Introduction
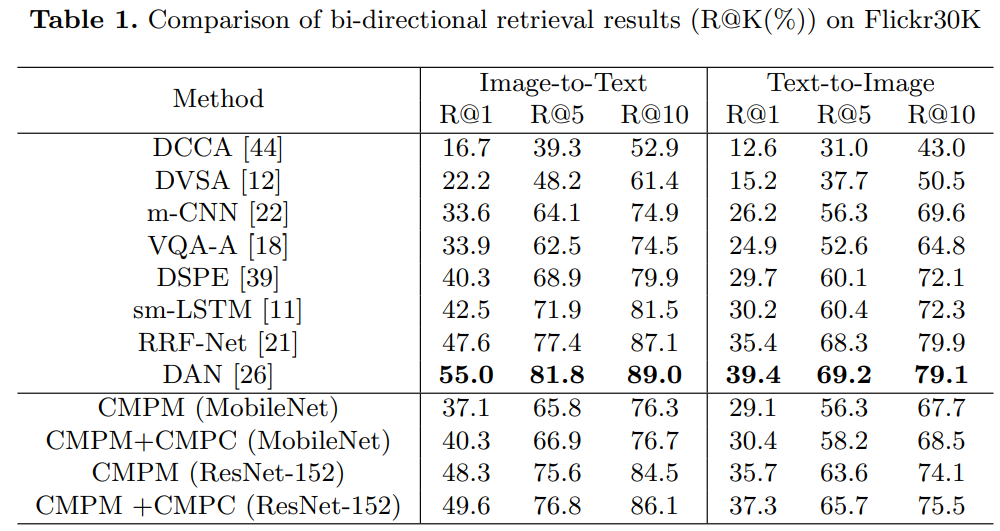
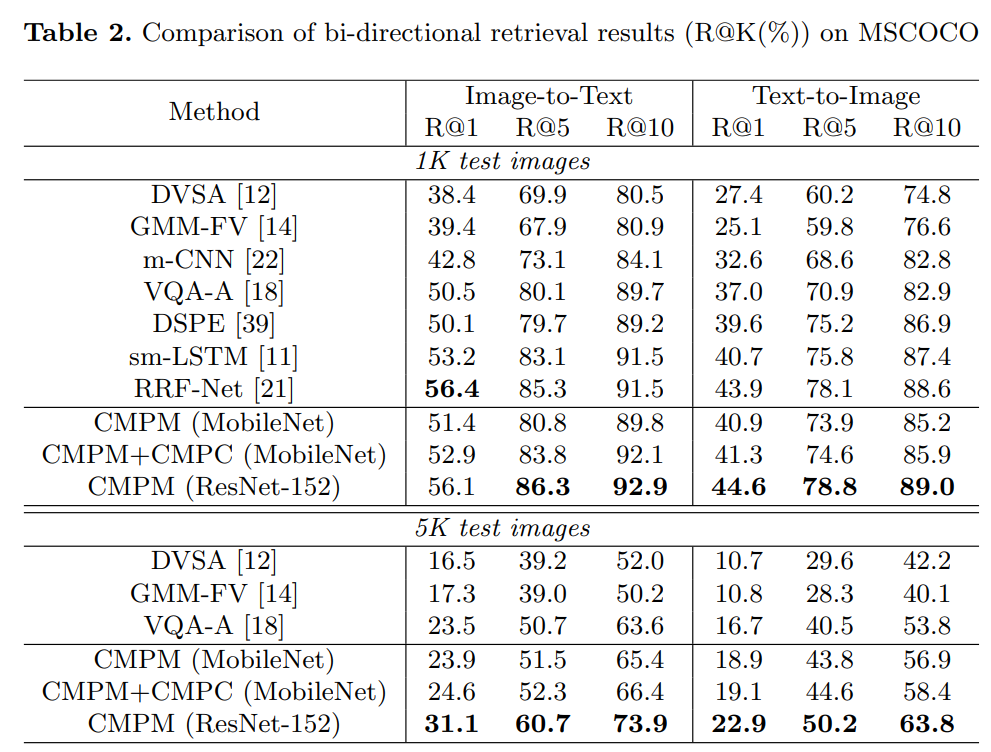
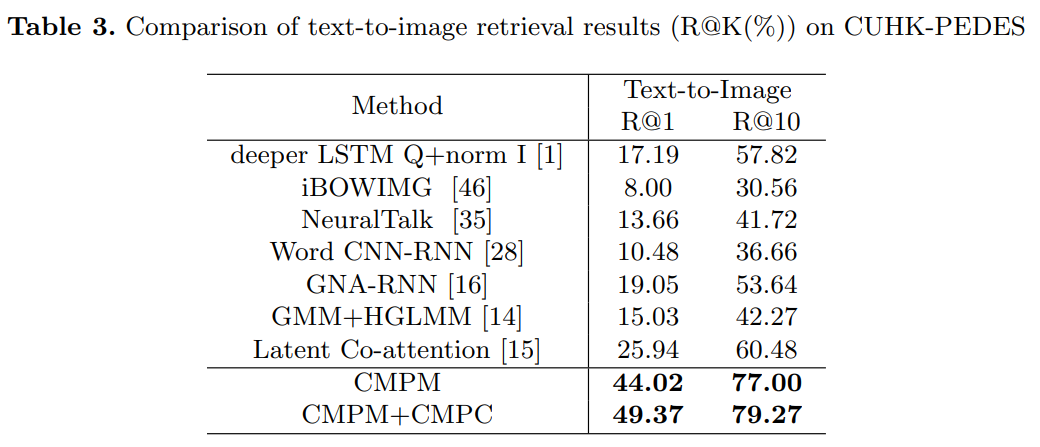
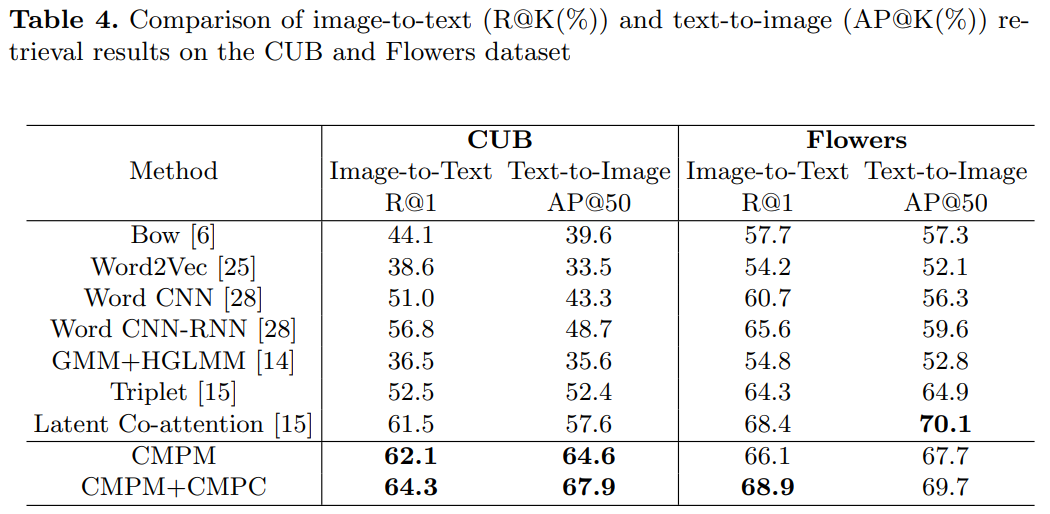
对于image-text embedding learning,作者提出了 cross-modal projection matching (CMPM) loss 和 cross-modal projection classification (CMPC) loss。前者最小化两个模态特征投影分布的KL散度;后者基于norm-softmax损失,对模态A在模态B上的投影特征进行分类,进一步增强模态之间的契合度。
The Proposed Algorithm
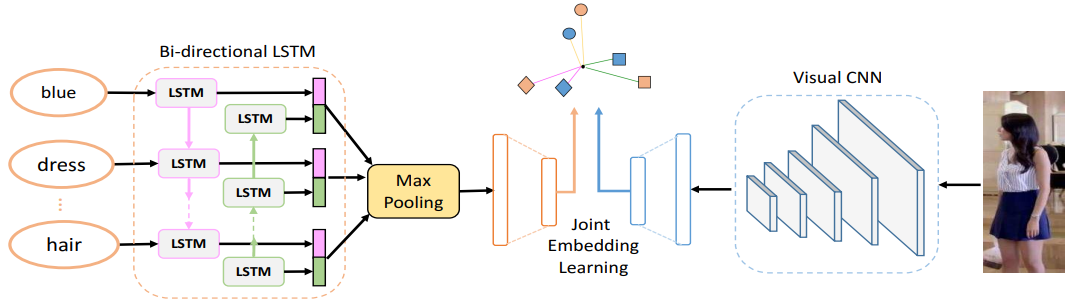
Network Architecture
文本特征:Bi-LSTM + 最大池化策略
图像特征:MobileNet、ResNet-152
Cross-Modal Projection Matching
假设每对输入为![]() ,其中 x 表示图像,z 表示文本,
