- 需求分析
- 用户请求量太大 -> 分布式服务器(分散请求到多个服务器上)
- 单库太大 单库所在服务器上磁盘空间不足;处理能力有限;出现IO瓶颈
- 单表太大 -> CRUD都成问题, 索引膨胀, 查询超时
- 作用
- 共同组成完整的数据集合, 扩充单机存储的容量上限, 读写速度上限
- 每个服务器节点称为分片
- 优点 高吞吐
- 吞吐量越高, 同一时间数据的读写完成量越高
- 一个节点可能单日吞吐量只能到达1TB(受硬件限制, 硬盘速度有限)
垂直拆分
- 垂直分表
- 按字段将一张表拆分成多张表
- 垂直分库
- 将一个数据库中的多张表拆分到多个数据库(节点)中
- 项目处理
- 用户数据垂直分表 user_basic user_profile
- 文章数据垂直分表(文章内容较长且只在详情页才需要) article_basic article_content
- 后续如果垂直分库
- 需要将有关联性的表放在同一个库中, 比如用户相关的放在数据库1, 文章相关的放在数据库2
水平拆分
- 水平分表
- 将1000万条记录分成两张表
- 分表方式 按时间/id/地理/hash取模 分表
- 水平分库分表 水平分表后, 将分表分散放在多个数据库节点
- 分布式ID
- 需求: 水平分表后, 需要保证多表id不会出现冲突
- 解决方案
- UUID 通用唯一识别码 缺点: 较长,不会趋势递增(主键如果不是递增的, 索引效率会比较低)
- 数据库主键自增
- 方案1 单独数据库 只负责生成主键 缺点:一旦宕机, 全局瘫痪
- 方案2 设置自增步长 所有表都使用相同的步长 缺点: 分片规则不能修改, 无法扩展
- Redis
- incr("user_id") 返回的值自增
- 不会出现资源抢夺问题, 因为redis是单线程的, 可以保证原子性
- 缺点
- redis宕机
- redis易数据丢失
- 雪花算法-Snowflake
-
twitter提出的算法, 目的是生成一个64位的整数
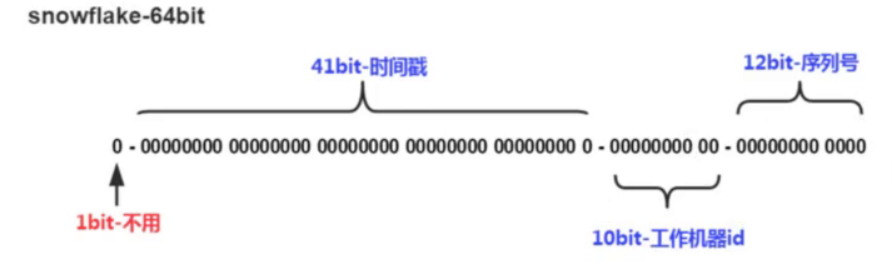
-
缺点: 时间回拨, 机器的原因时间可能出现偏差, 虽然会同步进行校正, 但生成时可能是错误的
- 如果发生回拨(当前时间<记录的时间),算法会自动抛出异常, 可以让用户稍等一会儿
- 取消同步ntp时间
-
项目中的应用
- 用户id 文章id 评论id 后期数据量可能会很大
-
- 前期数据量和请求次数少时, 不要做分片