进行任何数据分析的第一步:创建包含研究信息的数据集。
在R中这个步骤包括以下两步:
1. 选择一种数据结构来存储数据;
2. 将数据输入或导入到这个数据结构中。
一、 数据集
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
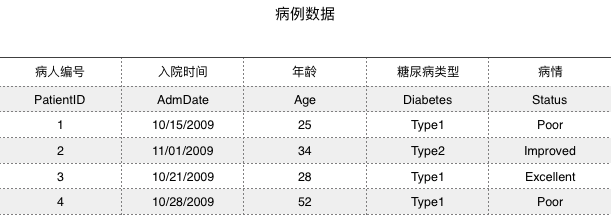
下图是一个假想的病例数据集:
R中的数据结构包括:标量、向量、矩阵、数组、数据框和列表。
上图实际为R中的一个数据框。
R可以处理的数据类型包括:数值类型、字符型、逻辑性(TRUE/FALSE)、复数型(虚数)和原生型(字节)。
上图中 前三列为数值型变量。后两列为字符型变量。
R将实例标识符成为rownames(行名),将类别型(包括名义型和有序型)变量成为因子(factors)。
另外上图中,你需要分别告诉R:PatientID是行/实例标识符;AdmDate是日期型变量;Age是连续型变量;Diabetes是名义型变量;Status是有序型变量。
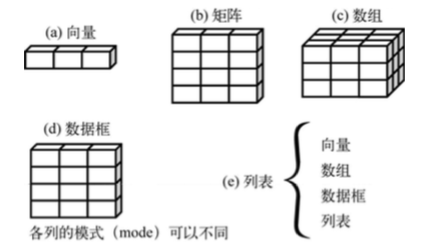
二、 数据结构
R中的数据结构的示意图如下,他们在存储数据的类型、创建方式、结构复杂的,以及用于定位和访问其中个别元素的标记等方面有不同。
声明一些定义:
对象:指可以赋值给变量的任何事物,包括常量、数据结构、函数甚至图形。
模式:对象都拥有某种模式,描述了此对象是如何存储的。
类:对象拥有某个类,像Print这样的泛型函数表明如何处理此对象。
R Studio注释/取消注释的快捷键是: Ctrl + Shift + C.
运行程序快捷键:Command + 回车 (mac)
1. 向量
定义:向量用于存储数值型、字符型或逻辑型数据的一维数组。
创建方式:用函数c()来创建。
eg: a <- (1, 2, 3, -5, 6) 数值型向量
b <- ("one", "two", "three") 字符型向量
c <- (TRUE, TRUE, FALSE, TRUE, FALSE) 逻辑型向量
标量是只含一个元素的向量。 eg: f <- 3、 g <- "US"、 h <- TRUE,他们用于保存常亮。
访问元素:通过在方括号中给定元素所处位置的数值。
eg: a[c(2, 4)] 表示访问向量a中的第二个和第四个元素。
a[2:6] 表示访问a中第二个到第六个元素。
相当于用冒号生成一个数值序列。例如 a <- c(2:6) 等加入 a <- c(2, 3, 4, 5, 6)。 2:6表示数字2-6.

2. 矩阵
定义:矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。即仅能包含一种数据类型。
当维度超过2时,不妨使用数组;当有多种模式的数据时,可以使用数据框。
创建方式:用函数matrix()来创建。
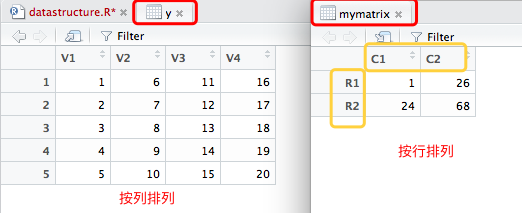
一般使用格式:(可对照下图实例进行理解)
myymatrix <- matrix(vector, nrow=number_of_rows, ncol=number_of_column,
byrow=logical_value, dimnames=list(
char_vector_rownames, char_vector_colnames))
其中vector包含了矩阵的元素,nrow和ncol指行和列的维数,
dimnames包含了可选的、以字符型向量表示的行名和列名。
选项byrow则表明矩阵应当按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认按列填充。
eg:

