Introduction
(1)Motivation:
相比于全局reid,局部reid存在以下问题:
① 全局reid的空间不对齐主要源于视角姿态变化,但局部reid即时视角姿态相同,依然存在空间不对齐的现象;
② 在局部reid中,不共享的部位将成为噪声,影响模型判断。

(2)Motivation:
提出了visibility-aware part model(VPM)方法解决局部reid问题。该方法首先在全局行人图片上预训练一个识别人体区域的模型。然后定位各个区域,提取区域级的特征。最后计算距离时,先计算区域距离再计算全局距离。
Proposed Method
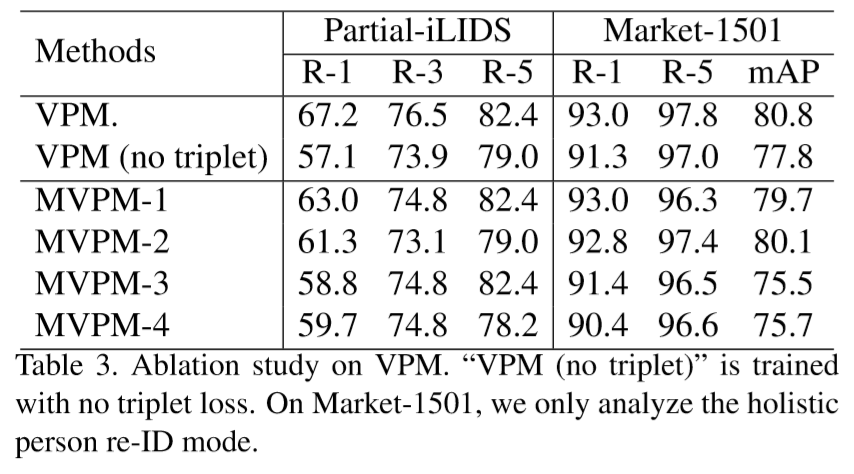
(1)VPM结构:
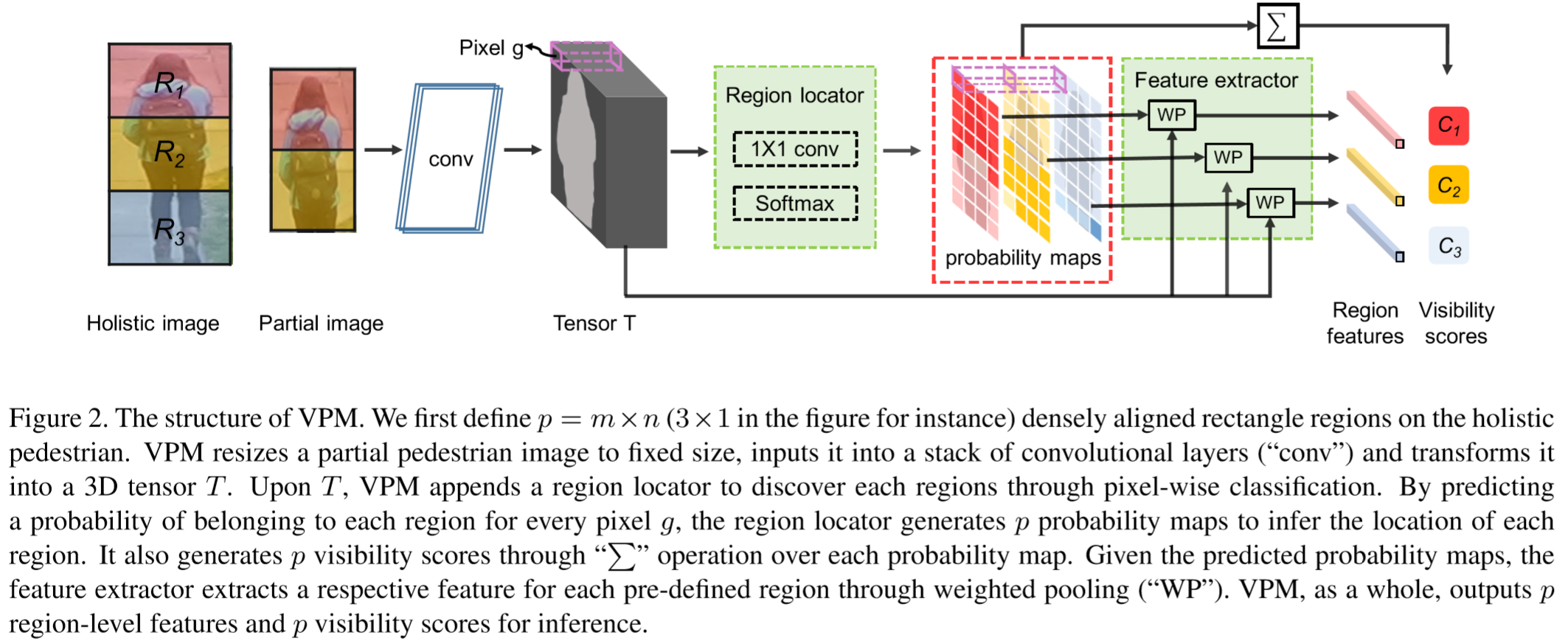
定义图片划分的区域为 p = m * n 个,将图像输入到VPM中,图像的规格为 H * W。首先通过卷积层,卷积层由ResNet-50的所有卷积构成,得到3D张量 T,规格为 c * h * w。将 T 输入到区域定位器中,该定位器采用1*1卷积和softmax函数来判断 T 的每个像素单元 g 所属的区域,计算为:
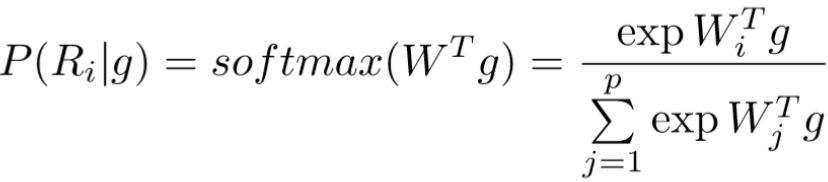
其中![]() 表示 g 属于区域 Ri 的概率,由此得到 p 个概率图,每个图都由 h * w 个像素单元构成。
