日期:2020.01.29
博客期:137
星期三
【本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)】
所有相关跳转:
a.【简单准备】
b.【云图制作+数据导入】
c.【拓扑数据】(本期博客)
d.【数据修复】
e.【解释修复+热词引用】
f.【JSP演示+页面跳转】
g.【热词分类+目录生成】
h.【热词关系图+报告生成】
i . 【App制作】
j . 【安全性改造】
嗯,先声明一下 “拓扑数据”的意思,应老师需求,我们需要将热词的解释、引用等数据从百科网站中爬取下来,之后将统一的热词数据进行文件处理,组合成新的数据表,然后可以在网页上(暂时是网页)展示更多的信息。
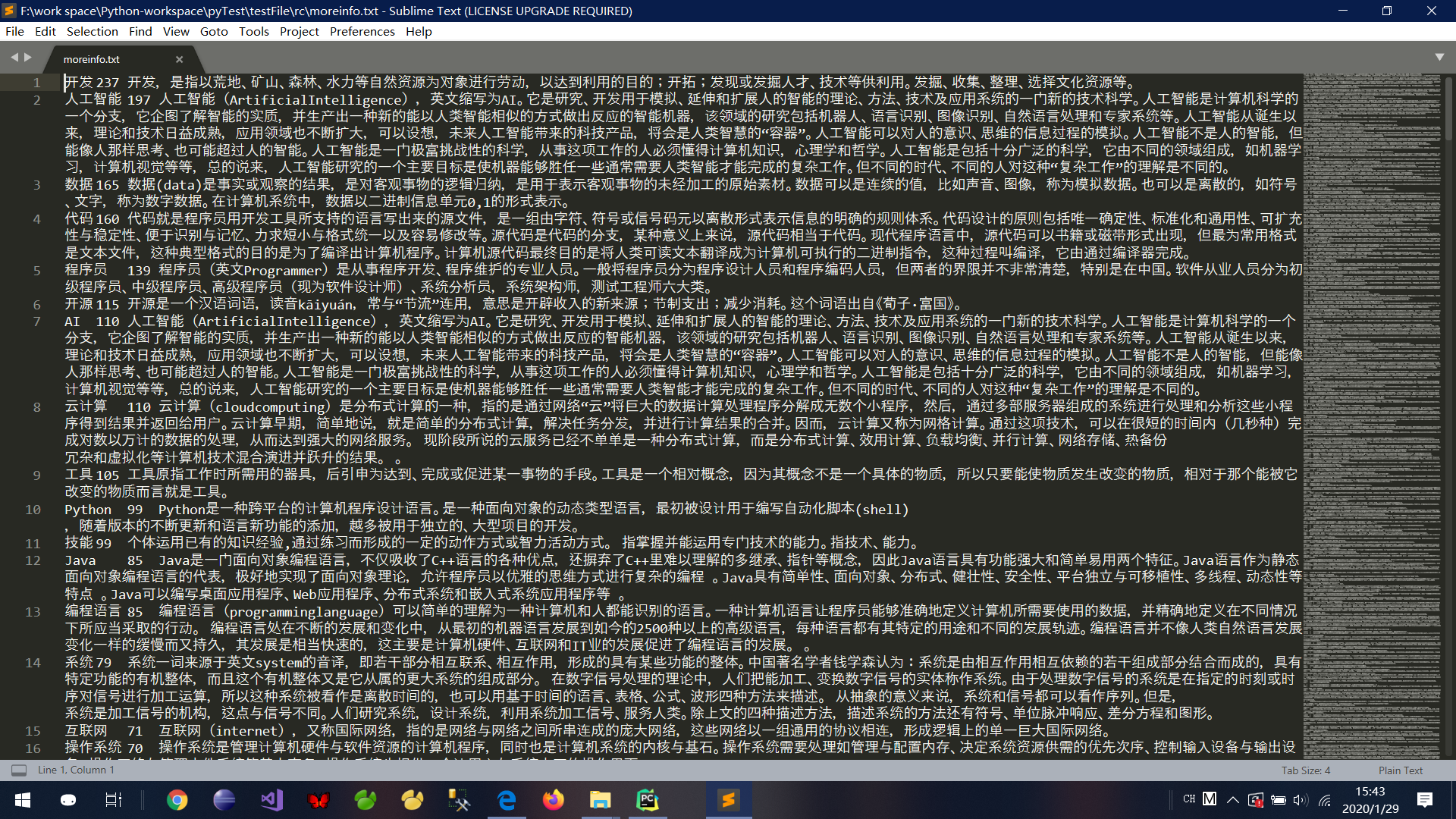
嗯,可以对热词解释进行爬取了,给大家看一下 (以人工智能为例) 
我发现了一个问题:
setAttr("value","人工智能")方法并不能实现input的value属性值变为想要的“人工智能”,我采用的是sendKeys("人工智能")方法来实现,不过这样又有了一个问题,每一次sendKeys()相当于再input内部又附加了这样的字符,比如原本input里有“茄子”字样,之后使用sendKeys(“蔬菜”),input里就变成了“茄子蔬菜”!这个问题就导致了我不能实现页面直接跳转。如何解决呢?