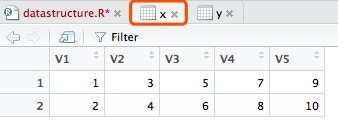
访问元素:可以使用下标和方括号来选择矩阵中的行、列或元素。
X[i, ]指矩阵X中的第i行; X[, j]指第j列; X[i, j]指第i行第j个元素。
选择多行或多列时,下标i和j可为数值型向量。

3. 数组
数组和矩阵类似,但维度可以大于2.
创建形式:myarray <- array(vector, dimensions, dimnames)
vector包含了数组中的数据,dimensions是一个数值型向量,给出了各个维度下标的最大值,dimnames是可选的、各维度名称标签的列表。
数组中的数据也只能拥有一种模式。
从数组中选取元素的方式和矩阵相同: eg. myarray[1,2,3]
下边代码创建了一个三维(2x3x4)数值型数组的示例。直接贴代码和结果吧。结合一起看,会特别直观了。

4. 数据框
定义:不同的列可以包含不同模式(数值型、字符型等)的数据。是最常用的一种数据结构。
创建方式:mydata <- data.frame(col1, col2, col3, ...) 每一列的名称可由函数names指定。
每一列数据的模式必须唯一。
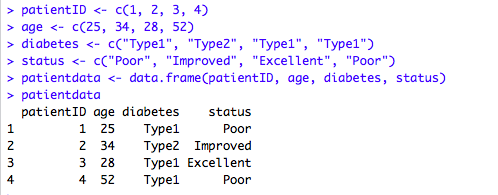
选取数据框中元素的方式,可以用下标,也可指定列名
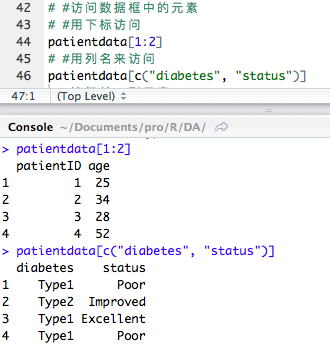
选取数据框中的某个特定变量,用符号 $,eg. 数据框名字$列名
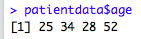
想生成糖尿病类型变量disbetes和病情变量status的列联表用如下代码:
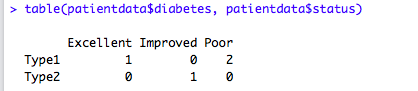
我们可以对照上边patientdata数据框数据,来理解这个联表的意思。其实就是对diabetes和status两列做了个统计。还是挺方便的。
但是每次都需要输入数据框名字和$符号可能会比较麻烦,我们可以使用函数attach()和detach()或者单独使用with()来简化代码。
函数attach()可将数据框添加到R的搜索路径中。R在遇到一个变量名以后,将检查搜索路径中的数据框。
函数detach()将数据框从搜索路径中移除。detach()并不会对数据框本身做任何处理。