表示 g 属于区域 Ri 的概率,由此得到 p 个概率图,每个图都由 h * w 个像素单元构成。
区域定位器为每个区域计算可见性得分 C,为:
![]()
如果某个区域的可见性得分较高,那么说明图片中该区域是可见的。
定位后传入区域特征提取器,得到区域的特征为:

(2)VPM的应用:
给定两张图片![]() 和
和![]() ,通过上述过程计算出区域的特征和可见性得分,即
,通过上述过程计算出区域的特征和可见性得分,即![]() 和
和![]() ,则区域间的欧式距离为:
,则区域间的欧式距离为:![]() ,全局距离为:
,全局距离为:
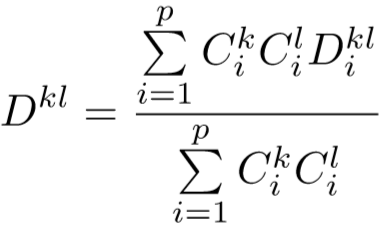
(3)VPM的训练:
VPM的训练包含区域分类器和区域特征提取器的训练。
① 自监督学习:学习区域的可见性感知。给定一个完整的行人图像,随机去除一个区域,再恢复到 H * W 的大小。假设输入的图像左上角和右下角的坐标分别为:![]() 和
和![]() ,对应在张量 T 上的区域为
,对应在张量 T 上的区域为![]() 和
和![]() ,其中 S 为下采样率。
,其中 S 为下采样率。
通过自监督学习,带来以下三个优点:为区域定位器生成了ground true的标签;通过交叉熵损失让VPM关注到可见性区域;通过三元组损失使得VPM关注到共享区域。
② 区域定位器的训练:
采用交叉熵损失,损失函数为:
![]()
其中![]() 只有满足区域 i 等于标签 L 时才为1.
只有满足区域 i 等于标签 L 时才为1.
