Introduction
1) Motivation:
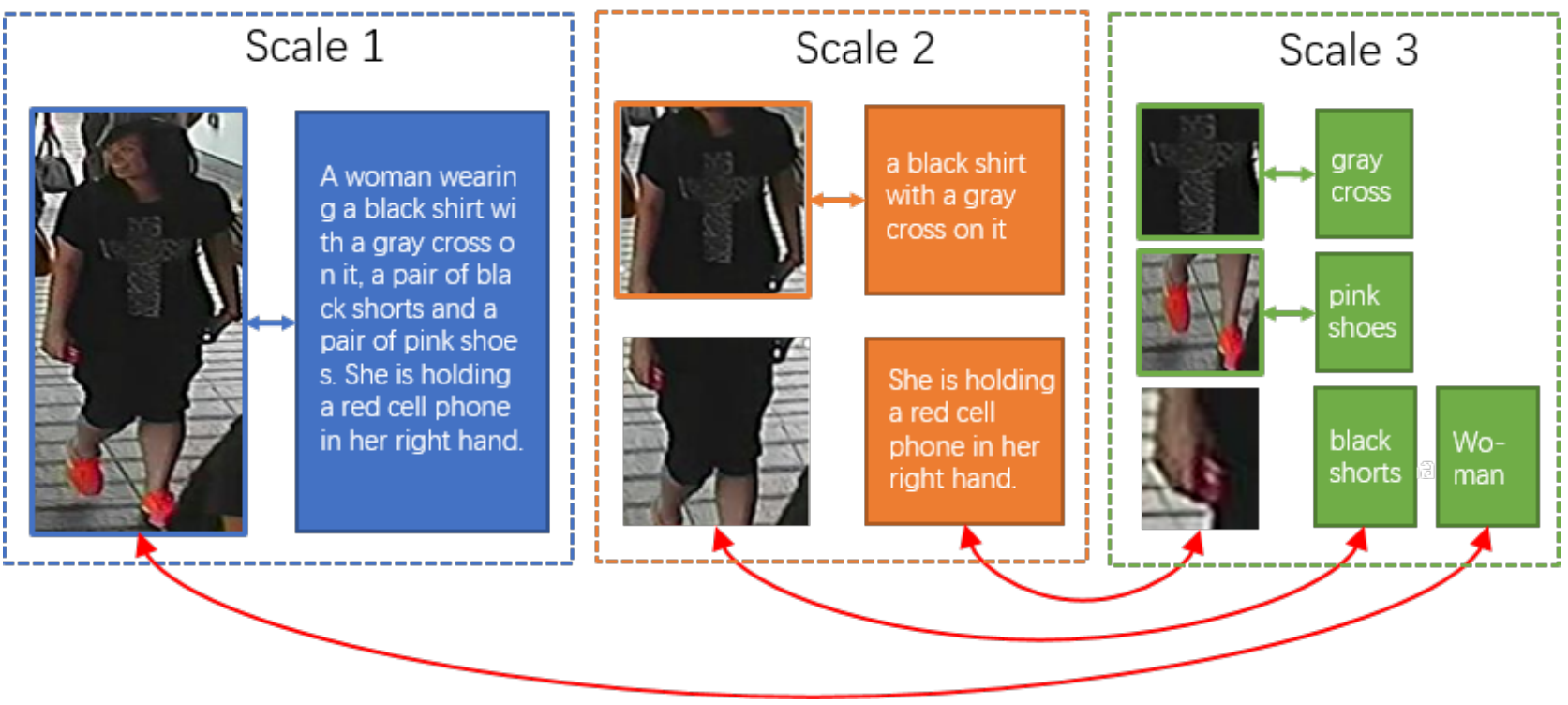
现有大部分visual textual跨模态方法只采用了单一尺度的特征,比如只采用全局尺度或者只采用局部尺度。本文提出了一种动态对齐图文多尺度特征的方法:Non-local Alignment over Full-Scale Representation (NAFS).
