一、贪婪模式
第一次贪婪模式,尽可能多的次数匹配,直到匹配失败。
当贪婪模式在匹配字符串的时候,如果不够最大次数的匹配,就会选择最小次数的匹配。
例:
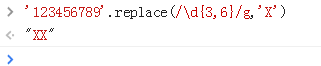
1、这个例子中由于设置了global,能匹配到 最大次6次,即 ' 123456 '替换成 "X",匹配到后面并不会停止而是会继续匹配,剩下的 " 789 "能被最小次3次匹配到,再次替换成 "X"
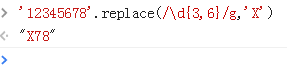
2、不够最小次数的匹配时会停止匹配
二、非贪婪模式?
非贪婪模式:让正则表达式尽可能少的匹配,也就是说一旦成功匹配就不再继续尝试
语法:在量词后加上?即可
例:
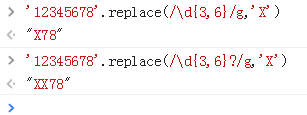
非贪婪模式中,进行次数少的匹配(3次),又因为设置的全局global,所以继续向后匹配。
"123"转化为X;"456"转换为X;"78"不足以匹配下一个三次,所以直接输出
三、分组()
分组:可以用来指定范围
语法:使用()可以达到分组的功能,使量词作用于分组
例:实现匹配字符串Byron连续出现3次的场景
Byron{3} 实现效果是 n重复了三次(量词作用于紧挨着它的字符)
使用分组

四、或 |
使用 | 表示或
例:(分组在或中的使用)
第一个表示匹配Byron 或是 Casper

五、反向引用$1~$n
用$1~$n代表捕获的分组也叫分组捕获
用$1$2$3捕获分组的内容。
想实现 2019-9-19转换为19/9/2019
例:
把分组内容捕获,捕获了之后用$1$2$3进行代替

六、忽略分组?:
不希望捕获某些分组,只需要在分组内加上 ?:
七、前瞻
正则表达式从文本头部向尾部开始解析,文本尾部方向,称为“前”
前瞻:就是在正则表达式匹配规则的时候,向前检查是否符合断言(文本尾部)
后瞻:也可以叫后顾,向后检查是否符合断言(文本头部)
符合特定断言称为肯定/正向匹配
不符合特定断言称为否定/负向匹配
- 正向前瞻 exp(?=assert)
- 负向前瞻 exp(?!=assert)
- 正向后顾 exp(?<=assert)
- 负向后顾 exp(?<!=assert)
例:正向前瞻
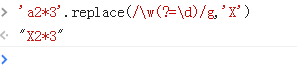
1、先是单词字符,然后再向前看看是不是数字
匹配的是单词(后面加上数字的单词)
w 等价于[a-zA-Z_0-9]含义是单词字符(字母、数字、下划线)
2 、3属于w,v也属于w,所以可以匹配
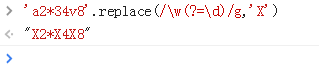
3、虽然匹配上了单词字符,但是“前”不是数字,所以不行
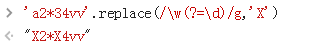
4、匹配单词字符但"前"不是数字

八、对象属性
- global 是否全文搜索,默认值 false
- ignore case 是否大小写敏感,默认值false
- multiline 多行搜索,默认值 false
- listIndex 表示执行下一次匹配时的起始位置
- source 正则表达式的文本字符串
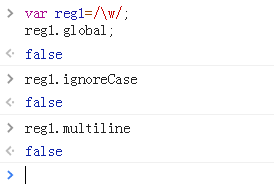
1、不进行设置,对象属性默认值都是false;
2、进行设置后,对象属性就变成了true
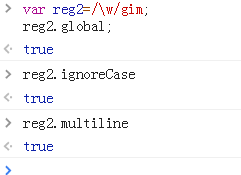
注意: 这几个属性都是只读的,不能对其进行设置。