③ 区域特征提取器的训练:
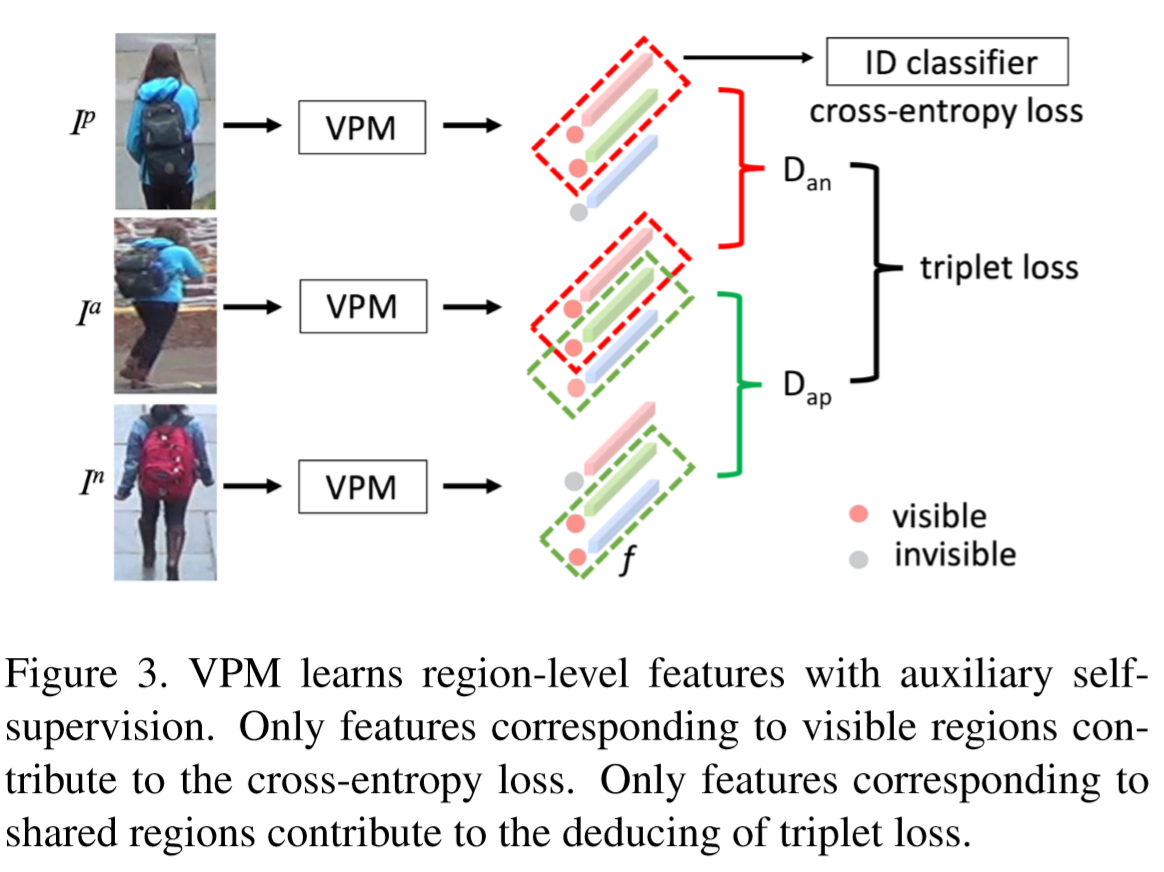
采用交叉熵损失和三元组损失,定义一个ID的分类器为![]() ,对提取到的特征进行ID分类,交叉熵损失为:
,对提取到的特征进行ID分类,交叉熵损失为:
![]()
其中 k 为预测的ID,V为可见区域的集合。
三元组损失为:
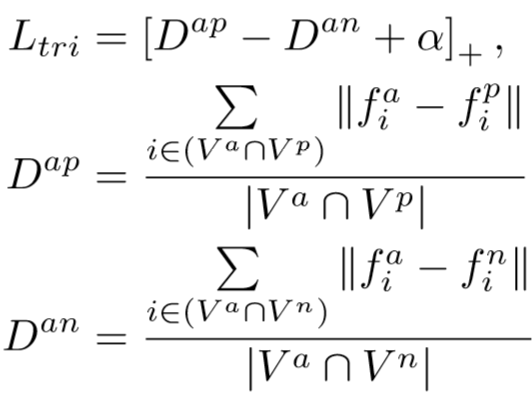
总损失函数为:
![]()
Experiment
(1)实验设置:
① 数据集设置:Market-1501、DukeMTMC-reID、Partial-REID;
② 实验细节:前50次epochs只采用交叉熵损失,后80次加入三元组损失;学习率为0.1,并在30次epochs后下降为0.01;设置随机面积裁剪占比为0.5-1.