,其中 x 表示图像,z 表示文本,![]() 表示文本图像匹配,其匹配概率计算为:
表示文本图像匹配,其匹配概率计算为:![]() 。
。

对于一个图像,可能存在多个匹配的文本,在每个mini-batch中,对匹配概率进行正则化,即:![]() ,匹配损失为:
,匹配损失为:![]() ,
,![]() 。
。
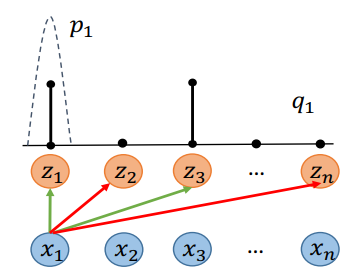
匹配损失中可以看出其本质是KL损失,当正确结果 p 比较低时,希望网络做出的预测 q 也比较低。再加上文本图像换位后得到的损失,CMPM损失计算为:![]() 。
。
Cross-Modal Projection Classification
传统的softmax计算为:![]()
Norm-softmax损失为:![]()
相比之下,norm-softmax采用了权重正则化项,下图直观来说:不同权重向量被归一化到相同长度,分类结果由原先的![]() 简化为
简化为![]() ,使得样本分布与权重向量更加紧密。
,使得样本分布与权重向量更加紧密。

传统的softmax损失对原有的特征进行分类,而CMPC损失对A在B上的投影特征进行分类:
![]()
![]()
![]()
Experiments