版本(5.0)
MyISAM和InnoDB存储引擎的表默认创建的都是BTREE索引。MySQL目前还不支持函数索引,但是支持前缀索引,即对索引字段的前N个字符创建索引。前缀索引的长度跟存储引擎相关,对于MyISAM存储引擎的表,索引的前缀长度可以达到1000字节长,而对于InnoDB存储引擎的表,索引的前缀长度最长是767字节。请注意前缀的限制应以字节为单位进行测量,而CREATE TABLE语句中的前缀长度解释为字符数。
MySQL 中还支持全文本(FULLTEXT)索引,该索引可以用于全文搜索。但是版本(5.0)中只有MyISAM存储引擎支持FULLTEXT索引,并且只限于CHAR、VARCHAR和TEXT列。索引总是对整个列进行的,不支持局部(前缀)索引。
设计索引的原则
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用效率,更高效地使用索引。
1.搜索的索引列,不一定是所要选择的列。换句话说,最适合索引的列是出现在WHERE子句中的列,或连接子句中指定的列,而不是出现在SELECT关键字后的选择列表中的列。
2.使用唯一索引。考虑某列中值的分布。索引的列的基数越大,索引的效果越好。例如,存放出生日期的列具有不同值,很容易区分各行。而用来记录性别的列,只含有“M”和“F”,则对此列进行索引没有多大用处,因为不管搜索哪个值,都会得出大约一半的行。
3.使用短索引。如果对字符串列进行索引,应该指定一个前缀长度,只要有可能就应该这样做。例如,有一个CHAR(200)列,如果在前10个或20个字符内,多数值是唯一的,那么就不要对整个列进行索引。对前10个或20个字符进行索引能够节省大量索引空间,也可能会使查询更快。较小的索引涉及的磁盘 IO 较少,较短的值比较起来更快。更为重要的是,对于较短的键值,索引高速缓存中的块能容纳更多的键值,因此,MySQL 也可以在内存中容纳更多的值。这样就增加了找到行而不用读取索引中较多块的可能性。
4.利用最左前缀。在创建一个n列的索引时,实际是创建了MySQL可利用的n个索引。多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。这样的列集称为最左前缀。
5.不要过度索引。不要以为索引“越多越好”,什么东西都用索引是错误的。每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能。在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,索引越多,所花的时间越长。如果有一个索引很少利用或从不使用,那么会不必要地减缓表的修改速度。此外,MySQL 在生成一个执行计划时,要考虑各个索引,这也要花费时间。创建多余的索引给查询优化带来了更多的工作。索引太多,也可能会使MySQL选择不到所要使用的最好索引。只保持所需的索引有利于查询优化。
6.对于InnoDB存储引擎的表,记录默认会按照一定的顺序保存,如果有明确定义的主键,则按照主键顺序保存。如果没有主键,但是有唯一索引,那么就是按照唯一索引的顺序保存。如果既没有主键又没有唯一索引,那么表中会自动生成一个内部列,按照这个列的顺序保存。按照主键或者内部列进行的访问是最快的,所以InnoDB表尽量自己指定主键,当表中同时有几个列都是唯一的,都可以作为主键的时候,要选择最常作为访问条件的列作为主键,提高查询的效率。另外,还需要注意,InnoDB 表的普通索引都会保存主键的键值,所以主键要尽可能选择较短的数据类型,可以有效地减少索引的磁盘占用,提高索引的缓存效果。
BTREE索引与HASH索引
HASH索引有一些重要的特征需要在使用的时候特别注意,如下所示。
1.只用于使用=或<=>操作符的等式比较。
2.优化器不能使用HASH索引来加速ORDER BY操作。
3.MySQL 不能确定在两个值之间大约有多少行。如果将一个 MyISAM 表改为 HASH索引的MEMORY表,会影响一些查询的执行效率。
4.只能使用整个关键字来搜索一行。
而对于BTREE索引,当使用>、<、>=、<=、BETWEEN、!=或者<>,或者LIKE 'pattern' (其中'pattern'不以通配符开始)操作符时,都可以使用相关列上的索引。
更多内容:深入浅出MySQL-10章
MySQL中能够使用索引的典型场景
(1)匹配全值(Match the full value),对索引中所有列都指定具体值,即是对索引中的所有列都有等值匹配的条件。
EXPLAIN SELECT * FROM rental WHERE rental_date = '2005-05-25 17:22:10' AND inventory_id = 373 AND customer_id = 343
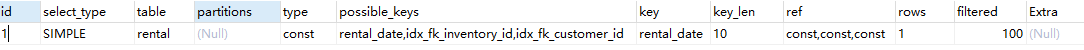
explain输出结果中字段type的值为const,表示是常量;字段key的值为idx_rental_date,表示优化器选择索引idx_rental_date进行扫描。
(2)匹配值的范围查询(Match a range of values),对索引的值能够进行范围查找。
EXPLAIN SELECT * FROM rental WHERE customer_id >= 373 AND customer_id < 400

类型type为range说明优化器选择范围查询,索引key为idx_fk_customer_id说明优化器选择索引idx_fk_customer_id来加速访问,注意到这个例子中Extra列为Using where,表示优化器除了利用索引来加速访问之外,还需要根据索引回表查询数据。
(3)匹配最左前缀(Match a leftmost prefix),仅仅使用索引中的最左边列进行查找
KEY `idx_payment_date` (`payment_date`,`amount`,`last_update`),
EXPLAIN SELECT * FROM payment WHERE payment_date = '2006-02-14 15:16:03' AND last_update = '2006-02-15 22:12:32'

但是,如果仅仅选择复合索引 idx_payment_date 的第二列支付金额 amount 和第三列更新时间last_update进行查询时,那么执行计划显示并不会利用到索引idx_payment_date
EXPLAIN SELECT * FROM payment WHERE amount = 3.98 AND last_update = '2006-02-1522:12:32'

最左匹配原则可以算是MySQL中B-Tree索引使用的首要原则。
(4)仅仅对索引进行查询(Index only query),当查询的列都在索引的字段中时,查询的效率更高;
对比上一个例子使用Select *,本次选择查询的字段都包含在索引 idx_payment_date中时,能够看到查询计划有了一点变动:
EXPLAIN SELECT last_update FROM payment WHERE amount = 3.98 AND last_update = '2006-02-1522:12:32'

Extra部分变成了Using index,也就意味着,现在直接访问索引就足够获取到所需要的数据,不需要通过索引回表,Using index也就是平常说的覆盖索引扫描。只访问必须访问的数据,在一般情况下,减少不必要的数据访问能够提升效率。
(5)匹配列前缀(Match a column prefix),仅仅使用索引中的第一列,并且只包含索引第一列的开头一部分进行查找。
create index idx_title_desc_part on film_text (title(10), description(20)); KEY `idx_title_desc_part` (`title`(10),`description`(20))
EXPLAIN SELECT title FROM film_text WHERE title LIKE 'AFRICAN%'

Extra值为Using where表示优化器需要通过索引回表查询数据。
(6)能够实现索引匹配部分精确而其他部分进行范围匹配
EXPLAIN SELECT inventory_id FROM rental WHERE rental_date = '2006-02-14 15:16:03' AND customer_id >= 300 AND customer_id <= 400

类型type为range说明优化器选择范围查询,索引key为idx_rental_date说明优化器选择索引idx_rental_date帮助加速查询,同时由于只查询索引字段inventory_id的值,所以在Extra部分能看到Using index,表示查询使用了覆盖索引扫描。
(7)如果列名是索引,那么使用 column_name is null就会使用索引
EXPLAIN SELECT * FROM payment WHERE rental_id IS NULL
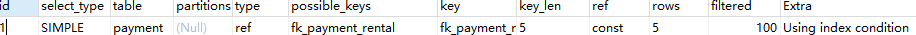
存在索引但不能使用索引的典型场景
(1)以%开头的LIKE查询不能够利用B-Tree索引,执行计划中key的值为NULL表示没有使用索引
EXPLAIN SELECT * FROM actor WHERE last_name LIKE '%NI%'

因为B-Tree索引的结构,所以以%开头的查询很自然就没法利用索引了,一般都推荐使用全文索引(Fulltext)来解决类似的全文检索问题。或者考虑利用 InnoDB 的表都是聚簇表的特点,采取一种轻量级别的解决方式:一般情况下,索引都会比表小,扫描索引要比扫描表更快(某些特殊情况下,索引比表更大,不在本例讨论范围内),而InnoDB表上二级索引idx_last_name实际上存储字段last_name还有主键actor_id,那么理想的访问方式应该是首先扫描二级索引 idx_last_name获得满足条件 last_name like '%NI%'的主键 actor_id列表,之后根据主键回表去检索记录,这样访问避开了全表扫描演员表actor产生的大量IO请求。验证一下:
EXPLAIN SELECT * FROM ( SELECT actor_id FROM actor WHERE last_name LIKE '%NI%' ) a, actor b WHERE a.actor_id = b.actor_id

从执行计划中能够看到,内层查询的 Using index代表索引覆盖扫描,之后通过主键 join操作去演员表actor中获取最终查询结果,理论上是能够比直接全表扫描更快一些。
(2)数据类型出现隐式转换的时候也不会使用索引,特别是当列类型是字符串,那么一定记得在where 条件中把字符常量值用引号引起来,否则即便这个列上有索引,MySQL 也不会用到,因为MySQL默认把输入的常量值进行转换以后才进行检索。
EXPLAIN SELECT * FROM actor WHERE last_name = 1

加上引号之后,再次检查执行计划,就发现使用上索引了:
EXPLAIN SELECT * FROM actor WHERE last_name = '1'

(3)复合索引的情况下,假如查询条件不包含索引列最左边部分,即不满足最左原则Leftmost,是不会使用复合索引的
EXPLAIN SELECT * FROM payment WHERE amount = 3.98 AND last_update = '2006-02-1522:12:32'

(4)如果 MySQL 估计使用索引比全表扫描更慢,则不使用索引。
更多内容:深入浅出MySQL-18.2.2
(5)用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到
EXPLAIN SELECT * FROM payment WHERE customer_id = 203 OR amount = 3.96

因为 or 后面的条件列中没有索引,那么后面的查询肯定要走全表扫描,在存在全表扫描的情况下,就没有必要多一次索引扫描增加I/O访问,一次全表扫描过滤条件就足够了。