(2)实验结果:
① 对比方法:
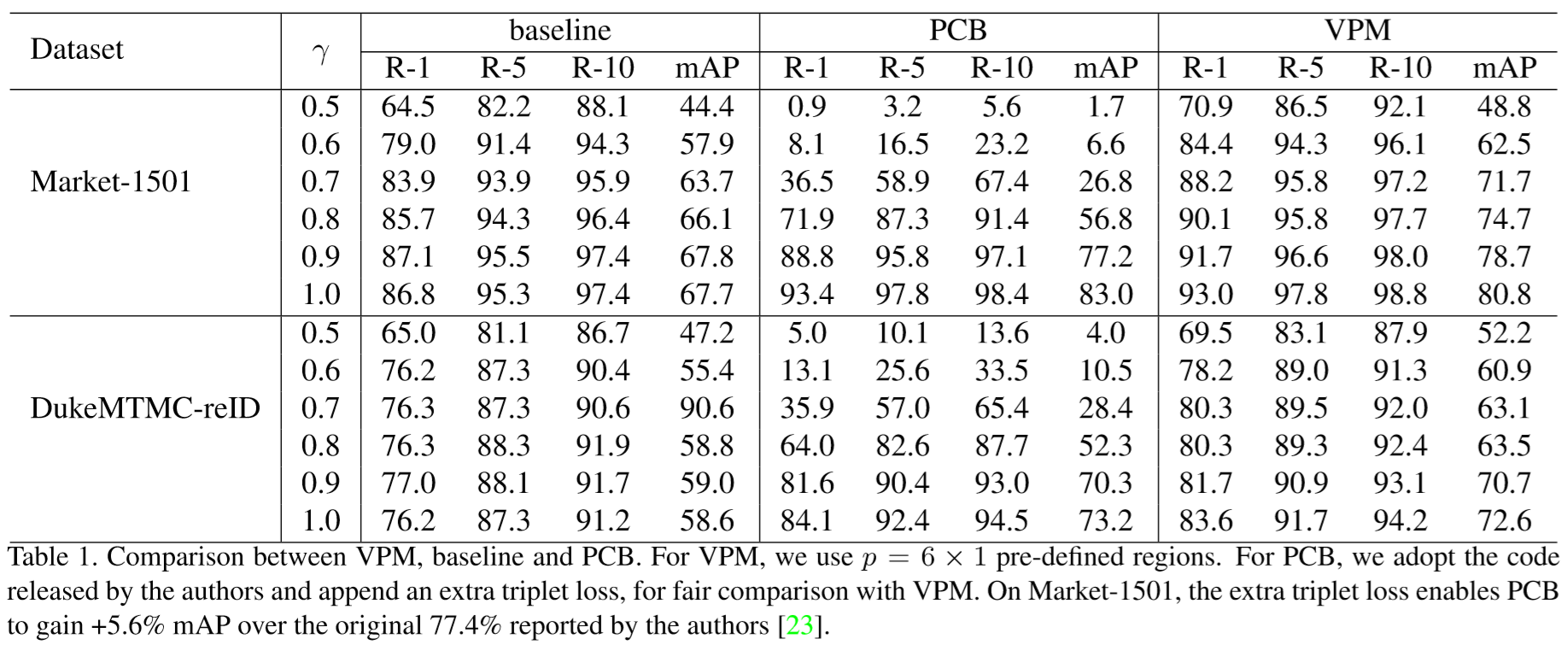
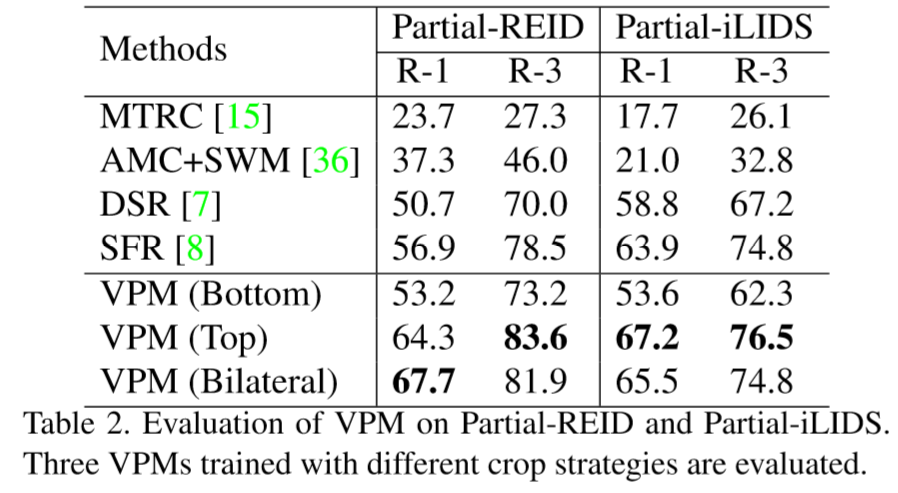
其中:TOP:顶部区域总是可见;Bottom:底部区域总是可见;Bilateral:前面两种结合。
② 自监督方法的变体:
参考知乎【传送门】