Introduction
作者把Vision Transformer (ViT) 应用到目标重识别任务上。ViT在图像分类任务上首次得到应用,它将图像切割成若干小块,每个小块拉成序列,输入到transformer中。在ReID任务中,空间的对齐对于特征学习而言非常重要,因此把transformer应用到ReID中需要考虑到空间的对齐。在此论文中,作者把ViT作为backbone提取特征,并对ReID任务进行调整适配,提出一个名为ViT-BoT的Baseline。(BoT指的是Bag of Tricks)
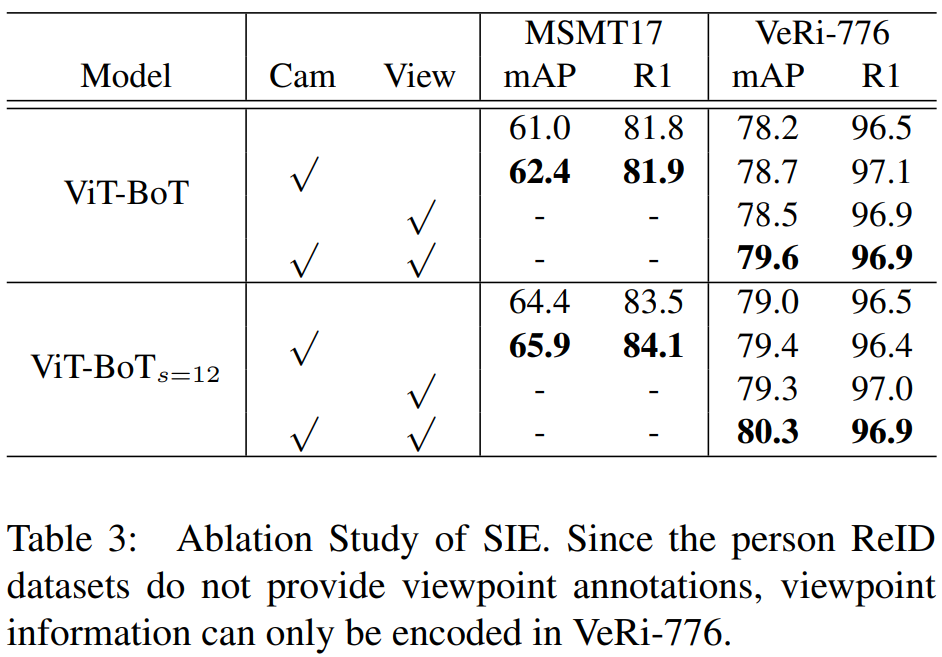
图像往往包含了众多非视觉信息,即视角、相机风格等,基于CNN的方法需要设计特定的网络结构才能提取出这些非视觉信息,比如针对相机风格设计Camera-based Batch Normalization (CBN),针对视角问题设计Viewpoint-Aware Network (VANet)。为了处理这些非视觉信息(side information),作者在transformer中通过向量投影进行编码,该模块命名为Side Information Embedding (SIE).
