目录
2.1SLSQP(Sequential Least SQuares Programming optimization algorithm)
2.2最小二乘最小化Least-squares minimization
scipy api:https://docs.scipy.org/doc/scipy-0.18.1/reference/index.html
优化器optimize的参数设置:https://docs.scipy.org/doc/scipy-0.18.1/reference/optimize.html#module-scipy.optimize
0.scipy.optimize.minimize
scipy.optimize.minimize(fun, x0, args=(), method=None, jac=None, hess=None, hessp=None, bounds=None, constraints=(), tol=None, callback=None, options=None)
fun:目标函数,返回单值,
x0:初始迭代点,
method:求解方法
- ‘Nelder-Mead’ (see here)
- ‘Powell’ (see here)
- ‘CG’ (see here)
- ‘BFGS’ (see here)
- ‘Newton-CG’ (see here)
- ‘L-BFGS-B’ (see here)
- ‘TNC’ (see here)
- ‘COBYLA’ (see here)
- ‘SLSQP’ (see here)
- ‘dogleg’ (see here)
- ‘trust-ncg’ (see here)
jac:目标函数的雅可比矩阵。可选的。仅适用于CG,BFGS,Newton-CG,L-BFGS-B,TNC,SLSQP,dogleg,trust-ncg。如果jac是布尔值并且为True,则假定fun会返回梯度以及目标函数。如果为False,将以数字方式估计梯度。jac也可以是一个可调用的,返回目标的梯度。在这种情况下,它必须接受与fun相同的参数。
hess:可选的,目标函数的Hessian(二阶导数矩阵)或目标函数的Hessian乘以任意向量p。仅适用于Newton-CG,dogleg,trust-ncg。只需要给出hessp或hess中的一个。如果提供了hess,那么hessp将被忽略。如果没有提供hess和hessp,那么将使用jac上的有限差分来近似Hessian乘积。hessp必须将Hessian时间计算为任意向量。
bounds:序列,可选变量的界限(仅适用于L-BFGS-B,TNC和SLSQP)。(min,max)对x中每个元素的对,定义该参数的边界。
constraints:约束,类型有: ‘eq’ for equality, ‘ineq’ for inequality,如:constraints=cons
cons = ({'type': 'eq',
'fun' : lambda x: np.array([x[0]**3 - x[1]]),
'jac' : lambda x: np.array([3.0*(x[0]**2.0), -1.0])},
{'type': 'ineq',
'fun' : lambda x: np.array([x[1] - 1]),
'jac' : lambda x: np.array([0.0, 1.0])})callback(xk):每次迭代召唤函数,需要有参数xk.
options : 字典可选,
#容忍精度,是否打印,
options={'xtol': 1e-2, 'disp': True}1.无约束最小化多元标量函数
1.1Nelder-Mead(单纯形法)
函数Rosenbrock :
def rosen(x):
"""The Rosenbrock function"""
return sum(100.0 * (x[1:] - x[:-1] ** 2.0) ** 2.0 + (1 - x[:-1]) ** 2.0)求解:
import numpy as np
from scipy.optimize import minimize
def callback(xk):
print(xk)
# 初始迭代点
x0 = np.random.rand(10) * 2
# 最小化优化器,方法:Nelder-Mead(单纯形法)
res = minimize(rosen, x0, method='nelder-mead',
options={'xtol': 1e-2, 'disp': True}, callback=callback)
print(res.x)
#
Optimization terminated successfully.
Current function value: 0.036794
Iterations: 521
Function evaluations: 769
[1.00107996 1.00207144 1.00207692 1.00489278 1.00985838 1.0192085
1.03896708 1.08001283 1.16669137 1.36167574]1.2拟牛顿法:BFGS算法
拟牛顿法的核心思想是构造目标函数二阶导数矩阵黑塞矩阵的逆的近似矩阵,避免了解线性方程组求逆的大量计算,更加高效。介绍:https://blog.csdn.net/jiang425776024/article/details/87602847
函数Rosenbrock :
def rosen(x):
"""The Rosenbrock function"""
return sum(100.0 * (x[1:] - x[:-1] ** 2.0) ** 2.0 + (1 - x[:-1]) ** 2.0)导数:
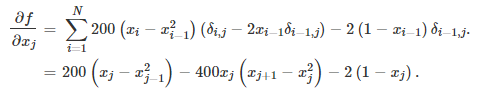

def rosen_der(x):
# rosen函数的雅可比矩阵
xm = x[1:-1]
xm_m1 = x[:-2]
xm_p1 = x[2:]
der = np.zeros_like(x)
der[1:-1] = 200 * (xm - xm_m1 ** 2) - 400 * (xm_p1 - xm ** 2) * xm - 2 * (1 - xm)
der[0] = -400 * x[0] * (x[1] - x[0] ** 2) - 2 * (1 - x[0])
der[-1] = 200 * (x[-1] - x[-2] ** 2)
return der求解:
import numpy as np
from scipy.optimize import minimize
# 初始迭代点
x0 = np.random.rand(10) * 2
res = minimize(rosen, x0, method='BFGS', jac=rosen_der,
options={'disp': True})
print(res.x)
1.3牛顿法:Newton-CG
利用黑塞矩阵和梯度来优化,介绍:https://blog.csdn.net/jiang425776024/article/details/87601854
函数Rosenbrock :
构造目标函数的近似二次型(泰勒展开):
利用黑塞矩阵H和梯度做迭代
黑塞矩阵:

def rosen_hess(x):
x = np.asarray(x)
H = np.diag(-400*x[:-1],1) - np.diag(400*x[:-1],-1)
diagonal = np.zeros_like(x)
diagonal[0] = 1200*x[0]**2-400*x[1]+2
diagonal[-1] = 200
diagonal[1:-1] = 202 + 1200*x[1:-1]**2 - 400*x[2:]
H = H + np.diag(diagonal)
return H实现:
import numpy as np
from scipy.optimize import minimize
def rosen_hess(x):
x = np.asarray(x)
H = np.diag(-400 * x[:-1], 1) - np.diag(400 * x[:-1], -1)
diagonal = np.zeros_like(x)
diagonal[0] = 1200 * x[0] ** 2 - 400 * x[1] + 2
diagonal[-1] = 200
diagonal[1:-1] = 202 + 1200 * x[1:-1] ** 2 - 400 * x[2:]
H = H + np.diag(diagonal)
return H
# 初始迭代点
x0 = np.random.rand(10) * 2
res = minimize(rosen, x0, method='Newton-CG',
jac=rosen_der, hess=rosen_hess,
options={'xtol': 1e-8, 'disp': True})
print(res.x)
2 约束最小化多元标量函数
2.1SLSQP(Sequential Least SQuares Programming optimization algorithm)
形如:

例子:

def func(x, sign=1.0):
""" Objective function """
return sign * (2 * x[0] * x[1] + 2 * x[0] - x[0] ** 2 - 2 * x[1] ** 2)
# 导数,可有可无,可选的
def func_deriv(x, sign=1.0):
""" Derivative of objective function """
dfdx0 = sign * (-2 * x[0] + 2 * x[1] + 2)
dfdx1 = sign * (2 * x[0] - 4 * x[1])
return np.array([dfdx0, dfdx1])
# 约束
cons = ({'type': 'eq',
'fun': lambda x: np.array([x[0] ** 3 - x[1]]),
'jac': lambda x: np.array([3.0 * (x[0] ** 2.0), -1.0])},
{'type': 'ineq',
'fun': lambda x: np.array([x[1] - 1]),
'jac': lambda x: np.array([0.0, 1.0])})实现:
import numpy as np
from scipy.optimize import minimize
res = minimize(func, [-1.0, 5.0], args=(-1.0,), jac=func_deriv,
constraints=cons, method='SLSQP', options={'disp': True})
print(res.x)
2.2最小二乘最小化Least-squares、leastsq
leastsq(最小化一组方程的平方和):https://blog.csdn.net/jiang425776024/article/details/86801232
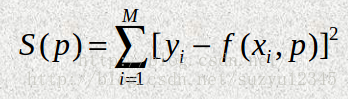
Least-squares(求解带变量边界的非线性最小二乘问题):
形如:
例:

def model(x, u):
return x[0] * (u ** 2 + x[1] * u) / (u ** 2 + x[2] * u + x[3])导数:
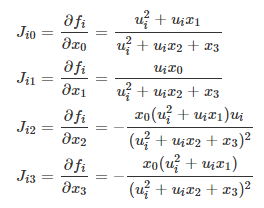
拟合显示:
from scipy.optimize import least_squares
import numpy as np
#原函数
def model(x, u):
return x[0] * (u ** 2 + x[1] * u) / (u ** 2 + x[2] * u + x[3])
#损失函数
def fun(x, u, y):
return model(x, u) - y
#原函数的一阶导数,雅可比矩阵,可选
def jac(x, u, y):
J = np.empty((u.size, x.size))
den = u ** 2 + x[2] * u + x[3]
num = u ** 2 + x[1] * u
J[:, 0] = num / den
J[:, 1] = x[0] * u / den
J[:, 2] = -x[0] * num * u / den ** 2
J[:, 3] = -x[0] * num / den ** 2
return J
#训练数据x轴
u = np.array([4.0, 2.0, 1.0, 5.0e-1, 2.5e-1, 1.67e-1, 1.25e-1, 1.0e-1,
8.33e-2, 7.14e-2, 6.25e-2])
#参考真实值y
y = np.array([1.957e-1, 1.947e-1, 1.735e-1, 1.6e-1, 8.44e-2, 6.27e-2,
4.56e-2, 3.42e-2, 3.23e-2, 2.35e-2, 2.46e-2])
#初始点,系数
x0 = np.array([2.5, 3.9, 4.15, 3.9])
#边界量0-100
res = least_squares(fun, x0, jac=jac, bounds=(0, 100), args=(u, y), verbose=1)
print(res.x)
import matplotlib.pyplot as plt
#测试数据x
u_test = np.linspace(0, 5)
#测试结果y
y_test = model(res.x, u_test)
#原数据
plt.plot(u, y, 'o', markersize=4, label='data')
#预测拟合结果
plt.plot(u_test, y_test, label='fitted model')
plt.xlabel("u")
plt.ylabel("y")
plt.legend(loc='lower right')
plt.show()
3.单变量函数最小化器
from scipy.optimize import minimize_scalar
f = lambda x: (x - 2) * (x + 1)**2
res = minimize_scalar(f, method='brent')
print(res.x)
4.有界最小化
from scipy.special import j1
res = minimize_scalar(j1, bounds=(4, 7), method='bounded')
res.x
5.定制自己的最小化器
from scipy.optimize import OptimizeResult
from scipy.optimize import minimize
import numpy as np
def rosen(x):
"""The Rosenbrock function"""
return sum(100.0 * (x[1:] - x[:-1] ** 2.0) ** 2.0 + (1 - x[:-1]) ** 2.0)
def custmin(fun, x0, args=(), maxfev=None, stepsize=0.1,
maxiter=100, callback=None, **options):
bestx = x0
besty = fun(x0)
funcalls = 1
niter = 0
improved = True
stop = False
while improved and not stop and niter < maxiter:
improved = False
niter += 1
for dim in range(np.size(x0)):
for s in [bestx[dim] - stepsize, bestx[dim] + stepsize]:
testx = np.copy(bestx)
testx[dim] = s
testy = fun(testx, *args)
funcalls += 1
if testy < besty:
besty = testy
bestx = testx
improved = True
if callback is not None:
callback(bestx)
if maxfev is not None and funcalls >= maxfev:
stop = True
break
return OptimizeResult(fun=besty, x=bestx, nit=niter,
nfev=funcalls, success=(niter > 1))
x0 = [1.35, 0.9, 0.8, 1.1, 1.2]
res = minimize(rosen, x0, method=custmin, options=dict(stepsize=0.05))
print(res.x)
6.找根
1)f(x)=0的根
![]()
import numpy as np
from scipy.optimize import root
def func(x):
return x + 2 * np.cos(x)
sol = root(func, 0.3)
print(sol.x, sol.fun)
2)两个等式的根
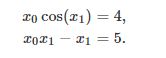
import numpy as np
from scipy.optimize import root
def func2(x):
f = [x[0] * np.cos(x[1]) - 4,
x[1]*x[0] - x[1] - 5]
df = np.array([[np.cos(x[1]), -x[0] * np.sin(x[1])],
[x[1], x[0] - 1]])
return f, df
sol = root(func2, [1, 1], jac=True, method='lm')
print(sol.x, sol.fun)