Introduction
作者提出了一个新的跨模态检索框架 Adversarial Cross-Model Retrieval (ACMR),其利用对抗学习来缩小不同模态特征的gap。下图为框架图:
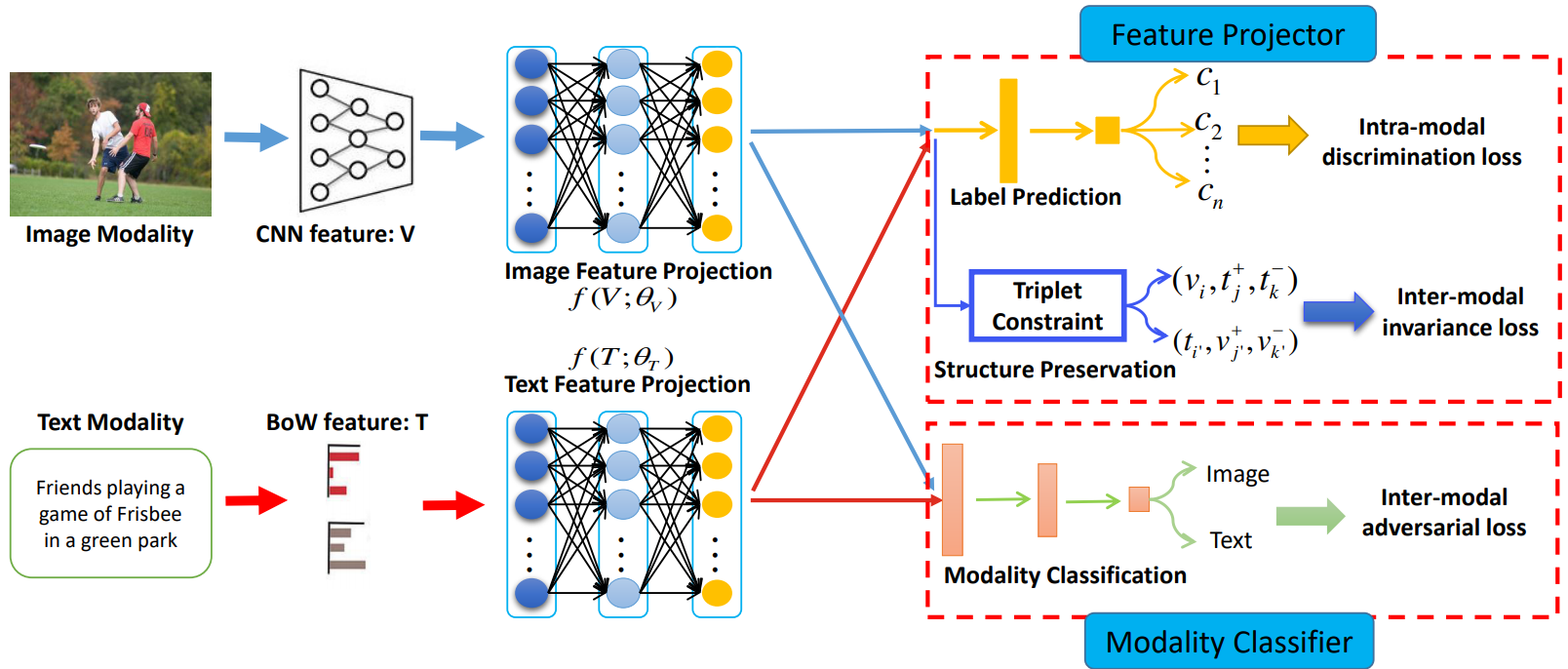
Proposed Method
问题定义:
每对样本的特征定义为:![]() ,每对样本搭配一个语义标签向量
,每对样本搭配一个语义标签向量![]() ,其中 c 为语义类的数量,如果第 i 个样本包含了语义 j,则
,其中 c 为语义类的数量,如果第 i 个样本包含了语义 j,则![]() 。数据包含三个矩阵:图像特征矩阵、文本特征矩阵、语义标签矩阵,即
。数据包含三个矩阵:图像特征矩阵、文本特征矩阵、语义标签矩阵,即![]() ,
,![]() 。
。
由于不同模态的特征有不同的特征分布,因此需要对特征进行投影,使得投影后的特征在相同的特征分布上,即:![]() ,