但当名称相同的对象不止一个时,这个方法就会出现异常了。
譬如,在数据框patientdata被绑定(attach)之前,我们的环境中已经有了一个名为age的对象,这种情况下,原始对象将取得优先权。所有attach()和detach()最好在我们分析一个单独的数据框并且不太可能有多个同名对象时使用。一定要注意那么被屏蔽(masked)的警告。
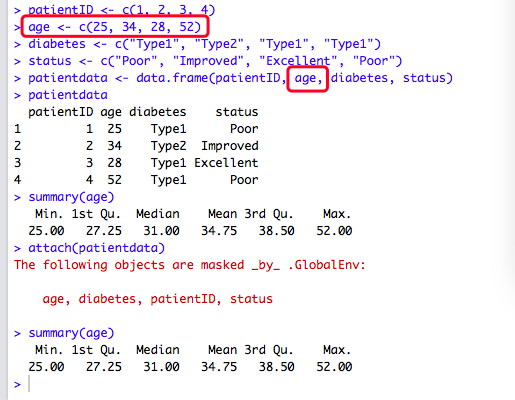
除此之外,另一种方式是使用函数with()。花括号{}之间的语句都是针对patientdata执行,这样就无需担心重名了。如果仅有一条语句,花括号可以省略
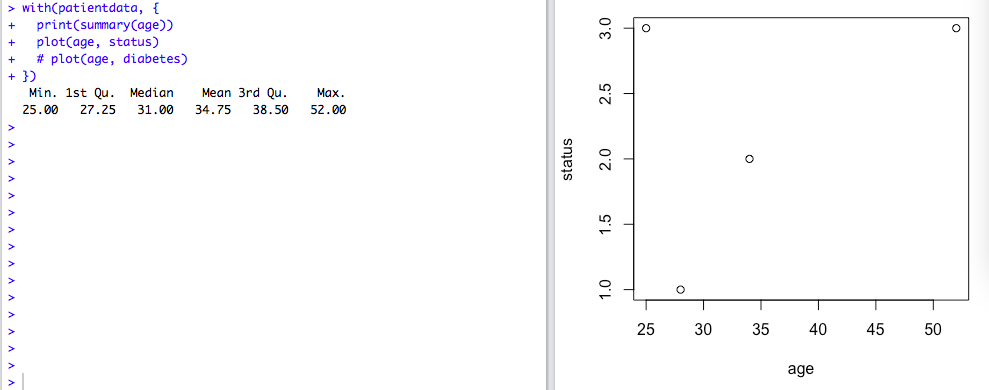
但是函数with()的局限在于,赋值仅在此函数的括号内生效。
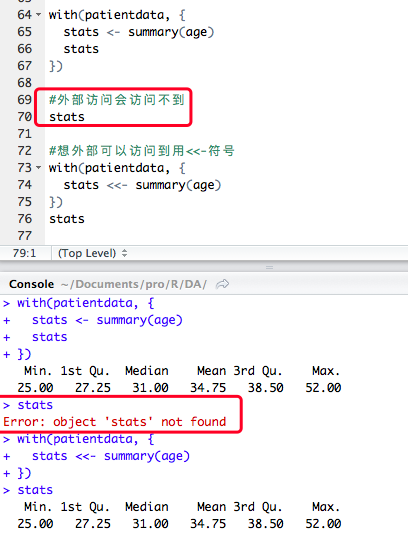
如果想外部也可以访问,使用特殊赋值符 <<- 代替 标准赋值符 <-,他可将对象保存到with()之外的全局变量中。
5. 因子
先说一下变量的分类:名义型变量、有序型变量和连续型变量。
名义型变量是没有顺序的类别变量。eg 糖尿病类型 Diabetes(Tpe1, Type2)。即便Type1 Type2分别编码为1和2,这也并不意味着是有序的。
有序型变量表示一种顺序关系。而非数量关系。eg 病情 Status(poor、improved、excellent)
连续型变量可以表示为某个范围内的任意值,并同时表示顺序和数量。eg 年龄Age
说回来:名义型变量(类别)和有序型变量在R中成为因子(factor)。
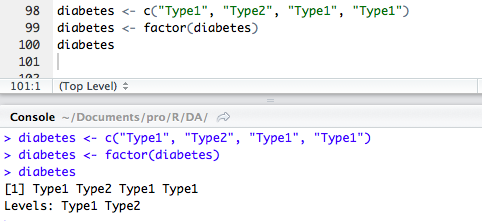
函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1 ... k](k是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
下边 factor(diabetes)将向量存储为(1, 2 , 1 , 1),并在内部关联为1=Type1和2=Type2。
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE.
因子的排序是依照字母顺序创建的。但这样往往不能符合我们心意。比如下边,Poor应该是排在最末位的。
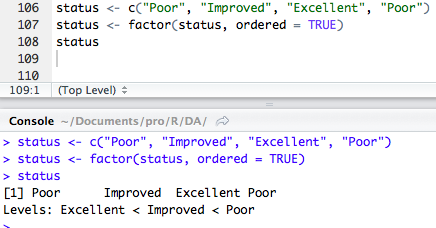
我们可以通过指定levels选项来覆盖默认排序:
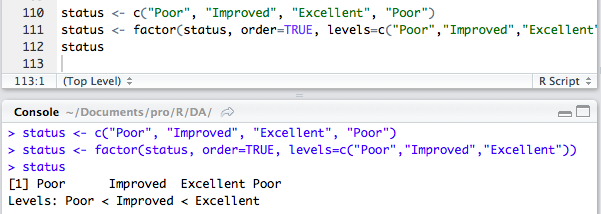
如果指定的水平和数据中的真实值不匹配,那么在数据中出现而未在参数中列出的数据都将被设为缺失值。