2) Contribution:
① 提出了条纹打乱策略 (Stripe Shuffling) 来学习更好的全尺度局部;
② 通过增加了局部约束注意力 (licality-constrained attention) 来优化BERT模型;
③ 设计了可调节的上下文非局部对齐机制 (contextual non-local attention)来提取图文多尺度特征表示,并实现对齐;
④ 基于视觉最邻近,设计了新的Re-ranking算法,
Proposed Method
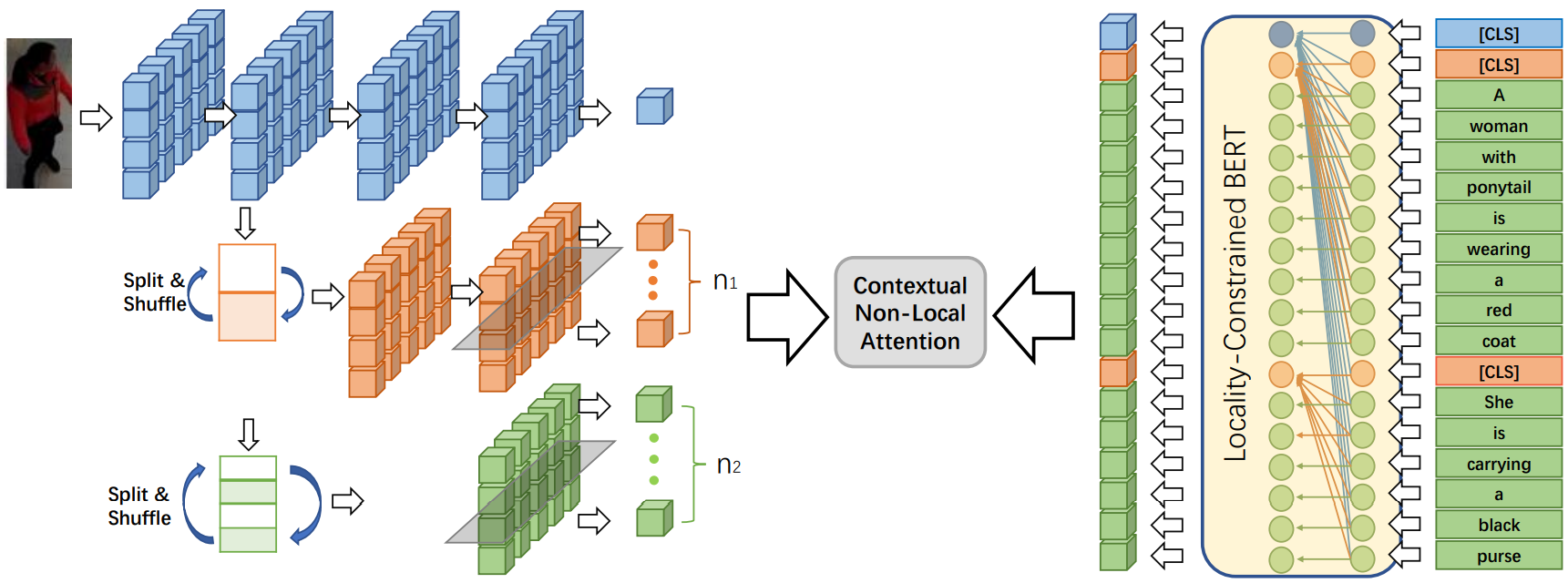
1) 视觉特征提取:
基于ResNet设计了阶梯式骨干网络 (Staircase Bacbone Structure),如上图所示,采用了3个branch,蓝色branch提取全局特征,黄色branch提取region特征,绿色branch提取patch特征。
2) 特征图分割打乱 (Split and Shuffle Operation):
将特征条纹打乱,并在纵轴上重新排序。该操作可以打破连续条纹之间的内在关系,使模型可以集中在每个条纹内的信息。最后得到的特征向量集合为:![]() 。
。
3) 文本特征提取:
文本也采用了多粒度的BERT特征提取,包括:sentence-level、sub-sentence-level、word-level。其中,BERT嵌入了locality-constrained attention模块,可以理解为,把文本全局的attention按[CLS]划分成若干sub-sentence,对sub-sentence内部的Attention做一个归一化,即:
