softmax可以看做只有输入和输出的Neurons Networks,如下图:

其参数数量为k*(n+1) ,但在本实现中没有加入截距项,所以参数为k*n的矩阵。
对损失函数J(θ)的形式有:
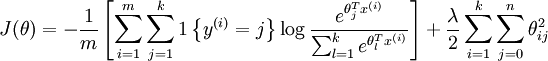
算法步骤:
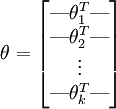
首先,加载数据集{x(1),x(2),x(3)...x(m)}该数据集为一个n*m的矩阵,然后初始化参数 θ ,为一个k*n的矩阵(不考虑截距项):

首先计算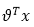 ,该矩阵为k*m的:
,该矩阵为k*m的:

然后计算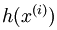 :
:
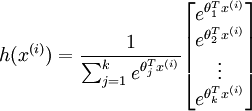
该函数参数可以随意+-任意参数而保持值不变,所以为了防止 参数 过大,先减去一个常量,防止数据运算时产生溢出.
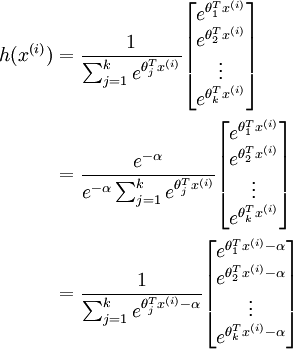
这里减去每一类的最大值,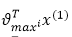 代表第i列最大值。
代表第i列最大值。
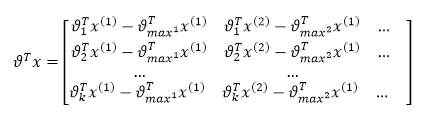
对于上述矩阵,每列除以该列的总和,并且取log即可求得其归一化后的概率,用P来表示,上述矩阵的每一列表示训练数据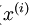 分别属于类别k的概率,每一列的和为1.
分别属于类别k的概率,每一列的和为1.
下面计算Ground Truth 矩阵,该矩阵即代表了损失函数中的: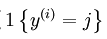 ,Ground Truth 矩阵为k*m的矩阵,每一列代表一个标签,该列中除第k行为1外,其他的元素均为0,k即为该列标签对应的值,比如对于K=4时,的四个样本:
,Ground Truth 矩阵为k*m的矩阵,每一列代表一个标签,该列中除第k行为1外,其他的元素均为0,k即为该列标签对应的值,比如对于K=4时,的四个样本:

上图代表了 ,把上述矩阵扩展为k*m即可。用符号G来表示该矩阵,即可得到下面的cost function:
,把上述矩阵扩展为k*m即可。用符号G来表示该矩阵,即可得到下面的cost function:
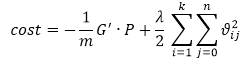
下面需要对损失函数求导,来得到:
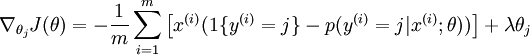
以上公式得到一个k*n的矩阵,每一列即为对参数 的导数。
的导数。