,![]() 。ACMR方法旨在学习更有效的投影特征,使得不同模态的特征分布更加接近。
。ACMR方法旨在学习更有效的投影特征,使得不同模态的特征分布更加接近。
模态分类器:
模态分类器作为GAN网络的判别器,用于区分特征是来自图像或文本。若来自图像,则分配标签为01;若来自文本,则分配标签10。其设计为3层的卷积网络。对抗损失函数为:
![]()
其中![]() 是每个样本的真实模态标签。
是每个样本的真实模态标签。
特征投影:
特征投影包含两步:标签预测 (label prediction) 以及结构保存 (structure preservation)。
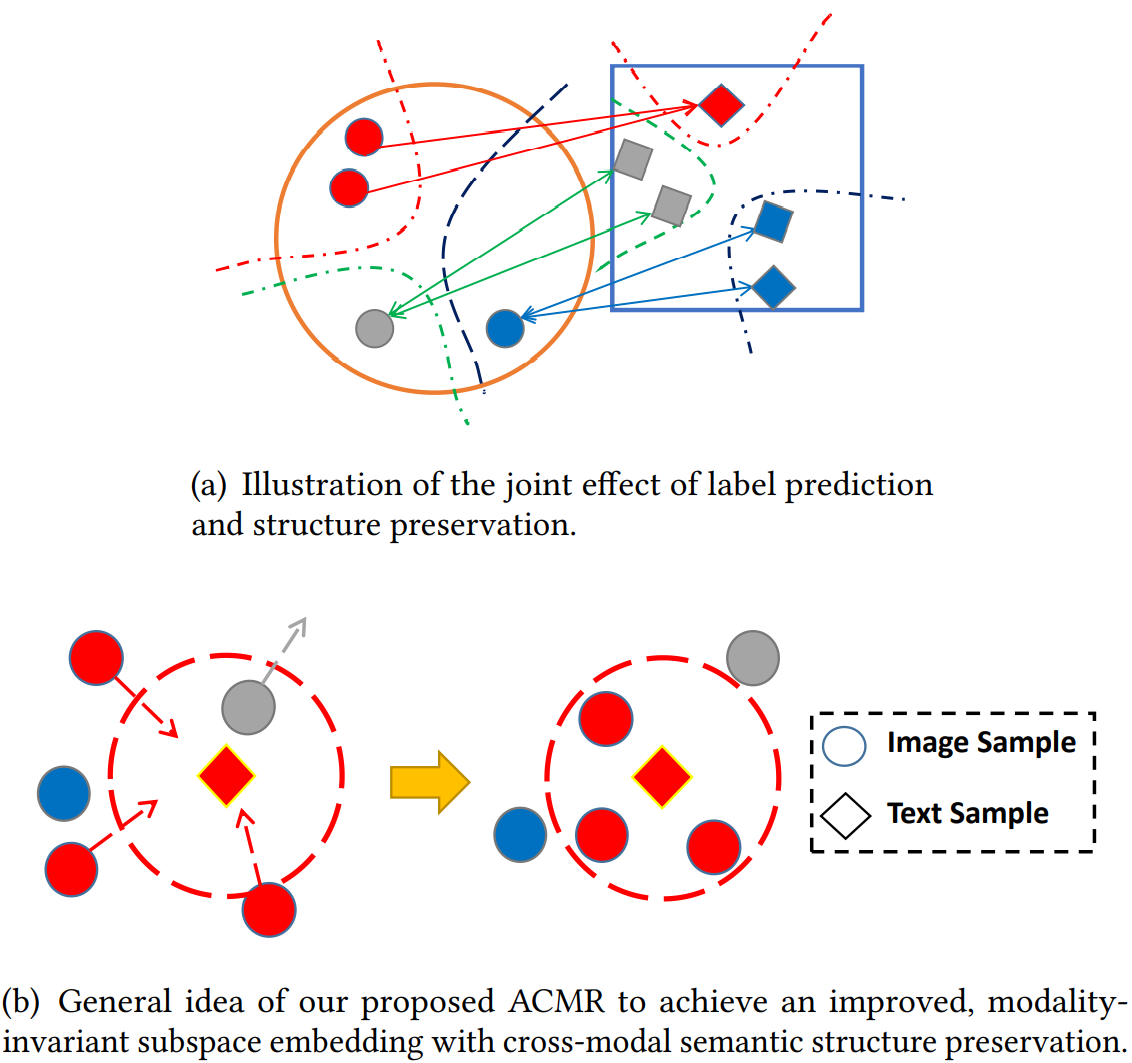
前者确保投影的特征具有对语义标签的判别力(可以理解为:如果是Person ReID,能够对行人的ID进行判别),模态内判别损失函数如下:
![]()
后者确保投影的特征能够适应模态差异,即缩小模态之间的gap。作者基于三元组损失,设计了如下损失:
1) 首先生成同标签不同模态的样本对![]() ,
,![]() 。这里作者没有把所有样本对进行训练 (样本空间为 NxN),而是把所有图像、文本遍历取样 (样本空间为 2xN)。
。这里作者没有把所有样本对进行训练 (样本空间为 NxN),而是把所有图像、文本遍历取样 (样本空间为 2xN)。
2) 采用L2距离,评估跨模态特征差异,即:
![]()
3) 生成三元组样本对![]() ,
,![]() ,计算三元组损失:
,计算三元组损失:
![]()
![]()
4) 模态间损失计算为:
![]()
为了避免过拟合,引入了正则化项,即:
![]()
总结:特征投影损失为:
![]()
对抗训练过程:
minimax策略包含两步:
![]()
![]()
Experiments
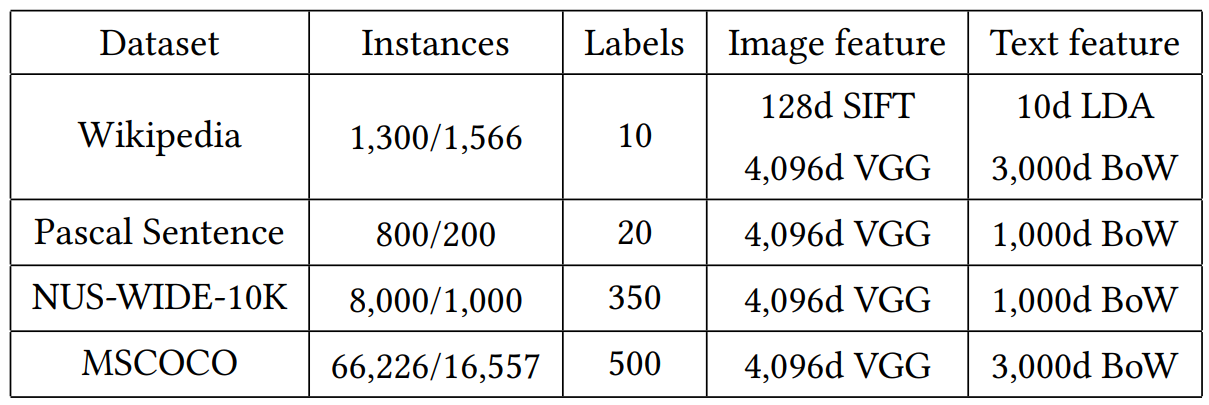
数据集及特征:
实验结果(mAP):

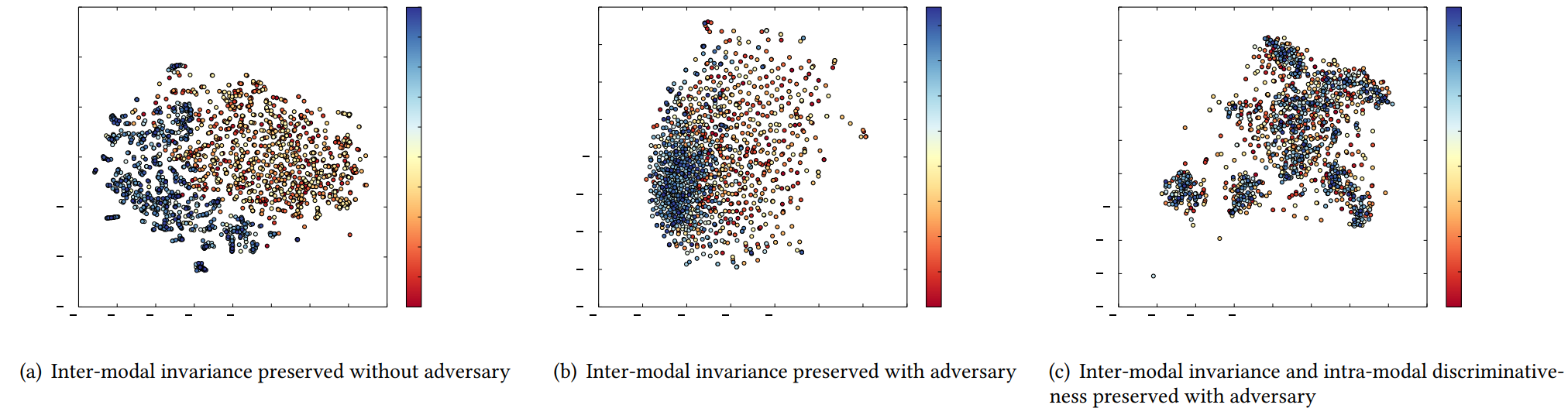
特征分布可视化: