一:通过sorted函数或者列表的sort函数和lambda表达式对下列列表按score排序
list_a = [
{"name":"p1","sore":100},
{"name":"p2","sore":10},
{"name":"p3","sore":30},
{"name":"p4","sore":20},
{"name":"p5","sore":80},
{"name":"p6","sore":70},
{"name":"p7","sore":60},
{"name":"p8","sore":40},
]
答案:
list_a = [ {"name":"p1","sore":100}, {"name":"p2","sore":10}, {"name":"p3","sore":30}, {"name":"p4","sore":20}, {"name":"p5","sore":80}, {"name":"p6","sore":70}, {"name":"p7","sore":60}, {"name":"p8","sore":40}, ]; list_a.sort(function(a,b){ return a.sore-b.sore; }); console.log(list_a) 显示答案:
2:js里面的json字符串和对象互相转换:
JSON对象 var str1 = '{"name": "chao", "age": 18}'; var obj1 = {"name": "chao", "age": 18}; // JSON字符串转换成对象 var obj = JSON.parse(str1); // 对象转换成JSON字符串 var str = JSON.stringify(obj1);
3:下列函数那些传参正确(ABDF)多选题
def f(a,b,c='1',d='2',*args,**kwargs): pass #A f(1,2,) #B f(b=1,a=2) #C # f(a=1,2,c=1) #位置参数应遵循关键字传参 #D f(1,2,d=3,f=4) #E # f(*(1,2),**{'c':1,'d':2,'a':5})#参数a获得了多个值 #F f(*(1,),**{'c':1,'d':2,'b':5})
4:通过sorted函数或者列表的sort函数和lambda表达式对下列列表按score排序
''' 排序函数. 语法: sorted(Iterable, key=None, reverse=False) Iterable: 可迭代对象 key: 排序规则(排序函数), 在sorted内部会将可迭代对象中的每⼀个元素传递给这个函数的参数. 根据函数运算的结果进⾏排序 reverse: 是否是倒叙. True: 倒叙, False: 正序 ''' list_a = [ {"name": "p1", "sore": 100}, {"name": "p2", "sore": 10}, {"name": "p3", "sore": 30}, {"name": "p4", "sore": 20}, {"name": "p5", "sore": 80}, {"name": "p6", "sore": 70}, {"name": "p7", "sore": 60}, {"name": "p8", "sore": 40}, ] print(sorted(list_a,key=lambda e:e["sore"],reverse=True))
衍生:
filter()
''' filter()函数 筛选函数 语法: filter(function,Iterable) function: ⽤来筛选的函数. 在filter中会⾃动的把iterable中的元素传递给function. 然后 根据function返回的True或者False来判断是否保留此项数据 Iterable: 可迭代对象 ''' lst = [1,2,3,4,5,6,7] # 筛选偶数出来 lst2=filter(lambda a:a%2==0,lst) # 得到一个对象 print(lst2) # <filter object at 0x0000008FAA1BE828> print(list(lst2))
配合lamda函数使用filter()
lst = [{"id":1, "name":'aa', "age":18},
{"id":2, "name":'bb', "age":16},
{"id":3, "name":'cc', "age":17}]
a_lst=filter(lambda e:e["age"],lst) # 得到一个对象
print(list(a_lst))
# [{'id': 1, 'name': 'aa', 'age': 18},
# {'id': 2, 'name': 'bb', 'age': 16},
# {'id': 3, 'name': 'cc', 'age': 17}]
map函数:
''' 映射函数 语法: map(function, iterable) 可以对可迭代对象中的每⼀个元素进⾏映射. 分别取执⾏ function ''' def func(e): return e * e mp = map(func, [1, 2, 3, 4, 5, 6]) # 配合lamda函数进行使用 a_mp=map(lambda e:e*e,mp) print(a_mp) # 对象 <map object at 0x0000006795A6E908> bb=list(a_mp) # [1, 16, 81, 256, 625, 1296] print(bb) # [1, 16, 81, 256, 625, 1296] print(bb.reverse()) # f返回None print(list(reversed(bb))) # reversed()将⼀个序列翻转, 返回翻转序列的迭代器 # [1, 16, 81, 256, 625, 1296]
# 用map和lamda计算两个列表相同位置的和
lst1 = [1, 2, 3, 4, 5]
lst2 = [2, 4, 6, 8, 10]
lst3=map(lambda x,y:x+y,lst1,lst2)
print(lst3) # <map object at 0x000000D4D771E898>
print(list(lst3)) # [3, 6, 9, 12, 15]
''' reverse() 函数用于反向列表中元素。 reverse() 该方法没有返回值,但是会对列表的元素进行反向排序。 语法:list.reverse() ''' lit=[2,4,6,7,9] lit.reverse() print(lit) # [9, 7, 6, 4, 2]
reverse()和reversed()的基本比较
# lit=[2,4,6,9] # print(list(reversed(lit))) # # [9, 6, 4, 2] lit=[2,4,6,9] print(lit.reverse()) # None print(lit) # [9, 6, 4, 2] # 总结: reversed(可迭代对象) 返回的是一个新的可迭代对象,需要用print(list(reversed(lit)))进行打印出来 lit.reverse()是在原来的列表上将列表进行反转,不会产生新的列表,所以print(lit.reverse())打印的是一个None
#递归
在函数中调⽤函数本⾝. 就是递归
def fun(n): print(n) n+=1 fun(n) fun(1) 在python中递归的深度最⼤到998 ''' 1 ... 993 994 995 996 997 998 '''
5:一行代码,通过filter 和 lamdba 函数输出以下列表索引为奇数对应的元素(生成器和列表推导式,配合的例题)
list_b = [12, 213, 22, 2, 2, 2, 22, 2, 2, 32, ] '''' 分析过程: a=enumerate(list_b) print(list(a)) # [(0, 12), (1, 213), (2, 22), (3, 2), (4, 2), (5, 2), (6, 22), (7, 2), (8, 2), (9, 32)] cc=filter(lambda a:a[0]%2==1,enumerate(list_b)) dd=list(cc) print(dd) # [(1, 213), (3, 2), (5, 2), (7, 2), (9, 32)] print(type(dd)) # <class 'list'> print(len(dd)) # 5 ''' # 配合lambda函数和filter函数进行,还有列表推导式的结果是: ''' 列表推导式的常⽤写法: [ 结果 for 变量 in 可迭代对象] 例. 从python1期到python14期写入列表lst: lst = ['python%s' % i for i in range(1,15)] print(lst) ⽣成器表达式和列表推导式的语法基本上是⼀样的. 只是把[]替换成() gen = (i for i in range(10)) print(gen) 结果: <generator object <genexpr> at 0x106768f10> ''' new_list = [a[1] for a in filter(lambda a: a[0] % 2 == 1, enumerate(list_b))] # print(new_list)
6:对记录进行去重对mygame 表gname ,userid 相同的记录进行去重例如表中记录如下
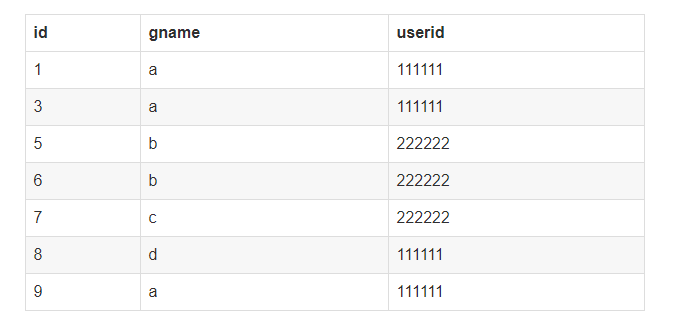
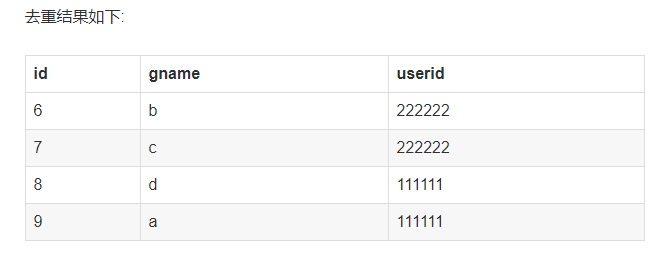
表结构如下:
CREATE TABLE mygame( `id` int(11) NOT NULL AUTO_INCREMENT, `gname` VARCHAR(50) DEFAULT NULL, `userid` int(11) DEFAULT NULL, `create_datetime` datetime DEFAULT NULL, PRIMARY KEY(`id`) )ENGINE=INNODB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8
答案:
mysql> select * from mygame where id in (select max(id) from mygame group by gname) order by id; +----+-------+--------+-----------------+ | id | gname | userid | create_datetime | +----+-------+--------+-----------------+ | 6 | b | 222222 | NULL | | 7 | c | 222222 | NULL | | 8 | d | 111111 | NULL | | 9 | a | 111111 | NULL | +----+-------+--------+-----------------+ 4 rows in set (0.00 sec)