接下来梯度检验,验证上一句的正确性,若正确,则用L-BFGS求解最优解,直接用最优解来进行预测即可。下面是matlab代码:
%% STEP 0: 初始化参数与常量
%
% Here we define and initialise some constants which allow your code
% to be used more generally on any arbitrary input.
% We also initialise some parameters used for tuning the model.
inputSize = 28 * 28; % Size of input vector (MNIST images are 28x28)
numClasses = 10; % Number of classes (MNIST images fall into 10 classes)
lambda = 1e-4; % Weight decay parameter
%%======================================================================
%% STEP 1: Load data
%
% In this section, we load the input and output data.
% For softmax regression on MNIST pixels,
% the input data is the images, and
% the output data is the labels.
%
% Change the filenames if you've saved the files under different names
% On some platforms, the files might be saved as
% train-images.idx3-ubyte / train-labels.idx1-ubyte
images = loadMNISTImages('mnist/train-images-idx3-ubyte');
labels = loadMNISTLabels('mnist/train-labels-idx1-ubyte');
labels(labels==0) = 10; % 注意下标是1-10,所以需要 把0映射到10
inputData = images;
% For debugging purposes, you may wish to reduce the size of the input data
% in order to speed up gradient checking.
% Here, we create synthetic dataset using random data for testing
DEBUG = true; % Set DEBUG to true when debugging.
if DEBUG
inputSize = 8;
inputData = randn(8, 100);%randn产生每个元素均为标准正态分布的8*100的矩阵
labels = randi(10, 100, 1);%产生1-10的随机数,产生100行,即100个标签
end
% Randomly initialise theta
theta = 0.005 * randn(numClasses * inputSize, 1);
%%======================================================================
%% STEP 2: Implement softmaxCost
%
% Implement softmaxCost in softmaxCost.m.
[cost, grad] = softmaxCost(theta, numClasses, inputSize, lambda, inputData, labels);
%%======================================================================
%% STEP 3: Gradient checking
%
% As with any learning algorithm, you should always check that your
% gradients are correct before learning the parameters.
%
% h = @(x) scale * kernel(scale * x);
% 构建一个自变量为x,因变量为h,表达式为scale * kernel(scale * x)的函数。即
% h=scale* kernel(scale * x),自变量为x
if DEBUG
numGrad = computeNumericalGradient( @(x) softmaxCost(x, numClasses, ...
inputSize, lambda, inputData, labels), theta);
% Use this to visually compare the gradients side by side
disp([numGrad grad]);
% Compare numerically computed gradients with those computed analytically
diff = norm(numGrad-grad)/norm(numGrad+grad);
disp(diff);
% The difference should be small.
% In our implementation, these values are usually less than 1e-7.
% When your gradients are correct, congratulations!
end
%%======================================================================
%% STEP 4: Learning parameters
%
% Once you have verified that your gradients are correct,
% you can start training your softmax regression code using softmaxTrain
% (which uses minFunc).
options.maxIter = 100;
softmaxModel = softmaxTrain(inputSize, numClasses, lambda, ...
inputData, labels, options);
% Although we only use 100 iterations here to train a classifier for the
% MNIST data set, in practice, training for more iterations is usually
% beneficial.
%%======================================================================
%% STEP 5: Testing
%
% You should now test your model against the test images.
% To do this, you will first need to write softmaxPredict
% (in softmaxPredict.m), which should return predictions
% given a softmax model and the input data.
images = loadMNISTImages('mnist/t10k-images-idx3-ubyte');
labels = loadMNISTLabels('mnist/t10k-labels-idx1-ubyte');
labels(labels==0) = 10; % Remap 0 to 10
inputData = images;
% You will have to implement softmaxPredict in softmaxPredict.m
[pred] = softmaxPredict(softmaxModel, inputData);
acc = mean(labels(:) == pred(:));
fprintf('Accuracy: %0.3f%%
', acc * 100);
% Accuracy is the proportion of correctly classified images
% After 100 iterations, the results for our implementation were:
%
% Accuracy: 92.200%
%
% If your values are too low (accuracy less than 0.91), you should check
% your code for errors, and make sure you are training on the
% entire data set of 60000 28x28 training images
% (unless you modified the loading code, this should be the case)
end
%%%%对应STEP 2: Implement softmaxCost
function [cost, grad] = softmaxCost(theta, numClasses, inputSize, lambda, data, labels)
% numClasses - the number of classes
% inputSize - the size N of the input vector