![]()
其中![]() 表示query,
表示query,![]() 表示key,
表示key,![]() 表示value,U表示sub-sentence包含的token,
表示value,U表示sub-sentence包含的token,![]() 表示第 i 个token是否包含在U内。
表示第 i 个token是否包含在U内。
由此提取出不同尺度的文本特征向量集合:![]() 。
。
4) 上下文非局部注意力机制 (Contextual Non-Local Attention Mechanism):
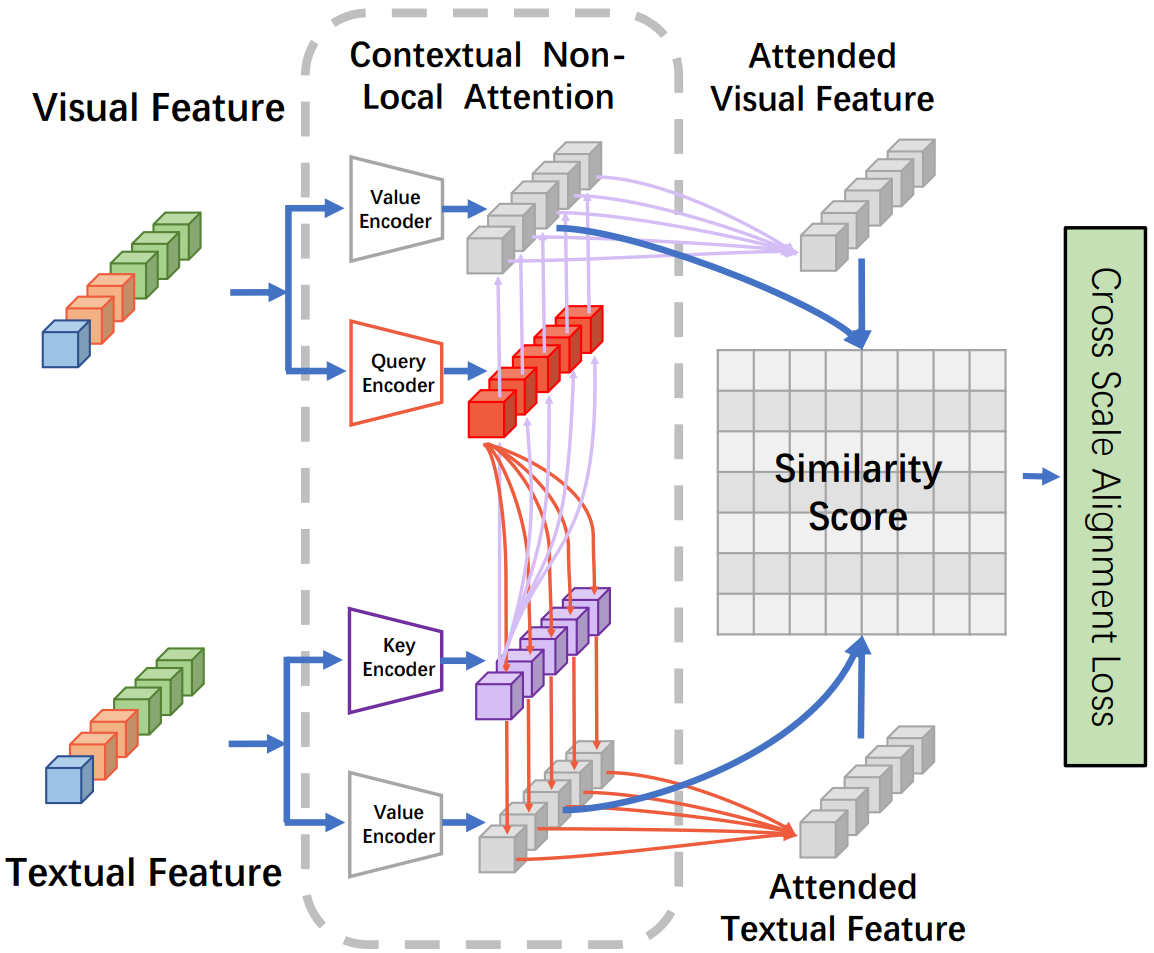
通过线性投影,将图像特征集合映射为query和value,即:![]() ,
,![]()
![]() ,将文本特征集合映射为key和value,即:
,将文本特征集合映射为key和value,即:![]() ,
,![]() 。
。
① 计算第a个图像value对应的文本特征:
首先计算第a个query和第b个key的余弦相似度,即:
![]()
进一步正则化为:
![]()
再采用focal attention对无关项进行过滤:
![]()
最后计算文本特征的权重,并进行加权:
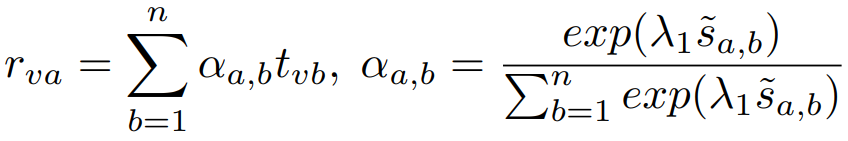
② 定义第a个图像value与其对应文本特征的相关度,即:
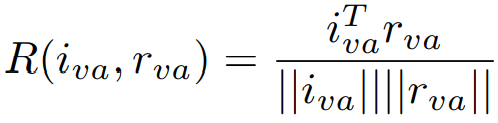
通过平均所有相关度R,获取整个图像-文本对的相似度,即:
![]()
