背景
使用RDMA在DC中的两个问题(1)固定内存(按message的大小)的分配方式导致内存浪费;(2)对于随机数量随机大小的message在典型的数据中心中对比较程序员造成非常大的负担。
我们提出了RIMA,(1)NIC微体系结构支持新的队列原语;(2)一个新的“append” verb相比与RDMA,有更小的内存消耗,编程更加友好
介绍
在管理通信中,内存分配是一个关键性的挑战。TCP使用一个共享的临时buffer对于容纳多条消息的包,然后通过OS传给具体的进程。由于buffer是跨进程共享的,分配的buffer可以很小但是需要OS的介入,这个就非常慢;相反RDMA的read/write单边操作模型,预先分配的buffer是私有并且固定大小的。对多个发送者来说共享一个区域是不可能的,因为一个发送者的数据可能在读之前被覆盖(这就是arb-src限制)。更进一步的数目和大小限制,分配的最小内存必须是非常大的。与RDMA的单表模型相反,双边模型需要接受者在message到达之前主动预先分配内存缓冲区,接收队列可以在多个接收者这件共享,这缓解了arb-src的限制。
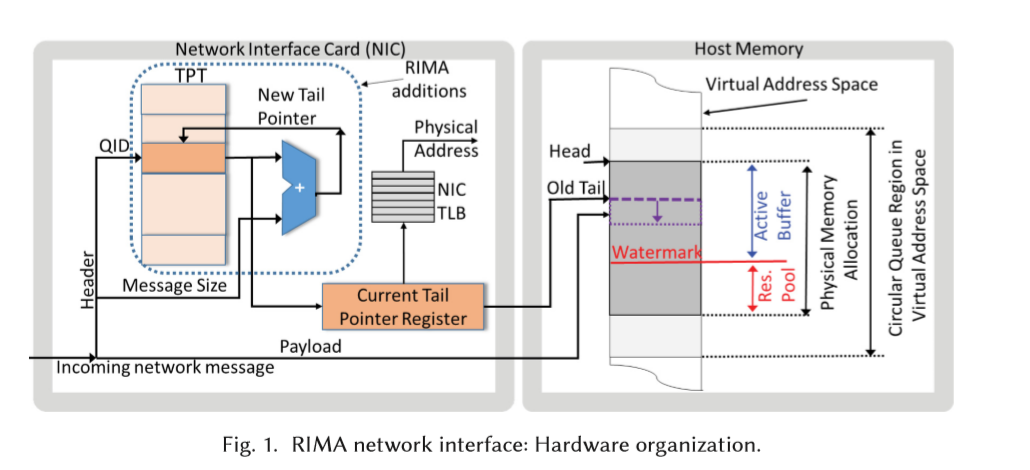
我们提出了RIMA作为一个更适合的数据中心间的传输原语。在接收者,append 消息查找队列的的尾指针并且自动的增加尾指针按照message的大小,然后复制这个消息到创建的环形队列中,尾指针在接收者的虚地址空间中。和RDMA一样,NIC提供地址转换、保护等功能。头指针操作是简单的,RIMA一个小的查表和adder增加了1-2ns的延迟。
尾部指针征粮假设了预先分配的内存缓冲区,RIMA确保内存在后台分配并且不影响message的延迟
背景知识
IB内存开销
QP是IB通信的核心原语,和TCP/IP sockets类似. 每一个QP有发送队列和接受队列组成。所有的源和目的节点都必须创建QP来通信。
两个著名的IB传输模型是:可靠连接(RC)和不可靠无连接(UD),这与TCP和UDP非常相似,在RC模型中,数据通信之前需要建立连接,然而在UD模型中,不需要预先建立来连接,任意一个QP都可以与其他QP进行通信。
使用IB的应用有两个主要的内存消耗来源:
IB的作用域内存:内存被分配用来进行IB通信,如QP等。一个单独的QP消耗68K的内存在MVAPICH中,作用域内存是IB扩展性的一个瓶颈。使用DCT,RC模型的作用域内存可以被最小化,因为一个单独的DCT QP可以与多个QP之间通信,作用域内存不会给UD带来问题,因为他是无连接的
数据Buffer内存:数据buffer内存存储计划通信的数据。在接收到来的message之前,这样的内存区域需要预先在物理内存中分配。虽然按需分配可以延迟分配物理内存,但是这仅仅对在程序的不同阶段是有意义的(不需要理解接受数据)每一个buffer至少消耗一个page,RIMA集中与数据buffer开销,这存在于RC和UD中。
在IB编程中,read/write被称为原语(单边),接收者没有意识到发起者的读和写操作。在内存中的数据buffer是不共享的,因为在多个发送者间潜在的竞争导致写向相同的buffer,避免竞争需要每一个发送者拥有一个buffer,这会导致内存空间上升等等,当拥有大量的发送者时,这是不可扩展的。
为了降低每一个接收者的内存开销,IB提出了SRQ,使用双边通信。SRQ让多个QPs共享同一片内存区域。然而接收者必须预先post能够容纳消息的足够大小。如果message的size超过了pre-psot的size,就会报错。不幸的是,一个SRQ仅仅可以处理一个单独的message size。sender不知道在receiver中下一个可用buffer的大小,接收者按照发布的顺序消耗buffer,为了使receive能够处理多个message大小,需要让receiver预先知道未来message的size
RIMA替代品
RIMA需要改变硬件(虽然很小)。因此有必要考虑软件替代管理内存空间的问题。
Single SRQ:尽管跨QP共享数据buffer,SRQ仍然造成严重的开销由于他单个的size限制。message的大小变化范围很大。一个naive的方式使用单个SRQ,并且使用最大的message size
Multi-SRQ:另一种方式使用多个不同size的队列,这种方式会降低可编程性,给定一个消息的size分布,找到最优的buffer size,最小化内存空间不是那么直接的(不简单)有两个内存组件:
(1)队列的活跃部分,容纳消息,并且在服务之前,通过平均消息到达速率以及服务时间确定size的大小
(2)reserve pool 防止活跃部分由于慢的服务被填满,这个pool的size对于一个给定的message size通过message到达速率来确定
使用最大buffer的SRQ,其第一个组件将是非常大的,而更多的队列被使用,更加接近于message的size 第二个组件就会增加。
使用verb用固定内存占用进行管理
最近很多paper争论在数据中心的RDMA,但是他们仅仅使用已有的verb来考虑已有的限制(arb-*),作者认为对于大规模,非请求响应message,RDMA可能使更好的选择,作者并不期望在所有的场景中都代替RDMA,RIMA在请求/相应流量中使更加好的
RIMA
从概念上讲,RIMA实现了队列语义,例如:单边的非直接通信,通过(1)使用间接层来规定消息的目的内存地址(2)增加尾指针以容纳输入message。作者描述了RIMA的设计在编程接口和网卡操作方面
RIMA Interface
程序员可以创建和销毁RIMA请求在receiver端。队列的ID必须被传输(或许通过TCP/IP)到潜在的发送端每一个队列提供一个单独的远程操作:发送一个任意大小的消息到一个远端队列(目标主机)使用RIMA,发送者使非常用以混合不同大小的消息。应用不需要任何同步操作。虽然RIMA message大小的独立性意味着它不需要多条队列,但是程序员可以使用多条队列从逻辑上区分通信通道或者为了减少数据量,例如应用的控制message和数据message在不同的队列中。
Interface Details
RIMA的接口是基于IB的DCT框架,RIMA的append队列(AQ)是适合于SRQ的
RIMA NIC Microarchitecture