数值型变量可以用levels和labels参数来编码成因子。
把变量转换成一个无序因子。标签的顺序必须和水平相一致。在下边例子中,性别被当成类别型变量。用字符串代替数字在结果中的输出,而且所有不是1或者2的性别的变量都将被设置为缺失值。

其实关于因子写了这么多,我顶多懂了百分之五十。下边贴个大例子。
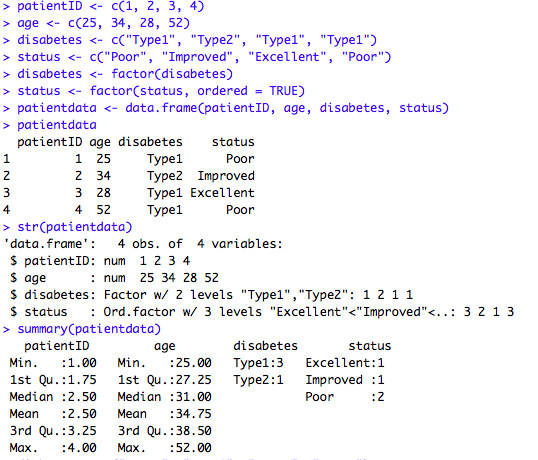
首先以向量的形式输入数据,然后将diabetes和status指定为普通因子和一个有序型因子。最后将数据合并为一个数据框。
函数str(object)可提供R中某个对象的信息。他清楚的显示diabetes是一个因子,而status是一个有序因子。
summary()会区别对待各个变量。他显示了连续型变量age的最小值、最大值、均值和各四分位数,并显示了类别型变量diabetes和status(各水平)的频数值。
:(终于写完这个因子了。抄书一样的觉得哪句话都有用。大部分还是没懂。
6. 列表
列表list是R的数据类型中最为复杂的一种。列表就是一些对象的有序集合。其中对象可以包括若干向量、、矩阵、数据框甚至其他列表组合。
可以使用函数list()创建列表:
mylist <- list(object1, object2, ...)
你还可以为列表中的对象命名:
mylist <- list(name1=object1, name2=object2, ...)
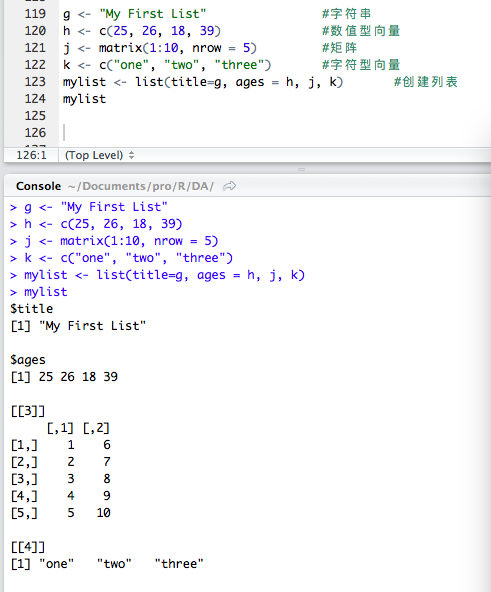
原来list是以逗号分隔为一个元素的。 title=g, ages=h, 只是命名了某一个对象。
访问列表中的元素的三种写法:
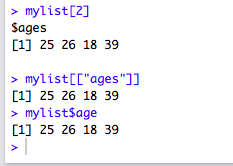
R的下标从1开始!!
这一小节终于看完了。