我从它的方法里找到了clear()方法,亲测可用(在sendKeys之前使用)。
我在这里提供测试类代码:


1 import parsel 2 from urllib import request 3 import codecs 4 from selenium import webdriver 5 import time 6 7 8 # [ 对字符串的特殊处理方法-集合 ] 9 class StrSpecialDealer: 10 # 取得当前标签内的文本 11 @staticmethod 12 def getReaction(stri): 13 strs = StrSpecialDealer.simpleDeal(str(stri)) 14 strs = strs[strs.find('>')+1:strs.rfind('<')] 15 return strs 16 17 # 去除基本的分隔符 18 @staticmethod 19 def simpleDeal(stri): 20 strs = str(stri).replace(" ", "") 21 strs = strs.replace(" ", "") 22 strs = strs.replace(" ", "") 23 strs = strs.replace(" ", "") 24 return strs 25 26 # 删除所有标签标记 27 @staticmethod 28 def deleteRe(stri): 29 strs = str(stri) 30 st = strs.find('<') 31 while(st!=-1): 32 str_delete = strs[strs.find('<'):strs.find('>')+1] 33 strs = strs.replace(str_delete,"") 34 st = strs.find('<') 35 36 return strs 37 38 # 删除带有 日期 的句子 39 @staticmethod 40 def de_date(stri): 41 lines = str(stri).split("。") 42 strs = "" 43 num = lines.__len__() 44 for i in range(0,num): 45 st = str(lines[i]) 46 if (st.__contains__("年") | st.__contains__("月")): 47 pass 48 else: 49 strs += st + "。" 50 strs = strs.replace("。。", "。") 51 return strs 52 53 # 取得带有 日期 的句子之前的句子 54 @staticmethod 55 def ut_date(stri): 56 lines = str(stri).split("。") 57 strs = "" 58 num = lines.__len__() 59 for i in range(0, num): 60 st = str(lines[i]) 61 if (st.__contains__("年")| st.__contains__("月")): 62 break 63 else: 64 strs += st + "。" 65 strs = strs.replace("。。","。") 66 return strs 67 68 @staticmethod 69 def beat(stri,num): 70 strs = str(stri) 71 for i in range(0,num): 72 strs = strs.replace("["+str(i)+"]","") 73 74 return strs 75 76 77 # [ 连续网页爬取的对象 ] 78 class WebConnector: 79 profile = "" 80 sw = "" 81 82 # ---[定义构造方法] 83 def __init__(self): 84 self.profile = webdriver.Firefox() 85 self.profile.get('https://baike.baidu.com/') 86 87 # ---[定义释放方法] 88 def __close__(self): 89 self.profile.quit() 90 91 # 获取 url 的内部 HTML 代码 92 def getHTMLText(self): 93 a = self.profile.page_source 94 return a 95 96 # 获取页面内的基本链接 97 def getFirstChanel(self): 98 index_html = self.getHTMLText() 99 index_sel = parsel.Selector(index_html) 100 links = index_sel.css('.lemma-summary').extract()[0] 101 tpl = StrSpecialDealer.simpleDeal(str(links)) 102 tpl = StrSpecialDealer.beat(tpl,20) 103 tpl = StrSpecialDealer.deleteRe(tpl) 104 tpl = StrSpecialDealer.ut_date(tpl) 105 return tpl 106 107 def getMore(self,refers): 108 self.profile.find_element_by_id("query").clear() 109 self.profile.find_element_by_id("query").send_keys(refers) 110 self.profile.find_element_by_id("search").click() 111 time.sleep(1) 112 113 114 def main(): 115 wc = WebConnector() 116 wc.getMore("人工智能") 117 s = wc.getFirstChanel() 118 print(s) 119 wc.getMore("5G") 120 t = wc.getFirstChanel() 121 print(t) 122 wc.__close__() 123 124 125 main()
嗯,然后我继续整合,将数据导入成文件批处理
对应代码:
1 import parsel 2 from urllib import request 3 import codecs 4 from selenium import webdriver 5 import time 6 7 8 # [ 整理后的数据 ] 9 class Info: 10 11 # ---[ 方法区 ] 12 # 构造方法 13 def __init__(self,name,num,more): 14 self.name = name 15 self.num = num 16 self.more = more 17 18 def __toString__(self): 19 return (self.name+" "+str(self.num)+" "+self.more) 20 21 def __toSql__(self,table): 22 return ("Insert into "+table+" values ('"+self.name+"',"+self.num+",'"+self.more+"');") 23 24 # ---[ 数据区 ] 25 # 名称 26 name = "" 27 # 频数 28 num = 0 29 # 中文解释 30 more = 0 31 32 33 # [写文件的方法集合] 34 class FileToWebAndContent: 35 36 fileReaderPath = "" 37 wc = "" 38 sw = "" 39 40 def __init__(self,r,w): 41 self.fileReaderPath = r 42 self.wc = WebConnector() 43 self.sw = StringWriter(w) 44 self.sw.makeFileNull() 45 46 def __free__(self): 47 self.wc.