Introduction
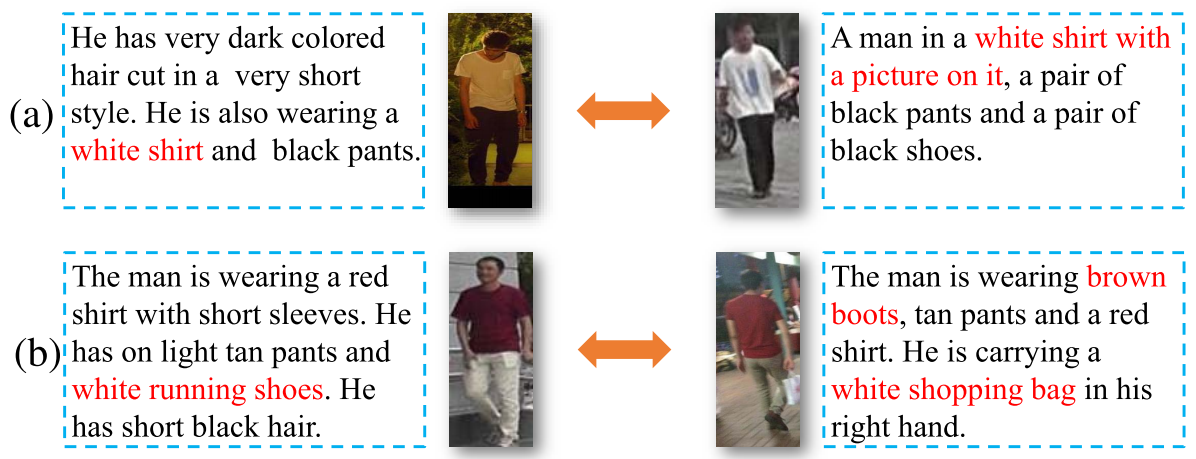
作者认为,大部分现有方法都将图文特征平等地投影到相同的特征空间,但现实中图文信息并不完全等价。比如,图像中包含的光照条件、图像分辨率、视角、背景等信息很少会被文字描述到,如下图所示。

此外,两个相似行人之间的一些关键差异信息很容易被干扰因素影响,如下图所示,(a)中视觉特征中白色T恤是关键信息,但前者在提取特征时很容易被光照因素干扰,同理(b)中很容易被视角因素干扰。因此,需要用文本信息来引导视觉特征的提取,降低视觉特征被干扰因素影响。
为此,本文提出了一种跨模态知识自适应(Cross-Modal Knowledge Adaptation, CMKA)的方法。
Proposed Method
(1) 框架图:
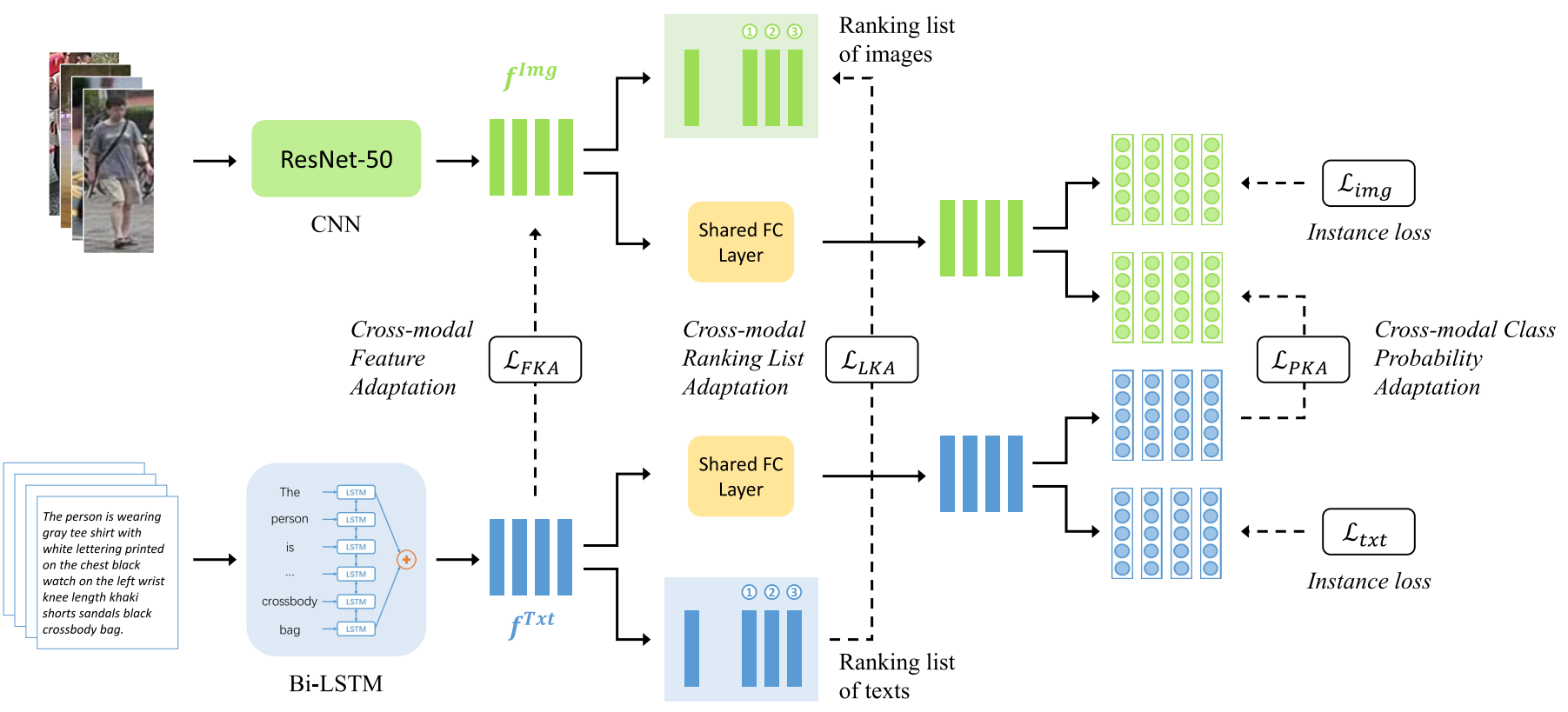
图像特征提取采用ResNet-50 + 1x1卷积,压缩为1024维特征;
文本特征提取采用one-hot + bi-LSTM,双向特征进行级联,通过最大池化策略获取1024维特征。
(2) Cross-Modal Feature Adaptation:
由于一些图像信息很难被文本描述,因此为了促进提取的视觉特征去适应文本描述,作者设计了cross-modal feature knowledge adaptation (KFA):
![]()
这里仅仅训练图像分支,固定了文本分支的参数。
(3) Cross-Modal Ranking List Adaptation:
