3.13.4 控制
x86-64的控制指令和IA32没区别, 另外对应的增加了cmpq和testq而已, 其他一些与位无关的指令保存原样. 另外一点区别在于, gcc对于x86-64既会使用条件控制转移又使用条件控制传送, 因为x86-64所以的机器都支持条件传送, 所以不用考虑使用条件传送会导致机器不兼容的问题. 所以对于循环而言x86-64反而与IA32区别不大 :

至于第11行的rep指令, 书中也给出了解释, 但是我似乎不太懂, 大概是说跳转指令如果目的指令直接就是ret的话预测不了ret指令后面的指令(CPU实际是多条指令并行执行的), 加上rep可以提高效率...

练习题3.49本身不难, 但是就算成功的翻译出来了也很难看出这段代码到底想要做什么, 反正我是没看懂, 后来寻求了他人帮助之后也算懂了... 这是翻译出来的C代码 :

它其实是将64位分成8个小单元, 然后8个小单元里面分别求位的和, 因为循环8次, 正好可以把8个小单元的和全部求出来(这个和最大只能是8, 所以不用担心8位存不下这个值), 求出来之后, 先对半折叠的作用是将高32位里面的4个小单元里面的和加到第32位中, 每个单元的值最多是16显然也不会放不下. 此时只需要考虑第32位就行了, 因为值已经被转移到了第32位中, 然后继续折叠, 在折叠, 这样值全部放在了低8位中, 此时最多也就64, 另一方面我们取值的时候只需要考虑低8位即可, 所以最后使用了掩码0xFF来取出第8位的值...
1. 过程
由于寄存器数量翻倍, 所以过程的实现在x86-64中与之前有很大的不同 :
1. 参数通过寄存器传递到过程, 而不是栈.(参数过多除外)
2. callq指令将一个64位的返回地址存储在栈上.
3. 由于帧指针没有了, 所以一般栈位置引用就靠栈指针, 所以函数一开始就需要分配整个栈所需的空间以此来保持栈指针指向固定位置.
4. 函数最多可以访问超过当前栈指针位置128字节的空间(也就是可以访问还没有分配的空间), 这使得我们可以在栈上存储信息而不需要改变栈指针的位置.
5. 被调用者保存寄存器也需要修改前保存再使用.
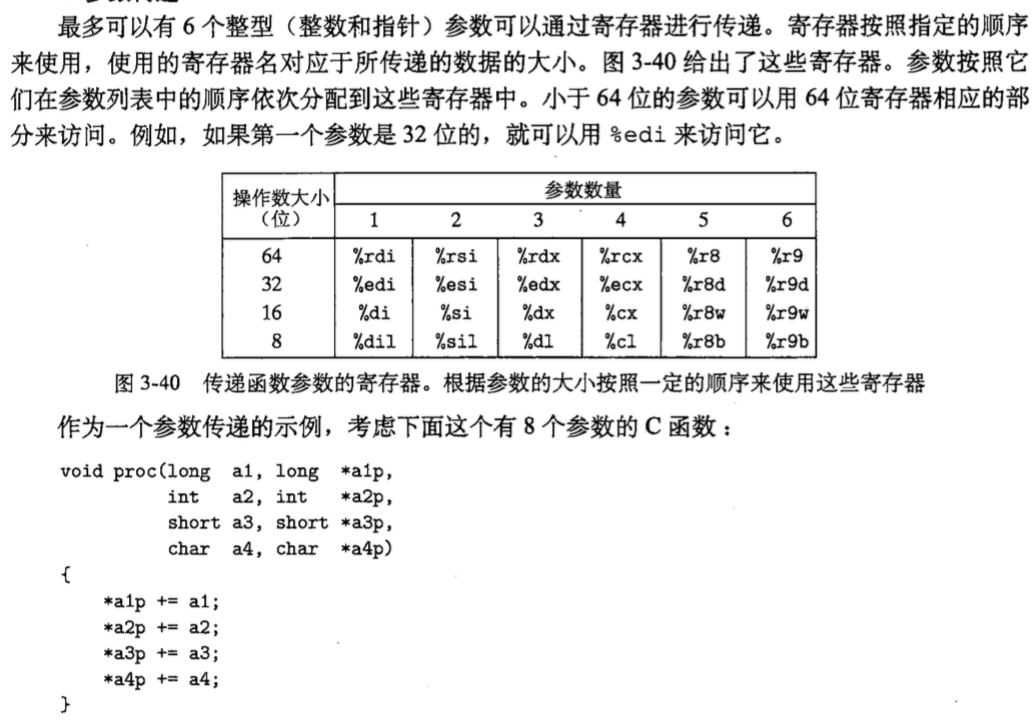
2. 参数传递
上面我们说到参数一般通过寄存器传递, 这里来细说一下 :