为了更好地训练ViT-BoT,作者在最后一层设计了Jigsaw branch,与标准的全局分支并列。虽然全局分支可以对全局的特征编码,但只有少数有判别力的patch作主要贡献。因此,在Jigsaw branch中,设计了jigsaw patch module (JPM),小patch在JPM中打乱重组成更大的patch。这样操作有两个原因:1) 重组patch使得模型适应扰动;2) 新构建的patch依然包含全局的信息。
通过结合SIE和JPM模块,作者提出了最终的模型框架TransReID。
Methodology
ViT-BoT
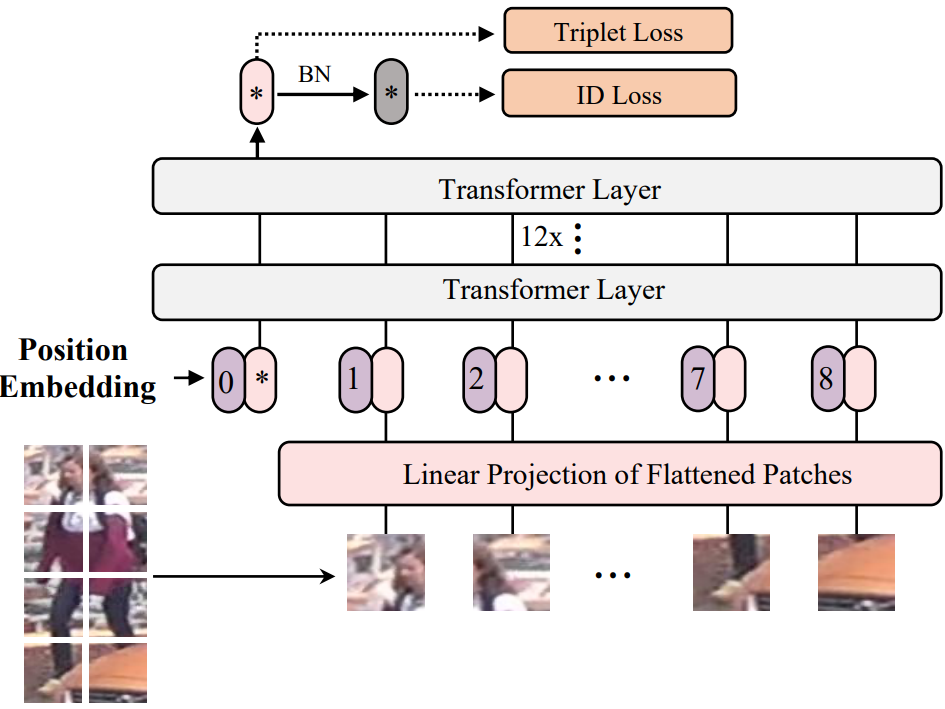
1) Overlapping Patches:
首先将图像划分成边长为 P 的patch,假设图像为 HxW 尺寸,patch划分窗口的间隔为 S,则patch数量为:![]() 。
。
2) Position Embedding:
ViT在ImageNet上的预训练模型会加载到网络中,但位置投影的预训练参数不加载,因为不同任务的图像像素不一样,位置信息并不通用。
3) Feature Learning:
最后一层encoder layer输出的class token为全局特征向量![]() ,其余对应 N 个patch的输出为
,其余对应 N 个patch的输出为![]()
