第六章 内核机制
这章我们讨论Windows内核提供的各种机制。这些中的一部分对驱动开发者有直接的用处。其他的是一些驱动开发者需要理解的机制,这将帮你调试和大体理解系统的活动。
在这章中:
- 中断请求等级
- 延迟调用过程(DPC)
- 同步调用过程(APC)
- 结构化异常处理
- 系统崩溃
- 线程同步
- 高IRQL同步
- 工程项目(Work Items)
中断请求等级
在第一章中,我们讨论了线程和线程的优先级。当更多的线程线程多于可用的处理器时,则考虑这个优先级。在同一时间,硬件设备需要通知系统需要注意的。一个简单的例子就是由磁盘驱动执行的I/O操作。一旦这个操作被完成,这磁盘驱动通过发送一个中断来通知完成。这个中断是与一个硬件中断控制器相连接,其发送给处理器来处理。下一个问题是,哪个线程将执行相关的中断服务例程呢?(ISR)
每一个硬件中断都与一个优先级相关联,称为硬件终端请求级别(IRQL)(不要与中断物理行IRQ混淆),其由HAL所决定,每一个处理器都有它各自的IRQL的上下文,就想全部寄存器一样。IRQLs可能由CPU硬件执行,也可能不执行,但那时不重要的。IRQL应该就像其他的CPU寄存器一样被对待。
基本的规则是CPU执行有着IRQL最高级别的代码。例如,一个CPU的IRQL此时为零,一个IRQL5的中断进来,它将保存它的状态(上下文)在当前内核线程栈中,然后将它的IRQL提升到5之后执行与中断相关的中断服务例程。一旦中断服务例程完成,这个IRQL将降会其先前模式,就好像这个中断不存在一样。当中断服务例程执行时,其他低于5的IRQL进来将不会打断处理器。如果,另一方面,这个高于5的IRQL进来,这个CPU将会再一次保存这个当前状态,将IRQL提升一个新的级别,执行这个与第二个中断相关的第二个中断服务例程。当其完成的时候,将降回IRQL5,恢复它的状态继续执行原来的中断服务例程。本质上,使用相同或更低的IRQL来临时的提高IRQL代码块。当一个中断发生时其事件序列如图6-1所示。图6-2展示了嵌套中断是什么样子。

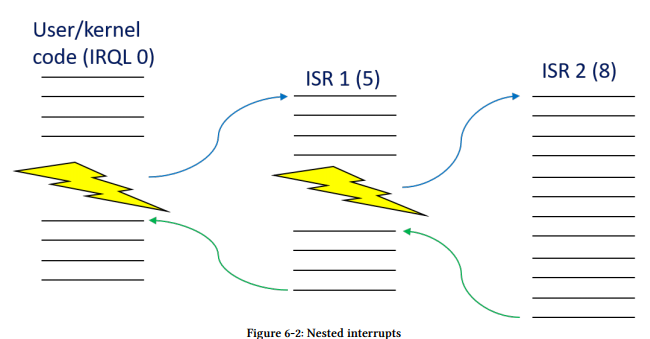
对于图6-1和图6-2中描述的场景,一个重要的事实是,所有ISRs的执行都是由同一个线程完成的,而这个线程在一开始就被中断了。Windows并没有一个特别的线程来处理中断;他们将被任何在同一时间运行在中断的处理器上的线程来处理。我们不久之后会发现,当处理器是2或更高级别时,上下文切换是不可能发生的,因此当中断服务例程执行时,另一个线程是没有办法潜入的。
中断的线程不会因为这些中断而减少它的量子数。可以这么说,这不是它的错。
当用户模式的代码执行时,这个IRQL级别总是为零。这就是IRQL不在用户文档中提及的原因 - 它总是令并且不可能改变。大多数内核模式的代码也是使用IRQL0的级别运行。这是可能的,在内核模式中,可以提升IRQL在当前的处理器上。
IRQLs有如下重要的描述:
- PASSIVE_LEVEL在WDK(0) - 这是一个CPU正常的IRQL。用户模式代码总是运行在这个级别上。线程切换可以被正常运行,如第一章所描述的。
- APC_LEVEL(1) - 被用来执行内核APCs(异步过程调用,我们将在这章的后面来讨论它)。线程调度工作可以正常执行。
- DISPATCH_LEVEL(2) - 存在一些激进的改变。这个调度无法唤醒CPU。内存页不允许被访问 - 这种访问会造成一个系统崩溃。因为调度器无法干预,不允许等待任何内核对象(否则会造成一个系统崩溃)。
- Device IRQL - 一系列由硬件中断使用的等级(3到11在x64/ARM/ARM64,3到26在x86上)。所有的规则与IRQL2一样。
- 最高等级(HIGH_LEVEL) - 这是最高的IRQL等级,屏蔽掉全部的中断,用于处理一些链表操作的Apis。这实际值是15(x64/ARM/ARM64)和31(x86)。
当一个处理器的IRQL提高到2或更高时(不论任何理由),正在执行的代码都会收到这些限制:
- 访问任何不在物理内存的内存将会是指明的,造成一个系统崩溃。这意味着访问非分页内存的数据总是安全的,同样访问分页内存中的数据和用户提供的缓冲区是不安全并且应该避免的。
- 等待任何调度内核对象(mutex或event)会造成一个系统崩溃,除非等待超时时间为0,这总是允许的。(我们将在之后的章节中讨论派发内核对象和等待在这章的“同步”部分)
这些限制是基于调度器运行在IRQL2上,因此如果一个处理的IRQL早已经是2或者更高的等级,这个调度器无法唤醒这个处理器,因此上下文切换(在CPU上替换一个正在运行的线程到另一个)将不会发生。只有更高级别的中断暂时地将代码转换为中断处理例程,但是这仍然是同一个线程 - 并没有上下文切换会发生;这线程环境被保存,这个中断处理例程执行,这个线程状态恢复
一个处理的当前IRQL级别可以使用debug !irql 命令来查看。如果选择指定的CPU数,这将会展示这个CPU的IRQL。
你可以使用!idt调试器指令来查看一个系统中注册的中断。
提高或降低IRQL
我们之前将会,在用户模式中没有提到IRQL这个概念,没有任何方法来改变它。在内核模式中,这个IRQL可以使用KeRaiseIrql函数来提高,使用KeLowerIrql来降低。这里有一个将IRQL提上到DISPATCH_LEVEL(2)之后执行降低回原来的IRQL的代码片段。

如果你提升IRQL,确保在同一个函数运行它。使用一个高IRQL从一个函数中返回而不进入是非常危险的。当然,确保使用KeRaiseIrql确实提升IRQL并且调用KeLowerIrql来降低它。否则,一个系统冲突就会发生。
线程优先级 vs. IRQLS
IRQL是一个处理器实行,线程优先级是一个线程属性。线程优先及只有在IRQL < 2 时才会有意义。一旦执行线程将IRQL提高到2或者更高,这个优先级将没有任何意义 - 理论上这是一个无线量 - 这将继续执行找到将IRQL降到2以下。
通常来说,在IRQL>=2花费太多时间并不是一个好事情;用户模式代码并不能运行。这只是在这些级别上对执行代码有严格限制的原因之一。
任务管理器展示了运行在IRQL2或更高上的CPU花费的总时间,使用一个称为System Interrupts的伪进程。任务管理器称他为Interrupts。图6-3展示了任务管理器的一个屏幕截图,图6-4展示了Process Explorer中的相同的信息。

延迟调用过程(DPC Deferred Procedure Calls)
图6-5展示了当一个客户端调用一些I/O操作的普通的事件队列,在这张图中,一个用户模式线程打开了一个文件句柄,使用ReadFile函数来执行一个读操作。因为这个线程可以实现一个异步调用,它几乎立刻控制然后做其他工作。这驱动收到了这个请求,调用驱动系统驱动(NTFS)。这可能调用它底层的其他驱动,知道请求到达磁盘驱动,这将初始化实际的硬盘硬件。在这时,没有代码需要执行,因为硬件“做这件事情”。
当硬件做完这个读操作的时候,它将引发一个中断,这个与中断相关的中断处理例程在Device IRQL级别上隐形(注意处理这个请求的线程是任意的,因为这个中断是异步到达的)。通常访问硬件的中断处理例程得到了这个操作结果。它最终的行为应该是完成这个初始化请求。

正如我们在第四章所看到的,通过调用IoCompleteRequest来完成一个请求。现在这个问题是文档表示这个函数只能在IRQL<=DISAPTCH_LEVEL(2)时该函数才能被调用。这意味着中断处理例程不能调用IoCOmpleteRequest否则将造成系统崩溃。所以中断处理例程做什么?
你可能好奇为什么有这样一个限制。一个原因是与IoCompleteRequest所做的工作有关。我们将讨论更多细节在下一章中,但是需要强调的是这个函数相对开销是非常大的。如果这个调用被允许,这将意味着中断处理例程将花费更多的时间去执行,因为它执行在一个更高级别的IRQLs上,这将很长一段时间屏蔽掉其他中断。
允许中断处理例程调用IoCompleteRequest(或者其他相似限制的函数)是使用一个延迟过程调用(DPC)。一个DPC要封装在一个IRQL_DISPACH_LEVEL级别上的函数。在这个IRQL中,调用IoCompleteRequest是允许的。
你可能好奇为什么中断处理程序不是简单地降低当前的IRQL到DISPATCH_LEVEL调用IoCompleteRequest,之后将IRQL提上到原来的值。这可能会造成死锁,我们将在“Spin Locks”这章之后再来讨论这个原因。
注册这个中断处理例程的驱动预选准备了一个DPC,在非分页内存中分配了一个KDPC并且初始化它使用一个称为KeInitializeDpc的函数。之后,在退出函数之间,这个中断处理例程被调用,只要使用KeInsertQueueDpc来插入队列这个中断处理例程将请求DPC执行。当DPC函数执行的时候,它将调用IoCompleteRequest。因此DPC做了一个妥协 - 运行在DISPATCH_LEVEL的上,这意味着没有线程调度发生,非分页内存访问等。但是这还不足以阻止运行相同处理器上的硬件中断。
在系统上的每一个处理器都拥有自己的DPCs的队列,默认来讲,KeInsertQueueDpc将DPC插入当前处理器的DPC队列。一个中断处理例程返回时,在IRQL降到零之前,其检查一下处理器的DPC队列中是否存在DPCs。如果存在,这个处理器降到 DISAPTCH_LEVEL(2) 之后处理器处理DPCs在这个队列使用一个FIFO模式,调用相应的函数直到这个队列为空。只有这个处理器的IRQL降到零,才恢复当中断到达时被打断的原始执行代码。
DPCs可以使用一些方式来定制化。查阅这个KeSetImportanceDpc和KeSetTargetProcessorDpc函数文档。
图6-6增加了图6-5的DPC例程执行。

通过一个定时器来使用DPC
DPC最初设计是为了中断服务例程来使用的。然而,内核中还存在其他的初始化DPC的机制。
一个例如使用一个内核定时器。一个内核定时器,是通过一个KTIMER结构展现的,其允许设置一个定时器来在未来某个时间到期,其基于一个相对时间或者绝对时间。这个定时器时一个派发对象,因此可以使用KeWaitForSingleObject所等待(我们将在这章的"同步"章节来介绍)。虽然等待是可能的,但这对于定时器是不方面的。一个简单的方法是调用回调函数当定时器终止时。实际上内核调试器提供一个DPC来作为它的回调。
下面代码片段展示了如何配置一个定时器并将其关联到DPC。当一个定时器截止时,这个DPC被插入到CPU的DPC队列,因此其尽可能快的被执行。使用一个DPC比一个IRQL为0的回调函数具有更大的权力,因此它保证在任何用户代码(以及大部分内核代码)之前执行。