③ 将文本key作为query,图像query作为key,同理上述操作,获取文本-图像对相似度,即:
![]()
④ 对齐目标:
引入目标函数 Cross-Scale Alignment Loss (CSAL),即给定一个mini-batch的图像![]() 、文本
、文本![]() ,得到图文对
,得到图文对![]() ,计算每个图文对的相似度,最大化匹配图文对的相似度,并限制非匹配图文对的相似度,即:
,计算每个图文对的相似度,最大化匹配图文对的相似度,并限制非匹配图文对的相似度,即:
![]()
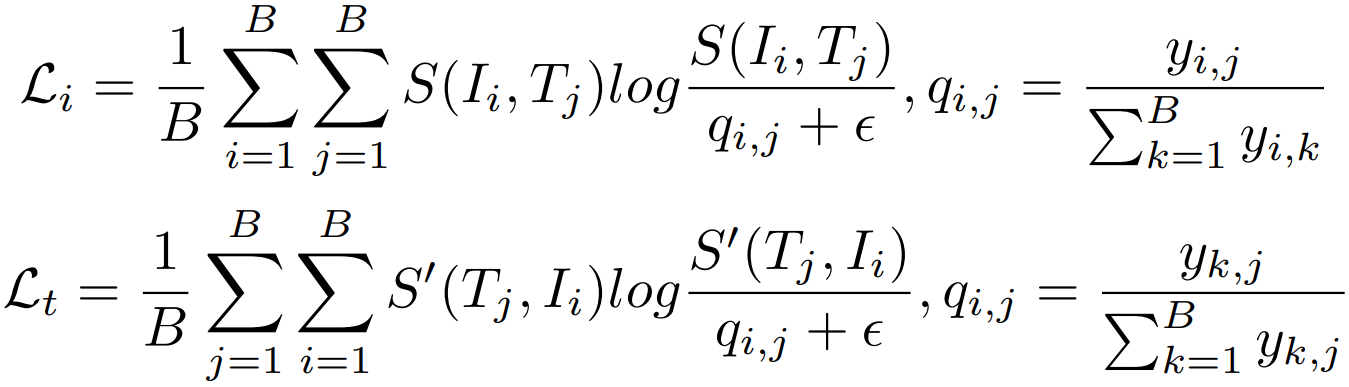
最终的损失函数也对全局特征应用了CMPM损失和CMPC损失。
5) Re-Ranking by Visual Neighbors (RVN):
给定一个文本query T,依据上述计算的文本对相似度进行初始排序。然后,对初始排序序列中的每一个图像 I,寻找其相似度最高的若干个相邻图像并定义为![]() ,寻找文本query T相似度最高的若干个相邻图像并定义为
,寻找文本query T相似度最高的若干个相邻图像并定义为![]() 。为了加速计算,只使用全局特征寻找相邻结点,然后重新计算图文对的相似度:
。为了加速计算,只使用全局特征寻找相邻结点,然后重新计算图文对的相似度:![]() 。最后的相似度采用原始相似度和新的Jaccard距离的平均值。
。最后的相似度采用原始相似度和新的Jaccard距离的平均值。
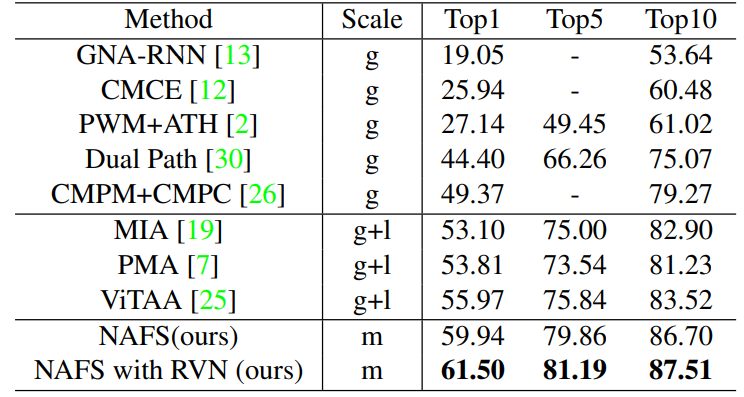
Experiments