![]() 。随后采用BNNeck技巧的交叉熵损失
。随后采用BNNeck技巧的交叉熵损失![]() 和soft-margin三元组损失,即:
和soft-margin三元组损失,即:![]() 。
。
TransReID
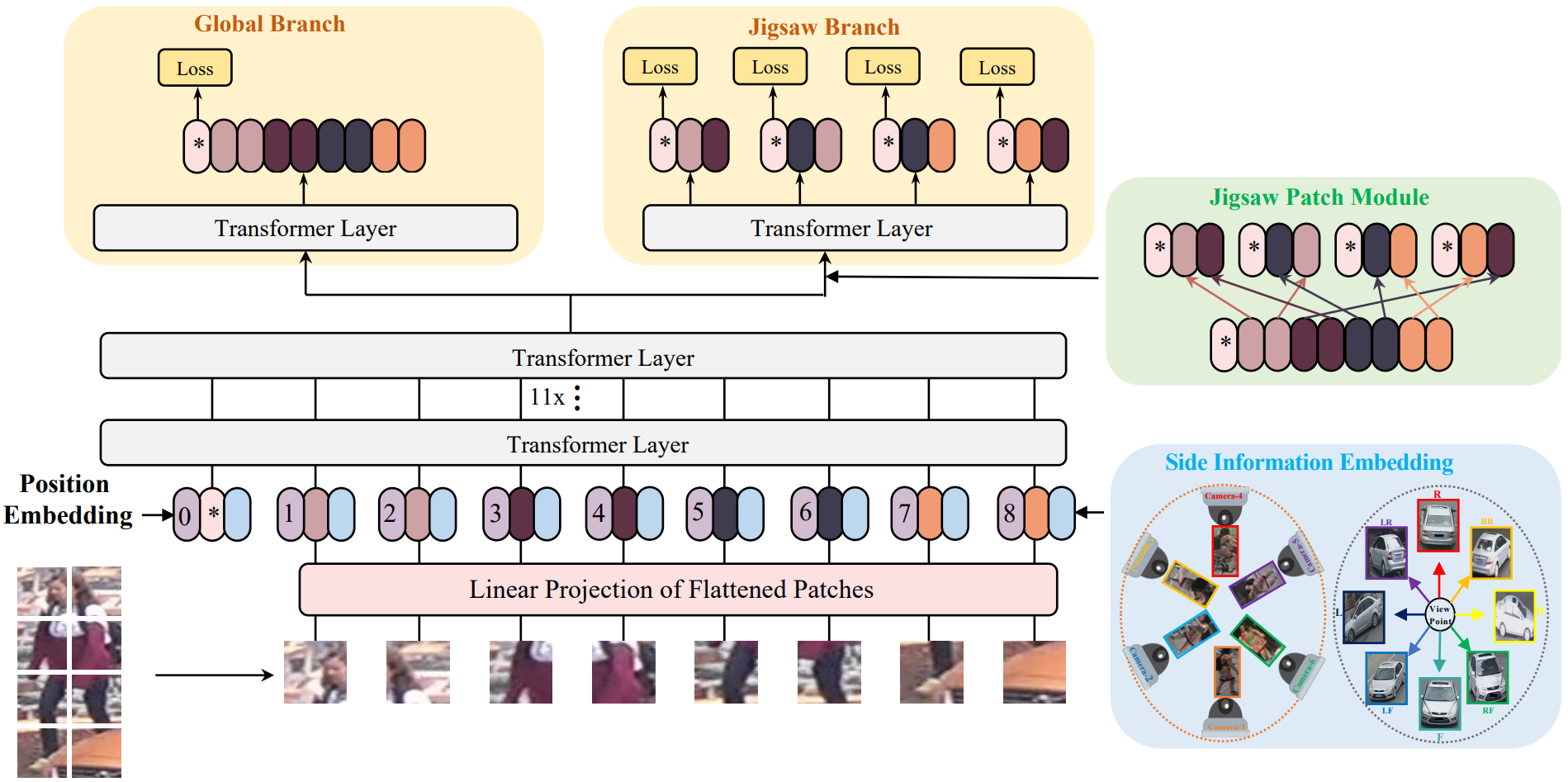
1) Side Information Embedding:
transformer模型可以很好的把side information编码到embedding representation中,对其信息进行结合,且这些embedding是可学习的。若相机编号为 C,则相机embedding为 S(C);若视角标签为 V,则视角embedding为 S(V)。当需要同时使用这两种信息时,采用了联合编码,即 S(C, V)。
第 i 个patch的编码为![]() ,其中
,其中![]() 为特征embedding的线性投影,
为特征embedding的线性投影,![]() 为位置embedding。
为位置embedding。
2) Jigsaw Patch Module:
假设倒数第二层的输出为:![]() 。全局分支采用标准的transformer,得到
。全局分支采用标准的transformer,得到![]()