3.栈帧
虽然x86-64对于栈的依赖的降低, 但是还是有一些原因可能需要栈帧 :
1. 保存返回地址
2. 局部变量太多, 寄存器不够用.
3. 使用了数组或者结构
4. 被调用者寄存器需要被修改时, 必须先在栈上保存.
5. 函数使用&取地址时
另一方面, 要记住在x86-64中栈指针%rsp的位置相对固定, 从而可以用相对于栈指针的偏移量来访问数据.
下面给出一个实际的例子 :


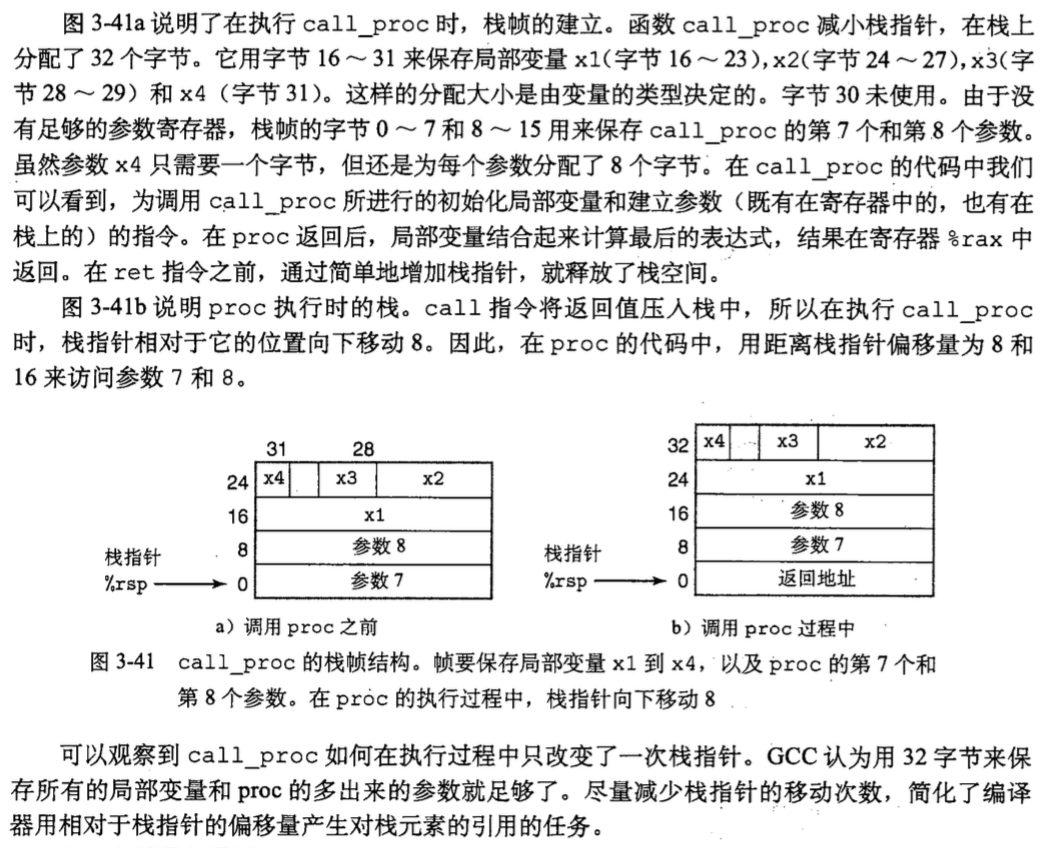
这里书上说的很清楚, 我就不多赘述了...
4. 寄存器保存惯例
在IA32中, %eax, %edx, %ecx是调用者保存寄存器, %ebx, %esi, %edi是被调用者保存寄存器, 而在x86-64中, 调用者保存寄存器只有%r10和r11%, 被调用者保存寄存器有6个 : %rbx, %rbp, %r12~%r15. 剩下的几个%rax用来作为函数返回值, %rsp作为栈指针, %rdi, %rsi, %rdx, %rcx, %r8, %r9用来传递参数. (个人认为虽然%rax用来作为函数返回参数, 但是在调用的时候也依然是调用者保存寄存器才对...)
当然, 上面这些惯例是在寄存器不够用的情况下, 一般情况下, 没有被使用的传参寄存器也可以使用, %rax也可以在返回之前被重复利用...
3.13.5 数据结构
x86-64和IA32在数组, 结构等方面其实几乎相同, 除了x86-64遵循一组更加严格的对齐要求 :

可能是翻译的缘故, 这段话我也不是很理解, 不过看下习题之后应该大概了解了 :

这几个的对齐分别是 8, 8, 2, 8, 8...
3.14 浮点程序的机器级表示
没什么好说的, 直接照搬书了...