% lambda - weight decay parameter
% data - the N x M input matrix, where each column data(:, i) corresponds to
% a single test set
% labels - an M x 1 matrix containing the labels corresponding for the input data
theta = reshape(theta, numClasses, inputSize);% 转化为k*n的参数矩阵
numCases = size(data, 2);%或者data矩阵的列数,即样本数
% M = sparse(r, c, v) creates a sparse matrix such that M(r(i), c(i)) = v(i) for all i.
% That is, the vectors r and c give the position of the elements whose values we wish
% to set, and v the corresponding values of the elements
% labels = (1,3,4,10 ...)^T
% 1:numCases=(1,2,3,4...M)^T
% sparse(labels, 1:numCases, 1) 会产生
% 一个行列为下标的稀疏矩阵
% (1,1) 1
% (3,2) 1
% (4,3) 1
% (10,4) 1
%这样改矩阵填满后会变成每一列只有一个元素为1,该元素的行即为其lable k
%1 0 0 ...
%0 0 0 ...
%0 1 0 ...
%0 0 1 ...
%0 0 0 ...
%. . .
%上矩阵为10*M的 ,即 groundTruth 矩阵
groundTruth = full(sparse(labels, 1:numCases, 1));
cost = 0;
% 每个参数的偏导数矩阵
thetagrad = zeros(numClasses, inputSize);
% theta(k*n) data(n*m)
%theta * data = k*m , 第j行第i列为theta_j^T * x^(i)
%max(M)产生一个行向量,每个元素为该列中的最大值,即对上述k*m的矩阵找出m列中每列的最大值
M = bsxfun(@minus,theta*data,max(theta*data, [], 1)); % 每列元素均减去该列的最大值,见图-
M = exp(M); %求指数
p = bsxfun(@rdivide, M, sum(M)); %sum(M),对M中的元素按列求和
cost = -1/numCases * groundTruth(:)' * log(p(:)) + lambda/2 * sum(theta(:) .^ 2);%损失函数值
%groundTruth 为k*m ,data'为m*n,即theta为k*n的矩阵,n代表输入的维度,k代表类别,即没有隐层的
%输入为n,输出为k的神经网络
thetagrad = -1/numCases * (groundTruth - p) * data' + lambda * theta; %梯度,为 k *
% ------------------------------------------------------------------
% Unroll the gradient matrices into a vector for minFunc
grad = [thetagrad(:)];
end
%%%%对应STEP 3: Implement softmaxCost
% 函数的实际参数是这样的J = @(x) softmaxCost(x, numClasses, inputSize, lambda, inputData, labels)
% 即函数的形式参数J以x为自变量,别的都是以默认的值为相应的变量
function numgrad = computeNumericalGradient(J, theta)
% theta: 参数,向量或者实数均可
% J: 输出值为实数的函数. 调用y = J(theta)将会返回函数在theta处的值
% numgrad初始化为0,与theta维度相同
numgrad = zeros(size(theta));
EPSILON = 1e-4;
% theta是一个行向量,size(theta,1)是求行数
n = size(theta,1);
%产生一个维度为n的单位矩阵
E = eye(n);
for i = 1:n
% (n,:)代表第n行,所有的列
% (:,n)代表所有行,第n列
% 由于E是单位矩阵,所以只有第i行第i列的元素变为EPSILON
delta = E(:,i)*EPSILON;
%向量第i维度的值
numgrad(i) = (J(theta+delta)-J(theta-delta))/(EPSILON*2.0);
end
%%%%对应STEP 4: Implement softmaxCost
function [softmaxModel] = softmaxTrain(inputSize, numClasses, lambda, inputData, labels, options)
%softmaxTrain Train a softmax model with the given parameters on the given
% data. Returns softmaxOptTheta, a vector containing the trained parameters
% for the model.
%
% inputSize: the size of an input vector x^(i)
% numClasses: the number of classes
% lambda: weight decay parameter
% inputData: an N by M matrix containing the input data, such that
% inputData(:, i) is the ith input
% labels: M by 1 matrix containing the class labels for the
% corresponding inputs. labels(c) is the class label for
% the cth input
% options (optional): options
% options.maxIter: number of iterations to train for
if ~exist('options', 'var')
options = struct;
end
if ~isfield(options, 'maxIter')
options.maxIter = 400;
end
% initialize parameters,randn(M,1)产生均值为0,方差为1长度为M的数组
theta = 0.005 * randn(numClasses * inputSize, 1);
% Use minFunc to minimize the function
addpath minFunc/
options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
% function. Generally, for minFunc to work, you
% need a function pointer with two outputs: the
% function value and the gradient. In our problem,
% softmaxCost.m satisfies this.
minFuncOptions.display = 'on';
[softmaxOptTheta, cost] = minFunc( @(p) softmaxCost(p, ...
numClasses, inputSize, lambda, ...
inputData, labels), ...
theta, options);
% Fold softmaxOptTheta into a nicer format
softmaxModel.optTheta = reshape(softmaxOptTheta, numClasses, inputSize);
softmaxModel.inputSize = inputSize;
softmaxModel.numClasses = numClasses;
end
%%%%对应 STEP 5: Implement predict
function [pred] = softmaxPredict(softmaxModel, data)
% softmaxModel - model trained using softmaxTrain
% data - the N x M input matrix, where each column data(:, i) corresponds to
% a single test set
%
% Your code should produce the prediction matrix
% pred, where pred(i) is argmax_c P(y(c) | x(i)).
% Unroll the parameters from theta
theta = softmaxModel.optTheta; % this provides a numClasses x inputSize matrix
pred = zeros(1, size(data, 2));
%C = max(A)
%返回一个数组各不同维中的最大元素。
%如果A是一个向量,max(A)返回A中的最大元素。
%如果A是一个矩阵,max(A)将A的每一列作为一个向量,返回一行向量包含了每一列的最大元素。
%根据预测函数找出每列的最大值即可。
[nop, pred] = max(theta * data);
end