__close__() 48 49 def __deal__(self): 50 fw = open(self.fileReaderPath, mode='r', encoding='utf-8') 51 lines = fw.readlines() 52 num = lines.__len__() 53 for i in range(0,num): 54 str_line = lines[i] 55 gr = str_line.split(" ") 56 name_b = StrSpecialDealer.simpleDeal(gr[0]) 57 num_b = StrSpecialDealer.simpleDeal(gr[1]) 58 if(int(num_b)<=2): 59 break 60 self.wc.getMore(name_b) 61 more_b = self.wc.getFirstChanel() 62 if(more_b==""): 63 continue 64 info = Info(name_b,num_b,more_b) 65 self.sw.write(info.__toString__()) 66 67 68 # [ 对字符串的特殊处理方法-集合 ] 69 class StrSpecialDealer: 70 # 取得当前标签内的文本 71 @staticmethod 72 def getReaction(stri): 73 strs = StrSpecialDealer.simpleDeal(str(stri)) 74 strs = strs[strs.find('>')+1:strs.rfind('<')] 75 return strs 76 77 # 去除基本的分隔符 78 @staticmethod 79 def simpleDeal(stri): 80 strs = str(stri).replace(" ", "") 81 strs = strs.replace(" ", "") 82 strs = strs.replace(" ", "") 83 strs = strs.replace(" ", "") 84 return strs 85 86 # 删除所有标签标记 87 @staticmethod 88 def deleteRe(stri): 89 strs = str(stri) 90 st = strs.find('<') 91 while(st!=-1): 92 str_delete = strs[strs.find('<'):strs.find('>')+1] 93 strs = strs.replace(str_delete,"") 94 st = strs.find('<') 95 96 return strs 97 98 # 删除带有 日期 的句子 99 @staticmethod 100 def de_date(stri): 101 lines = str(stri).split("。") 102 strs = "" 103 num = lines.__len__() 104 for i in range(0,num): 105 st = str(lines[i]) 106 if (st.__contains__("年") | st.__contains__("月")): 107 pass 108 else: 109 strs += st + "。" 110 strs = strs.replace("。。", "。") 111 return strs 112 113 # 取得带有 日期 的句子之前的句子 114 @staticmethod 115 def ut_date(stri): 116 lines = str(stri).split("。") 117 strs = "" 118 num = lines.__len__() 119 for i in range(0, num): 120 st = str(lines[i]) 121 if (st.__contains__("年")| st.__contains__("月")): 122 break 123 else: 124 strs += st + "。" 125 strs = strs.replace("。。","。") 126 return strs 127 128 @staticmethod 129 def beat(stri,num): 130 strs = str(stri) 131 for i in range(0,num): 132 strs = strs.replace("["+str(i)+"]","") 133 134 return strs 135 136 137 # [写文件的方法集合] 138 class StringWriter: 139 filePath = "" 140 141 def __init__(self,str): 142 self.filePath = str 143 pass 144 145 def makeFileNull(self): 146 f = codecs.open(self.filePath, "w+", 'utf-8') 147 f.write("") 148 f.close() 149 150 def write(self,stri): 151 f = codecs.open(self.filePath, "a+", 'utf-8') 152 f.write(stri + " ") 153 f.close() 154 155 156 # [ 连续网页爬取的对象 ] 157 class WebConnector: 158 profile = "" 159 sw = "" 160 161 # ---[定义构造方法] 162 def __init__(self): 163 self.profile = webdriver.Firefox() 164 self.profile.get('https://baike.baidu.com/') 165 # self.sw = StringWriter("../testFile/rc/moreinfo.txt") 166 # self.sw.makeFileNull() 167 168 # ---[定义释放方法] 169 def __close__(self): 170 self.profile.quit() 171 172 # 获取 url 的内部 HTML 代码 173 def getHTMLText(self): 174 a = self.profile.page_source 175 return a 176 177 # 获取页面内的基本链接 178 def getFirstChanel(self): 179 try: 180 index_html = self.getHTMLText() 181 index_sel = parsel.Selector(index_html) 182 links = index_sel.css('.lemma-summary').extract()[0] 183 tpl = StrSpecialDealer.simpleDeal(str(links)) 184 tpl = StrSpecialDealer.beat(tpl, 20) 185 tpl = StrSpecialDealer.deleteRe(tpl) 186 tpl = StrSpecialDealer.ut_date(tpl) 187 return tpl 188 except: 189 return "" 190 191 def getMore(self,refers): 192 self.profile.find_element_by_id("query").clear() 193 self.profile.find_element_by_id("query").send_keys(refers) 194 self.profile.find_element_by_id("search").click() 195 time.sleep(1) 196 197 198 def main(): 199 ftwac = FileToWebAndContent("../testFile/rc/output.txt", "../testFile/rc/moreinfo.txt") 200 ftwac.__deal__() 201 ftwac.__free__() 202 203 204 main()
对应得到文件截图: