会一步一步剖析这个怎么使用,抛砖引玉,
paddle.dataset.mnist:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/data/dataset_cn/mnist_cn.html
paddle.batch:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/io_cn/batch_cn.html#batch
MNIST数据集。(手写数字图像)
- 会自动从 http://yann.lecun.com/exdb/mnist/ 下载数据集
- 将训练集和测试集解析为paddle reader creator
- reader中的每个样本的图像像素范围是[-1,1],标签范围是[0,9]
import numpy as np
import paddle as paddle
import paddle.dataset.mnist as mnist
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
def load_image(im):
im = np.array(im).reshape(28, 28).astype(np.float32)
return im
def show(img):
plt.imshow(img)
plt.show()
# 得到mnist.train()的迭代函数.reader()
a=mnist.train()
# 对a迭代一次,返回给b
b=next(a())
# a:<function paddle.dataset.mnist.reader_creator.<locals>.reader()>
# len(b):2
# 返回的是一个图像数据,及其标签:5
# b[0].shape,b[1]:(784,), 5
# 一个批次的读取,每个批次读4个图像数据,返回一次返回一个批次的.reader()
train_reader = paddle.batch(mnist.train(), batch_size=4)
test_reader = paddle.batch(mnist.test(), batch_size=4)
# 进行迭代,此时一次返回4个数据
for batch_id, data in enumerate(train_reader()):
print(len(data))
break
# 图像像素范围是[-1,1],标签范围是[0,9]
# data[0]: 0号样本
# data[0][0]: 0号样本 的数据
# data[0][1]: 0号样本的label
# data[0][0].shape,data[0][1]:(784,), 5
# 每个样本的图像像素范围是[-1,1],标签范围是[0,9]
# data[0][0].all()>=-1 and data[0][0].all()<=1:True
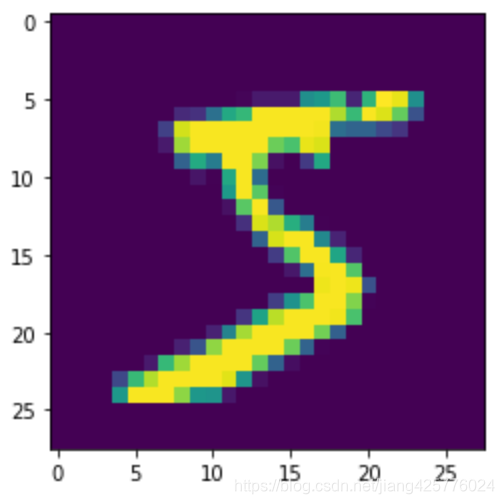
# number 0 image ,label is 5
label=data[0][1]
# label:5
# 转换784长向量变成一个正常2d图像数据:28 x 28
img=load_image(data[0][0])
# img.shape:(28, 28)
# 展示这个图像数据
show(img)
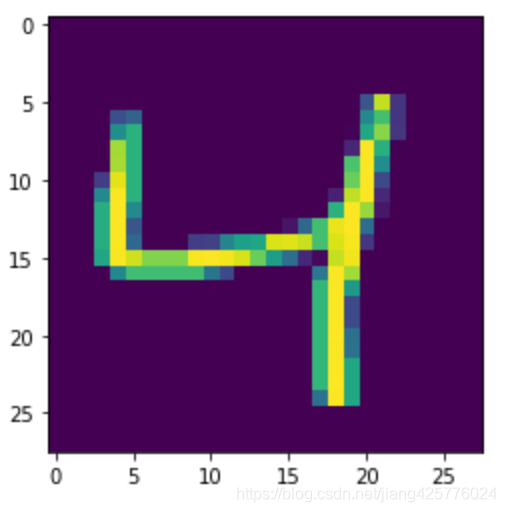
label=data[2][1]
# label:4
img=load_image(data[2][0])
show(img)