异步调用过程(APC Asynchronous Procedure Calls)
我们在之间章节看到过DPC的对象被包裹在一个IRQL级别为DISPACH_LEVEL的函数。这与所调用线程无关,只有DPC才是相关的。
APC也是包裹在一个函数中被调用。但是相比与DPC,一个APC的目标是一个实际的线程,所以只有那个线程才可以执行这个函数。这意味着每一个线程都有一个与APC相关的队列。
这儿有三种典型的APCs:
- 用户模式APCs - 这些在IRQL PASSIVE_LEVEL用户模式下运行,当这个线程为可被唤醒状态。这通过调用一个例如SleepEx、WaitForSingleObjectEx或者WaitForMulipleObejctsEx等Apis。这类函数的最后一个参数设置为TRUE,将把线程设置为可唤醒状态。在这个状态下,其会看它的APC队列,如果其不为空 - 这个APCs将立刻执行直到这个APC队列为空。
- 普通内核模式APCs - 其以PASSIVE_LEVEL运行在内核模式中并且抢占用户模式代码和用户模式的APCs。
- 特殊内核APCs - 其以APC_LEVEL 运行在内核模式,其抢占用户模式代码,正常的内核模式APCs和用户模式APCs。这些APCs由I/O系统来完成I/O操作。我们将在下一章来进行更详细地讨论。
这个APC API并没有再内核模式中文档化,因此驱动通常无法直接使用APCs。
用户模式可以使用(用户模式)APCs通过调用某些APIs。例如调用ReadFileEx或WirteFileEx开始一个异步I/O操作。当这个操作完成一个关于调用线程相关的用户模式APCs.这个APCs将执行当线程进入一个如之前的可唤醒状态。另一个在内核模式的产生一个APC是UeueUserApc。查看Windows API文档来查看更多详细细节。
临界区和防护区
一个临界区(Critical Region)阻止用户模式和正常的内核APC执行(内核APCs仍然可以执行)。一个线程进入一个临界区使用KeEnterCriticalRegion并且离开它使用KeLeaveCriticalRegion。在内核中一些函数必须进入一个临界区,特别是当执行那些"可执行资源"(executive resource)(看这个"executive resource"在这节之后)。
一个防护区(Guarded Region)阻止所有APCs执行,调用KeEnterGuardedRegion进入一个防护区,调用一个KeLeaveGuardedRegion来离开它。对KeEnterGuardedRegion的递归调用必须与对KeLeaveGuardedRegion的相同数量的调用相匹配。
提升IRQL到APC_ELEVE无法分发全部的APCs.
结构化异常处理
一个异常时一个由于某种指令运行而操作处理器发生错误的异常事件。异常与中断在某些方面是相同的,这个主要不同是异常是同步的并且从技术上在相同条件下是可复制的,然而中断是异步的,可以在任何时间抵达。异常的例子包含除零异常,中断,页错误,栈溢出,无效指令等。
如果一个异常发生,内核将会捕捉到它并且运行代码来处理这个异常,如果可能,这个被称为SEH的机制是可以被用户模式和内核模式调用的。
内核异常处理机制是基于中断派发表(IDT),这是个中断向量与中断处理程序一一映射的。使用一个内核调试器,这个!idt指令将展示所有的映射信息。这个中断向量的低部分实际上就是异常处理程序,这个有一个这个指令输出的例子:
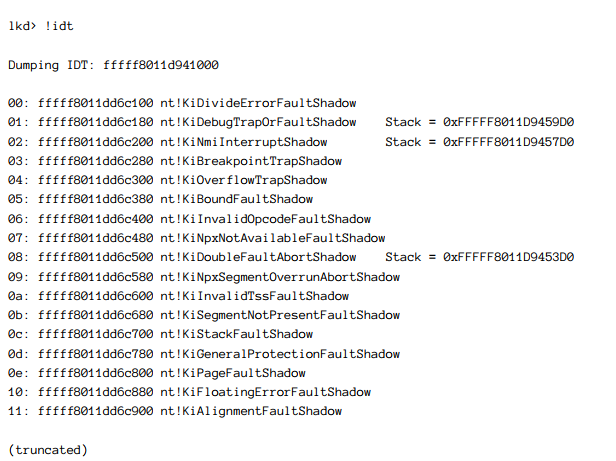
注意这个函数名字 - 大多数是有描述性的。这个默认连接着Intel/AMD入口(在这个例子中),因此常见的异常例子包含:
- 除零(0)
- 断点(3) - 内核处理这个是完全透明的,将控制传递给一个附加的调试器(如果有)。
- 无效指令(6) - 如果遇到一个未知指令,这CPU会引发这个错误。
- 页错误(14) - 如果这个转换虚拟地址到物理地址的页目录表的Valid位置为0,CPU将会引发这个错误(就cpu而言)。这个表示这个页不存在物理内存中。
这些错误由内核引发作为一个之前的CPU错误。例如,如果一个页错误被处罚,这个内存管理器的页错误处理程序将尝试定位到这个不在RAM中的页。如果这个页确实不存在,这个内存管理器将引发一个页访问异常。
一旦异常被处罚,内核为处理程序调查哪里发生的异常(除了一些透明处理的异常之外,例如BreakPoint(3))。如果没有找到,它将查询这个调用栈,直到异常处理句柄被找到。如果调用栈被消耗完,这个系统将崩溃。
一个驱动如何处理这些类型的异常?微软给C语言添加了四种关键字,允许开发者很容易的使用这些异常。表6-1以简洁的方式描述了被添加的关键字。

__try/__except 和 __try/__finally是有效的关键字。然而,这些可以被任意水平的嵌套使用。
这些关键字也以相同的方式运行在用户模式上。
使用 __try/__except
在第四章中,我们采用一个访问用户缓冲区得到驱动操作所需要的数据,我们使用一个直接指向用户模式缓冲区的指针。然而,这并不能保证安全。例如,用户模式代码(从另一个线程来讲)可能释放这个内存,在驱动访问之前。在这种情况下,驱动会造成一个系统崩溃由于一个用户的错误(或者恶意企图)。因为用户数据从来不可以被信任,这种访问应该包裹在一个__Try/__except块中来确保一个坏的缓冲区不会让这个驱动崩溃。
我们重新回顾一下IRP_MJ_DEVICE_CONTROL处理程序,使用一个异常处理是非常重要的一部分:

在__except中填入EXCEPTION_EXECUTE_HANDLER表示任何异常都会被处理。我们可以进行更多选择来调用GetExceptionCode来查看其实际异常类型。如果我们不期望这样,我们可以告诉内核继续通过调用栈来寻找处理方式:

这难道意味着驱动可以捕获任何异常吗?如果这个,驱动永远不会造成系统崩溃。当然不是这样(幸运的是,这你来你的角度)。访问违法,例如,只能这个侵权地址在用户空间时才能被捕获。如果在内核空间,这将不会被捕获,仍然造成一个系统崩溃。这应该敏感的,因为有些坏事已经发生,但是内核无法让驱动除掉它。用户模式地址,另一方面,并不受内核驱动控制,因此这种异常可以被捕获可以处理。
这SEH机制可以被驱动使用(和用户模式代码)来抛出一个定制化异常。这内核提高一个ExRaiseStatus函数来抛出任何异常和一些指定函数ExRaiseAccessViolation。
你可能好奇在高级语言(C++,JAVA,.NET)中异常是如何工作的。这依赖于具体实施,但微软的编译器使用SEH异常覆盖在他们的实际平台的代码后面。例如,.NET异常使用这个值0xe0434c52。选用这个值是因为最后三个字节是ASCII码“CLR”,oxe0只是确保这个数不与其他数冲突。这个c#表达式的thorw将使用RaiseException API 在用户模式中携带着异常抛出,这些参数提供给 .Net Common Language Runtime(CLR)它所需要的信息来识别这个"throw"对象。
使用__try/__finally
__try/__finally块的使用并不直接与异常相关联。这应该确保某些代码无论在什么条件下都会被执行 - 无论这个代码是干净地退出还是由于异常中间退出。这很像一些高级语言(JAVA,c#)中的finally关键字。这里很明显展示了这个问题:

上面代码看起来是无害的,然而,其存在这么几个问题:
- 如果一个异常在分配与释放之间被抛出,调用者的一个处理程序会接管但是内存没有释放。
- 如果一个返回语句在某些状态下在分配与释放之间被使用,这个缓冲区不会被释放。这需要消息的使用代码来确保所有推出的函数都要指向这个释放的代码。
这第二个可以通过小心编程来实现,但是最好避免编码负担。这第一个不可能通过标准的编码技术来避免。_try/_finally于是来了。使用这个组合我们可以确保这个无论在什么情况下都会被释放:

上面这段代码,如果在_try体中使用return语句,这_finally的代码在函数返回之前也会被调用。如果一些异常发生,这个_finally块会第一个运行,在内核搜索调用栈来找到处理程序之前。
_try/_finally不仅对于内存分配有用,对于其他资源也是有用的,只要是获取和释放需要运行。一个比较常见的例子是访问共享数据的内核同步。这个有一个获取和释放Mutex锁的例子(fast mutex和其他同步原子将会在这章的之后所描述)。

使用C++ RAII而不是 _try/_finally
虽然前面提到过 _try/_finally的例子,它们有时是不方便的。使用C++我们可以构建RAII包裹体,这可以正确的执行而不需要使用_try/_finally。C++并没有一个finally关键字像C#或Java一样,但它并不需要 - 它有一个析构器。
这儿有一个非常简单,小的例子,使用RAII类来管理缓冲区分配:

这个类使用一个模块很简单可以应用到各种类型的数据中,例如下面一个例子的使用:
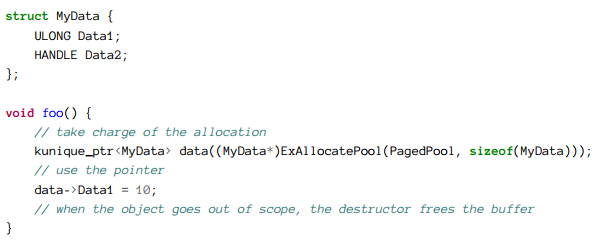
如果你一般情况下不把C++作为自己的首要编程语言,你发现上面这个代码是非常困惑的。你可以继续使用_try/_finally,但是我推荐你使用这个代码的类型获取,即使你非常挣扎的使用上面的kunique_ptr,你仍然可以不需要有太深的理解来使用它。
这个kunique_ptr类型是最低限度。你也应该移除拷贝和复制构造函数,并尽可能允许赋值和移动(C++11或更高版本,用于所有权转移)和其他帮助程序。这儿有一个更复杂的版本:

我们将在之后使用其他RAII包裹体来用于在章后面的同步原语。
系统崩溃
正如我们所知道的,一个未处理的异常在内核中发生,这个系统会崩溃,通常称之为“蓝屏”(BOSD Blue of Screen death)。在这接种,我们将讨论当系统崩溃时会发生什么以及如何处理它。
这个系统崩溃有很多中名字,所有都意味着相同的事情 - “蓝屏”,“系统错误”,“BugCheck”,"“Stop Error”。这BOSD并不是像第一次简单的是一种惩罚,而是一种保护机制。应该被信任的内核代码做了坏的事情,停止运行可能是最安全的事情,让代码继续运行可能会存在一个无法重启的操作系统如何有些重要的文件或注册键得到损坏。
最新的Windows10版本在系统崩溃的颜色上做了一些替换。绿色表示内部构件,我实际上也遇到过橙色。
如果崩溃的系统连接到一个内核调试器,内核调试器将会断下。这允许检查这个系统状态在其他行为开始之前。
这个系统可以配置当系统崩溃时所进行的一些操作,这可以通过Advanced选项卡上的系统属性UI来完成。单击“启动和恢复”部分的“设置”,会出现“启动和恢复”对话框,其中的“系统故障”部分显示了可用的选项。图6-7显示了这两个对话框。
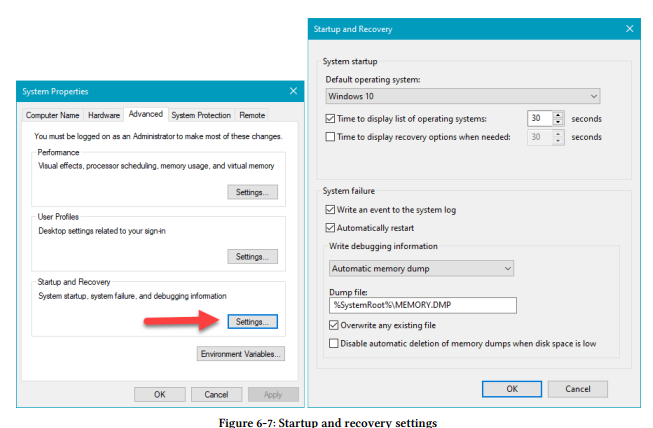
如果系统崩溃,一个事件入口被写到事件记录中。默认这个是检查的,我们没有理由去改变它。这系统下次重启时会自动配置;自从Windows2000依赖这是默认的。
设置中最重要的事情是生成一个dump文件。这个文件可以捕捉到系统崩溃时的系统状态。这个可以加载dump文件在调试期中分析。dump文件是非常重要的,因为其决定了在dump中哪些信息是展示出来的。再次强调一下,在系统崩溃时,dump文件并不会写入目标文件夹下,而是写入第一个页文件。只有当操作系统重启时,其注意到在这个页文件下的信息,其会将这个数据拷贝到目标文件。必须这做的理由是在系统崩溃时,向一个新文件写入某些东西是非常危险的行为,这个系统可能不足够稳定。最好的方法是将数据可以以任何方式打开恶毒页文件中。另一方面,这个页文件必须足够容纳整个dump,否则这个dump文件也不会写入。
dump类型将决定那种数据被写入,并提示可能需要的页面文件大小。这里有几种选择:

崩溃转储信息
一旦你有一个崩溃转储信息,你可以使用Windbg通过选择 File/Open Dump File 并且之后指向文件。这个调试器将展示如下的信息:

每个崩溃转存码有4个数字来提高关闭崩溃的信息。在这个例子中,我们可以看到这个代码是DIRVER_IRQL_NOT_LESS_OR_EQUAL(0xd1)并且下面四个参数依次是:内存参照,IRQL在此时调用的等级,读vs写操作,访问的地址。
这个指令很清晰的识别出myfault.sys作为一个错误模块(驱动)。这是因这是一个很容易的冲突 - 罪魁祸首出现在调用堆栈上,你可以在上面STACK_TEXT看到。(或者你可以再次使用k指令来查看)
这个 !analyze -v 指令通常是可拓展的,添加更多的分析使用一个拓展DLL是被允许的。你可能发现更多拓展在网站上。查阅 debugger API 文档来搜索如何添加在这条指令上添加代码的更多细节。
更复杂的崩溃转储可能只能从内核的错误线程的堆栈上查看。在你确定你发现了Windows内核的Bug之前,你这样假设:更可能的情况是驱动做了一个本身不致命的问题,例如一次缓冲区溢出 - 超出了它分配的内存中写入数据,不幸的是这块内存被其他驱动或内核分配,此时并没有什么坏的事情发生。一段时间之后,内核访问这块内存,获取一个坏的数据,造成一个系统崩溃。但是错误的驱动并没有在调用堆栈中找到什么;这样诊断是更加困难的。
帮助诊断这种问题的一种方式是使用Driver Verifier。我们将在模块11中看到这个基础的Driver Verifier。
一旦你得到内存存储文档,非常有用的看这个题目为"Bugcheck Code Reference"的调试器文档,对常见的错误检查代码进行了更全面的解释,并介绍了典型的原因和下一步要研究的内容。
分析一个Dump文件
一个Dump文件是一个系统的快照。初次之外,其与任何内核调试会话都是一样的。你不可以设置断点,也确实不能使用go指令。其余全部命令都像平常一样可是使用。像!process , !thread,lm,k可以被正常使用,这里有一些其余的命令和提示:
- 这个提示(prompt)指明了当前的处理器。切换处理器可以使用 ~ns ,n表示CPU的索引(在内核模式中看起来像切换线程。
- !running指令可以列出崩溃时运行在所有处理器上的线程列表。添加可选的 -t 显示了每个线程的调用堆栈,这里有上面崩溃转储的一个例子:
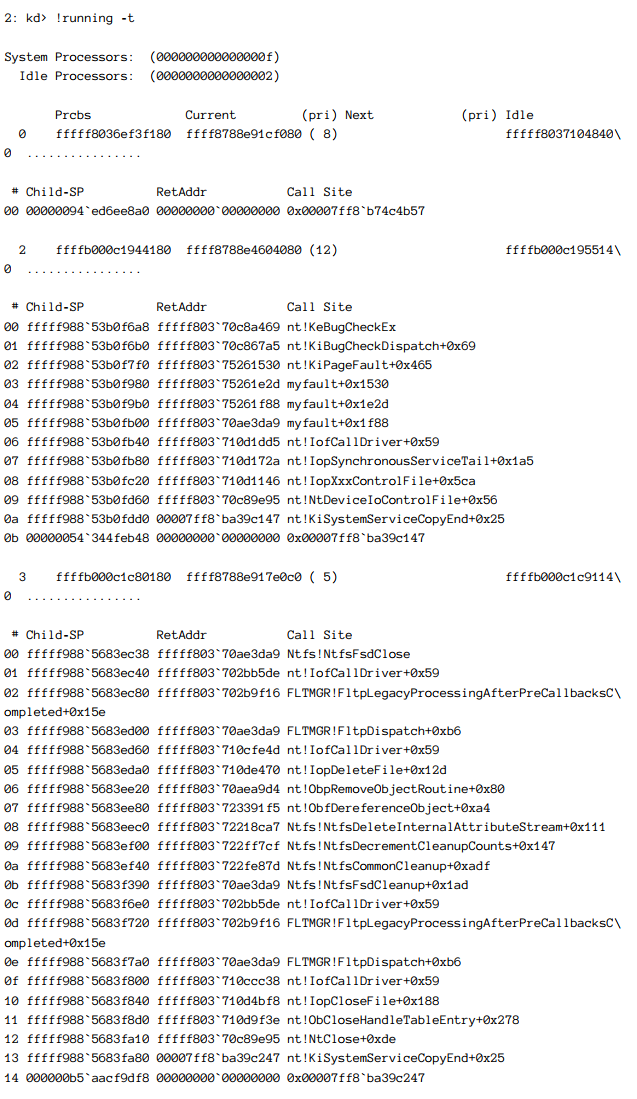
这个指令是一个好方法当系统崩溃时其进行了什么动作。
- !stack指令默认列出了所有线程的全部线程调用。一个更有用的变体是搜索字符串,它只列出包含该字符串的模块或函数出现的线程(因为它可能没有运行在崩溃时的线程,但会在线程的调用堆栈上)。这个有上面崩溃的一个例子:

系统挂起
系统崩溃时最创建的dump类型。然而,我们需要知道dump的另一种类型: a hung system(一个挂起的系统)。挂起系统是一个无响应或者接近无响应的系统。看起来似乎是暂停或者死锁了 - 这系统看起来并没有发生崩溃,所以首要问题是如何得到这个系统的dump文件呢?
一个dump文件包含着多种系统类型,这并没有与系统崩溃或者其他坏的状态有必然联系。很多工具(包含内核调试器)可以在任何时间生成一个dump文件。
如果这个系统对某些内容仍然有反应,这个内核工具 NotMyFault 可以强制系统崩溃因此强制生成一个dump文件。图6-8展示了NotMyFault的截图。选中第一个(default)选项并且点击Crash立刻会让系统崩溃,上生成一个dump文件(如果这样配置的话)。
MyFault使用一个myfault.sys驱动来负责系统崩溃。NotMyFault有32位和64位版本。记住使用与操作系统正确的一个,否则这个驱动将加载失败。
如果这个系统完全无反应,你可以使用内核调试器,之后使用 .dump 指令来生成一个dump文件。
如果这个系统无反应并且调试器不能附加,你可以可以手动的生成一个崩溃如果在注册表中预先进行了配置。当检测到某个组合键时,这个键盘驱动将会产生一个崩溃。在这个链接中可以查看详细细节。这个冲突代码是0xe2(MANUALLY_INITIATED_CREASH)。
线程同步
线程有时需要协同工作,一个典型例子是一个驱动使用一个链表来收集数据项。这个区能可以被多个客户端唤醒,来自不同线程或者不同处理器中的。这意味着链表操作必须以原子来运行,这不会进行损坏。如果多个线程同时多个线程访问相同的至少有一个是写的堆存,这就是一个数据竞争(data race)。如果发生数据竞争,世事难料,任何事都可能繁盛。一般来说,在一个驱动内部,一个系统泵阔可能时不时发生;数据崩溃通常是可以避免的。
在这种情况下,一个线程操作链表时其余所有的线程应该暂停并且等待第一个线程完成了这个工作。只有另外线程(第一个)可以操作这个链表。这就是线程同步的例子。
内核提供了几种原语,来帮助你完成正确的同步免于数据的同步访问。接下来讨论几种原语和线程同步的技术。
互锁操作(Interlocked Operations)
一组互锁函数可以通过初始化硬件来自动执行,操作非常方便,这意味着不包含软件对象。如果使用这些函数可以完成工作,那么应该尽可能的使用他们,因为他们足够高效。
一个简单的例子是增加一个整数。一般来说,这并不是一个原子操作。如果两个(或更多)线程在同一时间尝试执行这同一内存位置,这可能会导致增加丢失。图6-9展示了一个例子,两个线程同时增加,最后结果是1而不是2。

表6-2列出了几个驱动可以使用的互锁函数:

派发对象(Dispatcher Objects)
这个内核提空了一组名为派发对象的原语,也称为等待对象。这些对象有一组状态称为 有信号 和 无信号,这个有信号和无信号的状态依赖于对象的类型。它们之所以被称为“可等待的”因为一个线程可以等待一个对象直到它们变为有信号。在等待时,线程不消耗CPU周期因为它处于一个等待状态,
这个被用来等待的是KeWaitForSingleObject 和 KeWaitForMultipleObjects函数。它们的原型展示如下:

这个有这些函数参数的纲要:
- Objects - 指定咬着要等待的对象。注意这些函数工作的是对象,并不是句柄。如果你有一个句柄(可能是用户层提供的),称之为 ObReferenceObjectByHandle来得到这个对象的指针。
- WaitReason - 指明等待理由。这个等待理由列表是非常长的,但驱动通常应该设置它为Executive,除非是等待用户请求,因此它可以指定为UserRequest。
- WaitMode - 可以指定为用户模式或内核模式。大多数驱动应该指明内核模式。
- Alterable - 指明了如果这个线程是否在等待期间可以唤醒。可唤醒状态允许用户模式的Apcs派发。用户模式APCs可以派发如果等待模式是UserMode。大多是驱动应该指明FALSE。
- Timeout - 指明等到时间。如果指明为NULL,这个等待是无限的,一直等待这个对象变为有信号。这个参数的单位是100nsec块,其中负数是相对等待,而正数是绝对等待,从1601年1月1日午夜开始测量。
- Count - 等待对象的个数。
- Object[] - 等待对象指针的数组。
- WaitType - 执行是否等待所有对象变为有信号(WaitAll)或者仅仅等待一个对象(WaitAny)。
- WaitBlockArray - 在内部用于管理等待操作的一组结构。如果对象数量 <= THREAD_WAIT_OBJECTS(当前为3) ,则是可选的 - 内核将使用建立在每个线程内的数组。如果这个等待数量是更高的,这个驱动一定从非分页内存池中分配正确的大小,并且在等待完成之后收回这些分配。
这个KeWaitForSingleObject主要返回这两个值:
- STATUS_SUCCESS - 等待满足因为这个等待对象变为有信号。
- STATUS_TIMEOUT - 等待满足因为超时。
注意这些返回值通过NT_SUCCESS宏变为TRUE。
KeWaitForMultipleObject返回值就像KeWaitForSingleObject一样支持STATUS_TIMEOUT。STATUS_SUCCESS返回如果WaitAll类型被指定,所有的Objects变为Signaled。对于WaitAny的等待,返回值其是有信号的对象在数组中的索引值。
这里有一些关于等待函数的相关细节,特别是如果等待模式是UserMode,并且这个等待是可唤醒的。检查WDK文件来看更多细节。
表6-3列出了常见的派发对象,以及这个有信号和无信号对象的含义:

下面这些节将到被用来讨论常见的在驱动中被用来同步的常见内核对象。我们还将讨论其他一些对象,它们不是dispatcher对象,但支持等待线程同步。
互斥体(Mutex)
互斥体是一个典型的对象,用于解决多线程之间访问一个共享资源的问题。
当它被释放时,一个互斥体是有信号的。一旦这个线程调用了一个等待函数,这个对待被满足,这个互斥体变为无信号,线程称为这个互斥体的拥有的。拥有者对于一个互斥体来说是非常重要的,它意味着如下:
- 如果一个线程是一个互提体的拥有者,那么它是唯一一个可以释放互斥体的。
- 一个互斥体可以被同一个线程获取多次。第二次尝试将会自动成功因为线程是当前互斥体的主人。这也意味着线程需要释放与它被获取的相同次数;只有这个互斥体被再一次释放(变为有信号)。
使用一个互斥体需要从非分页内存中分配一个KMUTEX结构体。这个互斥体API包含着下列工作的KMUTEX函数:
- KeInitializeMutex一定会在初始化mutex时被调用。
- 一个等待函数,传递的是分配的KMUTEX结构体的地址。
- KeReleaseMutex被调用当一个拥有mutex的线程想去释放它时。
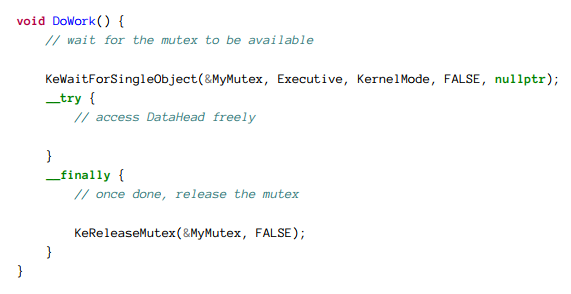
基于上面的例子,这里有一个简单的使用mutex锁的例子来访问一些共享数据,在同一时间只有一个线程可以访问:

释放这个Mutex锁是非常重要的,所以使用_try / _finally来确保所有的被完成:
因为使用 _try/_finally 有有点尴尬,我们使用C++为等待来创建一个RAII包裹体。这应该也被用于其他的同步原语。
首先,我们将创建一个mutex包裹体,提供一个名为Lock和Unlock的函数:

之后我们可以创建一个RAII包裹体为其他的类型,其也拥有一个LOCK和UNLOCK函数:

使用这个定义,我们可以使用mutex来取代代码,其如下:

Fast Mutex
一个Fast Mutex是经典互斥锁的另一种选择,表现得更好。这并不是一个派发对象,因此它拥有获取和释放mutex的自己的API。与常规互斥锁相比,其有以下特征:
- 快速互斥锁不能递归的获取。这样做会造成一个死锁。
- 当快速互斥锁被获取时,这个CPU的IRQL权限会提升到APC_LEVEL(1)。这会阻止所有的APC派发到线程。
- 快速互斥锁只能被无限的等待 - 没有办法指明一个超时时间。
由于前两个,这个快速互斥锁显然比常规互斥锁要快。事实上,大多数使用互斥锁的驱动会使用快速互斥锁,除非有一个令人信服的理由去使用常规互斥锁。
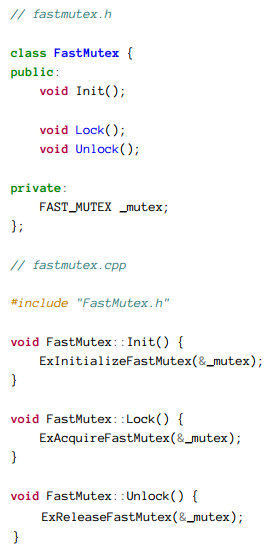
一个快速互斥锁通过分配一个非分页内存池的FAST_MUTEX结构体并且调用ExInitalizeFastMutex。获取这个锁使用ExAcquireFastMutex或者ExAcquireFastMutexUnsafe(如果当前IRQL等级早已提升到APC_LEVEL)。释放一个快速互斥锁使用ExReleaseFastMutex或者ExReleaseFastMutexUnsafe函数。
这个快速互斥锁并不会导出到用户模式。用户模式只能使用常规的锁。
从一般使用的角度来说,这个快速互斥锁和互斥锁是等价的。仅仅更快一点。
我们可以创建一个C++包裹体为一个快速互斥锁,为了可以自动的获取和释放它,其通过在之前定义的AutoLock RAII类实现。
信号量(Semaphore)
信号量最初的目标是限制某些东西,比如一个队列的长度。这个信号量通过它的最大长度和初始数量来初始化的,通过调用KeInitilizeSemaphore。当它的内部数比零大时,这个信号量是有信号的。一个调用KeWaitForSingleObject线程当自己等待,这个信号量数减少一。这个过程会继续直到零,此时信号量变为无信号。
举一个例子,想象一个由驱动管理的工作集队列。一些线程想添加项目想这个队列中。每一个线程调用KeWaitForSingleObject来获取这个信号量中的一个数。只要这个数量比零大,这个线程就可以继续向队列中添加项目,增加它的长度,信号量失去一个数。其他一些线程的任务是处理这个线程的工作项。一旦一个线程从队列中移除它的项,它会调用KeReleaseSemaphore增加这个信号量的数量,再一次将信号量变为有信号状态,允许潜在的另一个线程运行,向队列中添加一个新的项。
事件(Event)
一个事件包裹了一个Boolean的标志 - 是true(有信号)或者false(无信号)。事件的主要目的是发出某些事情发生的信号,来提供同步流。例如,如果一些条件变为真,一个事件可以被置为,一组线程可以从等待条件下释放并继续处理某些早已被进程准备好的数据。
这里有两种类型的事件,类型可以在初始化时被指定:
- 通知事件(手动重置) - 当时间被置位的,其释放所有等待的线程,这个事件状态保留在置位(有信号)直到明确的重置。
- 同步事件(自动重置) - 当一个事件被置位时,其最多释放一个线程(无论有多少线程等待这个事件)。一旦这个事件被释放,其立刻自动地被重置状态(无信号)。
一个通过分配一个非分页的KEVENT结构体创建,并且调用KeInitializeEvent来初始化,指定这个事件类型(NotificationEvent或SynchronizationEvent)并且初始化这个事件状态(signaled或non-signaled)。使用KeWaitXxx函数来等待着这个事件被完成。调用KeSetEvent来让事件变为有信号状态,而调用KeResetEvent或者KeClearEvent重置它(无信号状态)(后一个函数可能更快一点,因为其不返回之前的事件状态)。
资源执行体(Executive Resource)
一个典型的由多个线程访问一个共享资源的同步问题通过使用一个互斥体或快速互斥体来解决。它是有效的,但是互斥体是比较消极的,意味着它们允许单个线程来访问一个共享资源。在有些多个线程访问通过只读的方式访问资源时是不幸的。
在这种情况下,它可能混淆数据改变(写)与仅仅看数据(读) - 这是一个可能的优化。一个访问共享资源的线程可以声明它的意图 - 读或写。如果它声明读,其他声明读的线程也可以同时进行,这样效率更高。如果共享数据改变缓慢,这是非常有用的。读比写多得多。
互斥体本质是并发杀手,因为它们强制同一时间单独执行一个线程。这使得它们总是以牺牲并发性可能获得的性能为代价工作。
内核针对这种情况提供了另一种同步原语,其被称为单写,多读(single writer,multiple readers)。这个对象是资源执行体,并不是派发对象的另一种对象。
初始化一个资源执行体是通过从非分页内存池中分配一个RESOURCE结构体,并且调用ExinitalizeResource。一旦初始化,线程可以通过ExAcquireResourceExclusiveLite获取执行体锁(对于写)或者调用ExAcquireResourceSharedLite来获取共享锁。一旦工作被完成,一个线程使用ExReleaseResourceLite来释放资源执行体(无论其是否被单独获得)。使用这个获取和释放函数的前提是这个正常内核APC一定是无法使用的。这个可以在调用前通过调用KeEnterCritical来完成,在调用之后KeLeaveCriticalRegion。代码片段如下所示:

因为使用资源执行体是非常常见的,这儿有一些函数可以使用一次调用来完成全部操作:

ExEnterCriticalRegionAndAcquireResourceShared函数也有获取共享的类似功能。
高IRQL同步机制(High IRQL Synchronization)
在同步那节为止已经处理了各种类型对象的线程等待。然而,在一些情况下,线程无法等待 - 特别,当处理器的IRQL是DISPATCH_LEVEL(2)或者更高。这一节讨论这种情况,如何处理它们。
让我们举一个这种情况的例子:一个驱动有一个定时器,使用KeSetTimer来设置,当定时器截止时,使用DPC来执行代码。在同一时间,驱动中的其他函数,例如,IRP_MJ_DEVICE_CONTROL可能同时执行(运行在IRQL0)。如果这些函数同时需要访问一个共享资源(例如链表),他们必须同步访问来阻止数据冲突。
这个问题是DPC无法调用KeWaitForSingleObject函数或者其他任何等待函数 - 调用这些事致命的。所以这些函数如何同步访问呢?
当系统是单CPU时这是个比较容易的例子。在这种情况下,当访问一个共享资源时,低IRQL函数仅仅需要提升IRQL到DISPATCH_LEVEl,之后访问资源。在这段时间DPC无法打断这个代码因为CPU的IRQL早已为2。一旦代码完成了共享资源的处理,它可以降低IRQL到0,允许DPC执行。这阻止了同一时间这些例程的执行。图6-10展示了这个步骤:
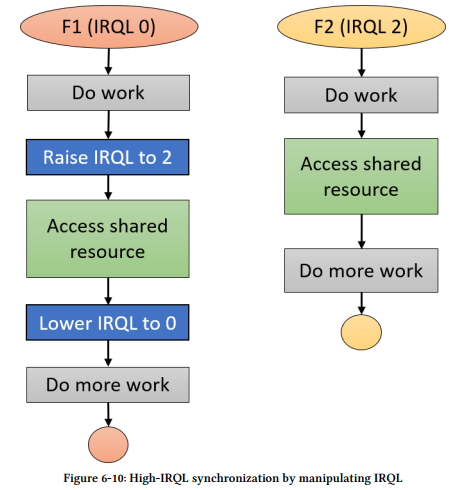
在标准的系统中,有超过一个CPU,这个同步策略是不够的,因为一个IRQL是一个CPU的属性,而不是系统范围的属性。如果一个CPU的IRQL被提升为2,如果一个DPC需要执行,它可以中断其他的IRQL为0的CPU。在这种情况下,函数在同一时间执行是可能的,访问共享资源,造成资源竞争。
我们如何来解决那个呢?我们需要一些类似互斥体的但是可以在处理器之间同步 - 不是线程。这是因为当CPU的IRQL高于2,线程本身失去了意义因为调度器无法在CPU上隐形,这种对象是存在的 - 这个自旋锁(Spin Lock)。
自旋锁(The Spin Lock)
自旋锁是内存中的一个简单位,它通过API提供原子测试和修改操作。当一个当前不是空闲的CPU尝试获取一个自旋锁时,这个CPU使用自旋锁保持自旋,忙着等待这该锁被其他CPU释放(记住,把线程放入一个等待状态不能在DISPATCH_LEVEL或更高级别上完成的)。
我们在之前的章节中描述了这个情景,一个自旋锁将需要分配和初始化。每一个获取访问共享数据的函数需要提升IRQL到2(如果不是早已到达2),获取自旋锁,用于共享数据最后释放自旋锁并且降回IRQL。这个事件链表如6-11中所展示的。
创建一个自旋锁需要从非分页内存池中分配一个KSPIN_LOCK结构体,调用KeInitializeSpinLock初始化,将自旋锁放入未拥有的状态。

获取一个自旋锁通常有两步:第一,提升IRQL到正确的级别,这是试图同步对共享资源的访问的任何函数的最高级别。在之前的相关联的IRQL为2。第二步,获取自旋锁。使用正确的API来组合这两步,这个过程如6-12所描述的:
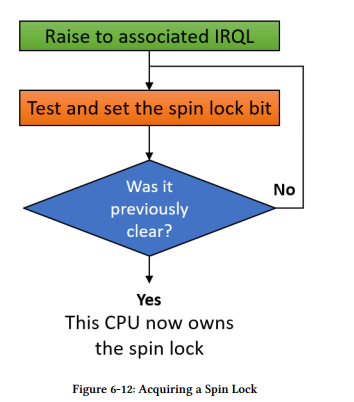
获取和释放一个自旋锁的两步过程的轮廓在图6-12中。表604展示了相关APIs和用于自旋锁的相关APIs:

如果你获取了一个自旋锁,必须确保在同一个函数释放它,否则可能会造成一个死锁。自旋锁来自哪里?
这里描述的场景要求驱动程序分配自己的自旋锁,以保护对自己数据的并发访问不受高irql函数的影响。一些自旋锁存在于其他对象中,例如KINTERRUPT对象使用基于驱动的硬件来处理中断。另一个例子是system-wide自旋锁,被称为 Cancel自旋锁,者通过内核调用一个注册在cancellation例程获取。这是唯一一个驱动释放一个未明确获取自旋锁的情况。
如果几个CPU同一时间获取相同的自旋锁,哪个CPU会首选获取呢?一般来说,这是无序的 - 运行更快的CPU会赢。内核确实提供了另一种,被称为自旋锁队列的,其基于FIFO来服务于CPU。这些工作在DISPATCH_LEVEL的IRQL级别。相关APIs是KeAcquireInstackQueuedSpinLock和KeReleaseInStackQueuedSpinLock。先查WDK文档来找更多细节。
工作项(Work Items)
有时需要运行一段代码在不同的线程而不是执行一个。一种方式是明确地创建一个线程,之后运行代码来为其分配任务。这个内核提供了允许一个驱动创建额外的执行线程:PsCreateSystemThread和IoCreateSystemThread(可以在Windows 8+上使用)。如果线程需要在后台长时间运行代码,这些函数都是合适的。然而,对于时间限制的操作,最好使用一个内核提供的线程池,它将执行你的代码在某些系统工作线程。
IoCreateSystemThread是更好的,因为允许使用一个线程关联一个设备或对象。这可以让I/O系统添加一个对象的参数,可以确保驱动无法被卸载当这个线程在执行时。
一个驱动创建线程必须最后由自身调用PsTerminateSystemThread。如果成功,这个函数不会返回。
工作项(Work Items)是一个用来描述系统线程池的函数队列的术语。一个驱动可以分配和初始化一个工作项,指出希望驱动执行哪个函数,之后工作集被插入进池子。这似乎与DPC非常相似,主要不同是工作项总是运行在PASSIVE_LEVEL IRQL中,这个机制意味着可以由运行在IRQL2的函数在完成在IRQL0中的操作。例如,如果一个DPC例程需要执行的操作不允许在IRL2上运行(比如打开一个文件),它可以使用一个工作项来执行这些操作。
创建和初始化一个工作项可以由下列两种方式之一完成:
- 使用IoAllocateWorkItem来分配和初始化工作项。这个函数返回一个不透明的IO_WORKITEM指针。当工作项完成时,使用IoFreeWorkItem来释放。
- 通过使用IoSizeofWorkItem函数来自动分配一个IO_WORKITEM结构体。之后调用IoInitialzeWorkItem函数。当完成工作项时,使用IoUninitializeWorkItem。
这些函数接收一个设备对象,因此确保这个驱动没有被卸载当这个工作集在队列或执行时。
有一些其他的用于工作项的APIs,都是以Ex开始,例如ExQueueWorkItem。这些函数将不会关联工作项与驱动中的任何东西。例如上,驱动可以卸载当一个工作项仍然在运行时。最好总是使用Io函数。
将工作项入队,调用IoQueueWorkItem函数。其定义如下:

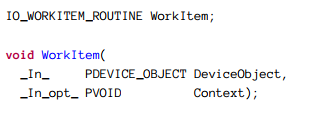
驱动需要提供的回调函数定义如下:
这个系统线程池有几个队列,其基于服务的工作项的优先级。这几个级别如下定义:

文档指明了DelayedWorkQueue一定被使用,但是实际上其他所支持的级别也可以使用。
这里有其他的可以用于将工作项插入队列中的:IoQueueWorkItemEx。这个函数使用一个不同的回调函数,该函数有一个额外的参数,其是工作项本身。如果工作项想要在退出之前释放工作项,这是非常有用的。