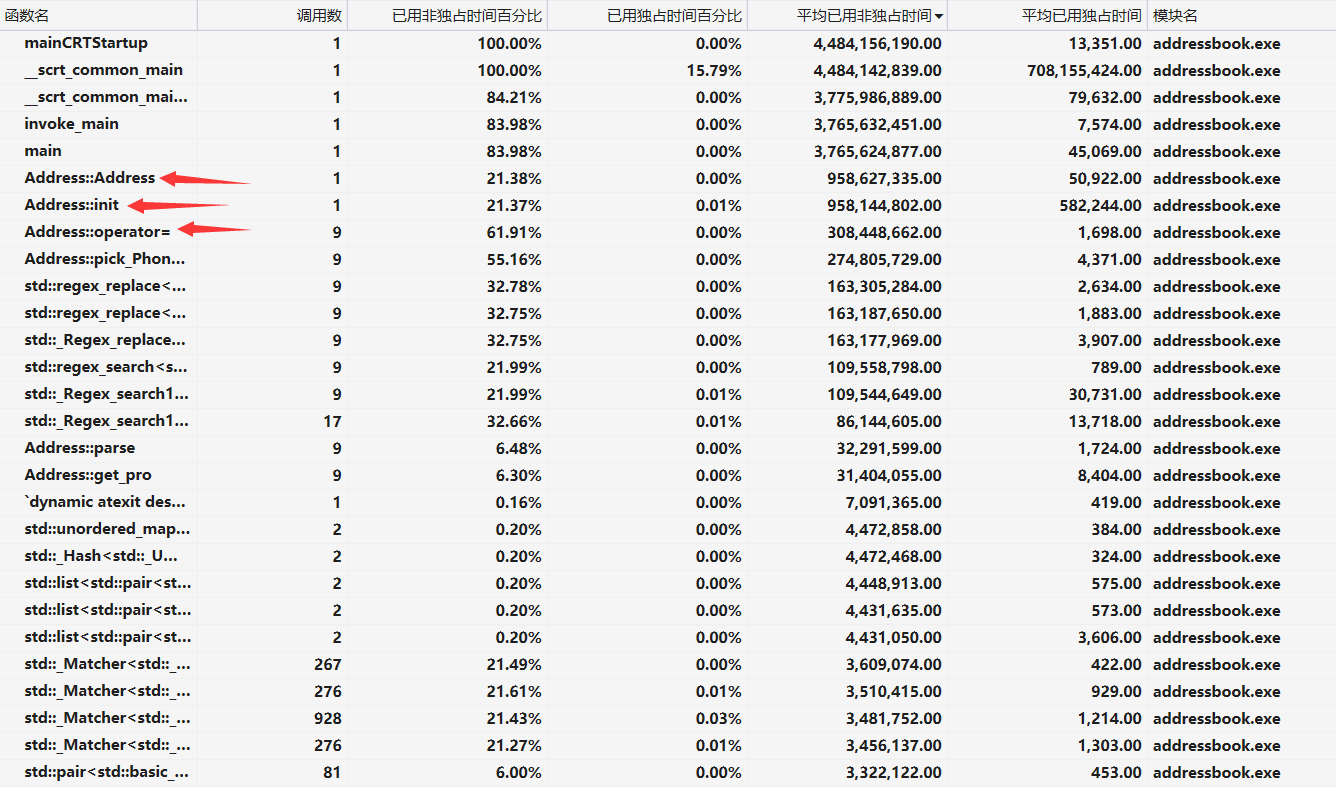
可以从上图看出,时间的开销主要在初始化上,也就是从文本文件中读入省、市信息并储存上。
单元测试
测试了一些比较容易错误解析的情况,如:
input:
1!洪嘹,广东佛山市高明区更15198460545合镇广明高速公路界村林场.
1!娄伤囚,13592755594浙江省杭州市所前镇袄庄陈村工业园区5号楼.
2!乐愿,山东省潍坊安丘15223742753市兴安街道南关头巷南关头幼儿园.
2!李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
1!张三,福建福州闽13599622362侯县上街镇福州大学10#111.
2!王五,福建省福州市鼓楼18960221533区五一北路123号福州鼓楼医院.
3!小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院.
1!小陈,广东省东莞市凤岗13965231525镇凤平路13号.
2!东海黄,上海市吊人区北大街89号垃圾堆.
output:
[{"姓名":"洪嘹","手机":"15198460545","地址":["广东省","佛山市","高明区","更合镇","广明高速公路界村林场"]},{"姓名":"娄伤囚","手机":"13592755594","地址":["浙江省","杭州市","所前镇袄庄陈村工业园区","","5号楼"]},{"姓名":"乐愿","手机":"15223742753","地址":["山东省","潍坊市","安丘市","兴安街道","南关头巷","","南关头幼儿园"]},{"姓名":"李四","手机":"13756899511","地址":["福建省","福州市","鼓楼区","鼓西街道","湖滨路","110号","湖滨大厦一层"]},{"姓名":"张三","手机":"13599622362","地址":["福建省","福州市","闽侯县","上街镇","福州大学10#111"]},{"姓名":"王五","手机":"18960221533","地址":["福建省","福州市","鼓楼区","","五一北路","123号","福州鼓楼医院"]},{"姓名":"小美","手机":"15822153326","地址":["北京","北京市","东城区","","交道口东大街","1号","北京市东城区人民法院"]},{"姓名":"小陈","手机":"13965231525","地址":["广东省","东莞市","","凤岗镇","凤平路13号"]},{"姓名":"东海黄","手机":"","地址":["上海","上海市","吊人区","","北大街","89号","垃圾堆"]}]
可以发现对于第二条,实际上是缺失了第三级地址,但我误把工业园区当作了第三级,对此.......不借助成熟接口且不存入一张信息量巨大的表的话,我真的没办法了。