对于这个损失的个人理解:让两个模态之间的rank list尽量相近,作者为了计算方便,采用最高概率的文本rank list,让对应的图像rank list也有高概率。
假设batch中第i个样本为query,其余为gallery,排序后候选样本序列为![]()
![]() ,图像序列按此排列的概率为:
,图像序列按此排列的概率为:
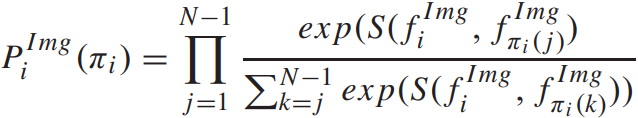
其中![]()
同理,文本排列的概率为:
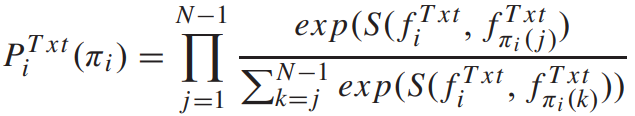
选择概率最大的文本排列,即:![]()
训练使得对应的图像排列也概率更大,即cross-modal list-wise knowledge adaptation (LKA):
![]()
同KFA,这里仅仅训练图像分支,固定了文本分支的参数。
(4) Cross-Modal Class Probability Adaptation:
此部分的目的是让两个模态的分类分布相近,采用了一个共享全连接层,输出两个模态的d分类分布,即:
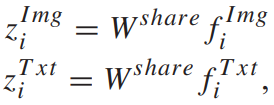
采用softmax进行归一化,即:
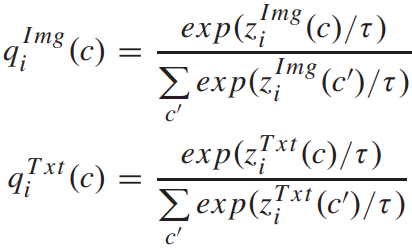
采用KL散度拉进两者的概率分布,即:
![]()
(5) 训练目标:
除了上述三阶段知识适应性损失,作者也对每个模态内采用了instance loss,即:

最终损失函数为:
![]()
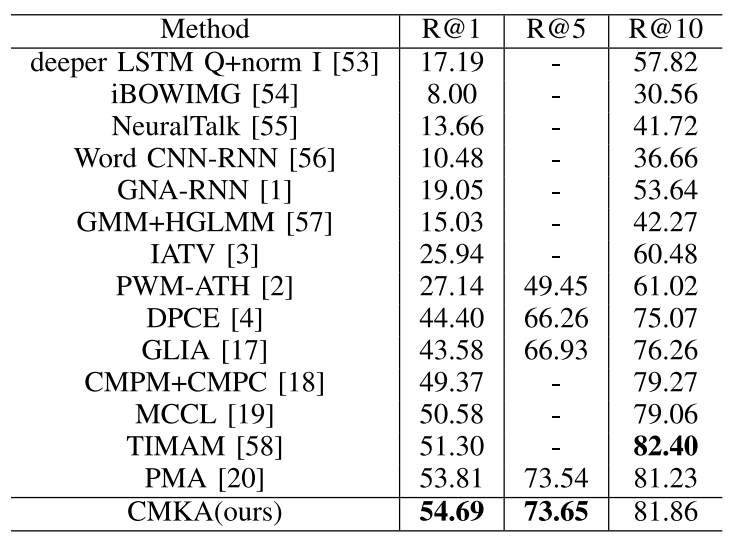
Experiments