![]() 。token embedding往往取决其靠近的token,因此一组相近的patch进行embedding会把信息局限在有限的区域。作者采用了JPW模块,其本质是随机分组,具体为:把前 m 个patch挪到后面,再进行patch打乱划分。这里的 k 组patch会输入到同一个transformer结构中,分别提取出一个局部特征。(并不是把一组的patch级联,形成k个大patch,输入一次transformer;而是每组输入一次transformer。)由此得到局部特征
。token embedding往往取决其靠近的token,因此一组相近的patch进行embedding会把信息局限在有限的区域。作者采用了JPW模块,其本质是随机分组,具体为:把前 m 个patch挪到后面,再进行patch打乱划分。这里的 k 组patch会输入到同一个transformer结构中,分别提取出一个局部特征。(并不是把一组的patch级联,形成k个大patch,输入一次transformer;而是每组输入一次transformer。)由此得到局部特征![]() 。
。
最后的损失函数计算为:![]() 。最后将全局特征和局部特征级联,得到最终的特征表示。
。最后将全局特征和局部特征级联,得到最终的特征表示。
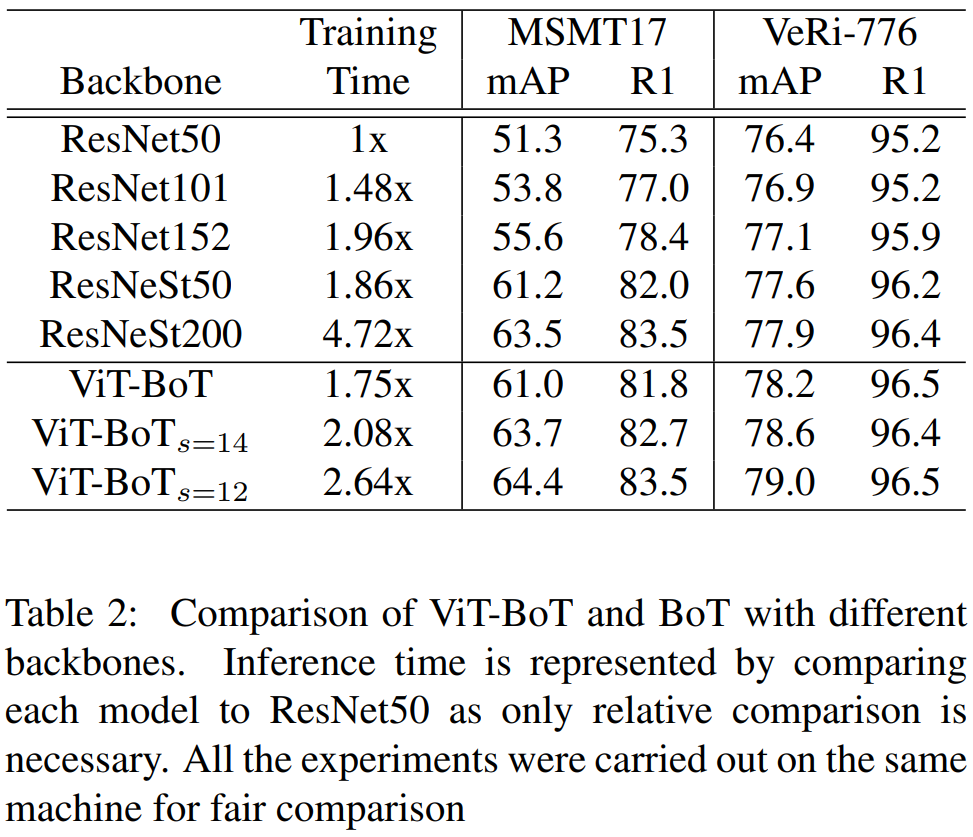
Experiment
数据集:
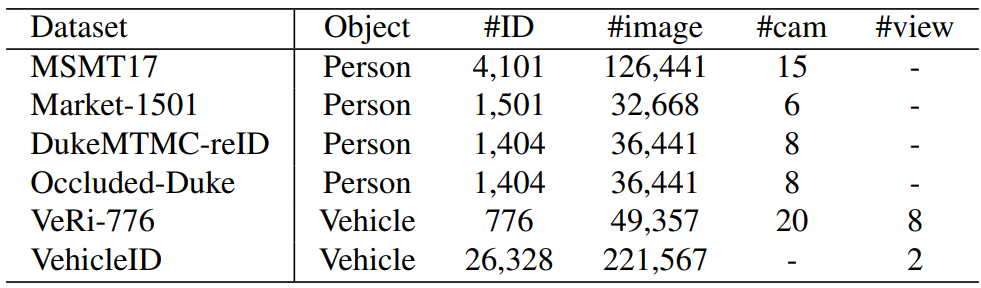
实验结果: